


Redis消息队列
在程序员这个圈子打拼了太多年,见过太多的程序员使用redis,其中一部分喜欢把redis做缓存(cache)使用,其中最典型的当属存储用户session,除此之外,把redis作为消息队列使用也不在少数,可见redis在互联网中应用是多么的广泛。
redis作为消息队列使用,redis支持的数据结构是可以支撑这类业务,主要是利用了list这种数据结构的特性。Redis的列表相当于编程语言里面的 LinkedList,是一个双向的列表结构,这意味着列表新增和删除元素是非常快的,时间复杂度为O(1),但是查找一个元素的时候需要遍历列表,时间复杂度为O(n)。由于列表的元素操作和消息队列操作类似,所以redis可以适用于消息队列的场景,当然,在适用于的栈的场景下也可以胜任。
需要提醒一下,生产环境中如果对消息的可靠性有十分高的要求(比如订单支付的消费消息),请使用专业的消息队列(例如:rmq,amq等),对消息的丢失有一定容忍度的程序完全可以使用redis,例如我们的日志收集程序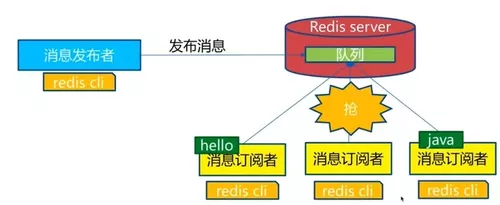
列表这种数据结构的命令为
移出并获取列表的第一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。
BLPOP key1 [key2 ] timeout
移出并获取列表的最后一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。
BRPOP key1 [key2 ] timeout
从列表中弹出一个值,将弹出的元素插入到另外一个列表中并返回它;如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。
BRPOPLPUSH source destination timeout
通过索引获取列表中的元素
LINDEX key index
在列表的元素前或者后插入元素
LINSERT key BEFORE|AFTER pivot value
获取列表长度
LLEN key
移出并获取列表的第一个元素
LPOP key
将一个或多个值插入到列表头部
LPUSH key value1 [value2]
将一个值插入到已存在的列表头部
LPUSHX key value
获取列表指定范围内的元素
LRANGE key start stop
移除列表元素
LREM key count value
通过索引设置列表元素的值
LSET key index value
对一个列表进行修剪(trim),就是说,让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除。
LTRIM key start stop
移除列表的最后一个元素,返回值为移除的元素。
RPOP key
移除列表的最后一个元素,并将该元素添加到另一个列表并返回
RPOPLPUSH source destination
在列表中添加一个或多个值
RPUSH key value1 [value2]
为已存在的列表添加值
RPUSHX key value
缺陷
消息队列的本质还是消费者和生产者的问题,只要是这样的场景,就会涉及到两端不平衡的情况,具体可表现为:
1. 生产者生产速度大于消费者消费速度,面临消息不断堆积的问题,随着消息数据的堆积,队列是开启限流措施,还是丢弃某些消息,更或者是把消息数据进行持久化。对于基于redis实现的消息队列,一般为可忍受部分消息丢失的业务,所以很多人选择丢弃消息的方案。另一种方案是基于redis单线程机制,可以增加消费者数量,这也是仅仅针对消息只被消费一次的场景。当然也可以选择持久化方案,但是会对redis的性能产生影响。
2. 消费者消费速度大于生产者生产速度,有的同学会说,这样挺好啊,是,在某种意义上是比反过来的那个场景要好一些,毕竟可以避免产生消息的堆积问题。但是消费者没有消息消费,会导致消费者进程一直在那里浪费cpu资源,而且还会把redis的QPS拉高。类似于这种死循环的场景,一般而且最常用的解决方案是让线程sleep 一小段时间,既降低了消费端cpu也降低了redis的QPS。但是sleep会有一个问题,会导致处理消息的延迟,例如sleep了一秒,那消息的延迟处理就有可能会延迟一秒,虽然在大部分场景下这都不是什么问题,但是作为程序员怎么能不追求极致和完美呢?
关于消息延迟的问题,最暴力简单的方式就是增加消费客户端,这样可用多消费端交错的方式来缩小延迟的间隔,当然redis的设计者也考虑了这个问题,所有有了Blpop 命令
Redis Blpop 命令移出并获取列表的第一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。
redis 127.0.0.1:6379> BLPOP LIST1 LIST2 .. LISTN TIMEOUT
而且还可以设置超时自动返回,岂不是完美。但是还要顺便一句,redis的连接在空闲一段时间后,服务端可能会主动断开,Blpop命令会抛出异常,所以还要做好了重试或者其他策略为好。
3. 如果作为专业的消息队列,一个消息被多个不同的业务消费(一个消息被消费多次)是必须要支持的,但是redis是基于自己的list数据结构来实现的伪队列,所以这种业务场景下就不要考虑redis了,或者自己封装一个类似分发器的中间件也可以。
4. 基于redis的消息队列没有Ack的保证,换句话说,一个消息是否被正常处理redis是不知道的,这在很大程度上限制了它的适用场景。
写在最后我还是建议不要用redis做专业的MQ使用,毕竟MQ这种场景不是redis的设计初衷,但是太多人把redis做MQ使用,于是redis的作者基于redis的核心代码实现了一个消息队列:disque,也许未来会作为redis的核心组件,地址为https://github.com/antirez/disque
除了disque,Redis Stream也是一个把redis作为MQ的比较好的解决方案,有兴趣的同学可以研究一下。
千万不要把任何一个业务场景想象的太简单共同学习,写下你的评论
评论加载中...
作者其他优质文章


