

既然是大数据无论存储和处理都需要相当大的磁盘或者是处理的资源消耗,那么单机肯定是满足不了我们的需求的,所以本节我们就来了解Hadoop的集群模式搭建,在集群情况下一同配合处理任务分发,存储分担等相关的功能进行实践.
附上:
Hadoop的官网:hadoop.apache.org
喵了个咪的博客:w-blog.cn
1.准备工作
安装包清单
统一存放到**/app/install**目录下,暂时只用存放到hadoop-1上,配置好了之后scp到slave节点上
jdk-8u101-linux-x64.tar.gz
hadoop-2.7.3.tar.gz
服务器环境
服务器系统使用centos7.X 64位版本
# hadoop-1 192.168.1.101
# hadoop-2 192.168.1.102
# hadoop-3 192.168.1.103
创建install目录存放各项包,使用oneinstack更新基础组件
> mkdir -p /app/install && cd /app/install
# 使用oneinstack更新一下环境基础组件 全部选择N即可
> wget http://mirrors.linuxeye.com/oneinstack-full.tar.gz
> tar -zxvf oneinstack-full.tar.gz
> cd oneinstack && ./install.sh
关闭各个节点防火墙(hadoop各个端口通讯会被拦截)或者是下面配置的一些端口全部加入到白名单中
> systemctl stop firewalld.service # 关闭firewall
> systemctl disable firewalld.service # 禁止firewall开机启动
分别修改服务器的主机名
# 最后主机名会全小写状态显示
> hostnamectl set-hostname hadoop-1
> hostnamectl set-hostname hadoop-2
> hostnamectl set-hostname hadoop-3
修改服务器的host(方便互相连通是的时候使用hostname)
> vim /etc/hosts
192.168.1.101 hadoop-1
192.168.1.102 hadoop-2
192.168.1.103 hadoop-3
重启服务器使其修改生效,重启完成后会发现主机名已经改回来了,然后使用ping命令检查是否可以互相连通
> ping hadoop-1
> ping hadoop-2
> ping hadoop-3
为所有集群节点创建hadoop用户(如果暴露外网IP务必使用复杂密码避免攻击)
> useradd -m hadoop -s /bin/bash
> passwd hadoop
为 hadoop 用户增加管理员权限,可以使用sudo来以root权限来进行操作
> visudo
# 找到root复制一条改为hadoop
root ALL=(ALL) ALL
hadoop ALL=(ALL) ALL
给hadoop-1添加SHH免密登录(hadoop-1 是我们的master主机)
# 先切换到hadoop用户
> su hadoop
> ssh-keygen -t rsa # 会有提示,都按回车就可以
> cd ~/.ssh/
> cat id_rsa.pub >> authorized_keys # 加入授权
> chmod 600 ./authorized_keys # 修改文件权限
> ssh localhost # 此时使用ssh首次需要yes以下不用密码即可登录
让hadoop-1可以免密码登录到hadoop-2和hadoop-3
在2和3上执行
> su hadoop
> ssh-keygen -t rsa
在hadoop-1上执行
> scp ~/.ssh/authorized_keys hadoop@hadoop-2:/home/hadoop/.ssh/
> scp ~/.ssh/authorized_keys hadoop@hadoop-3:/home/hadoop/.ssh/
此时就可以使用如下命令通过hadoop1号登录2和3
> ssh hadoop-2
> ssh hadoop-3
2.配置集群
Java环境
首先需要在每台服务器上配置好java环境
> cd /app/install
> sudo tar -zxvf jdk-8u101-linux-x64.tar.gz
> sudo mv jdk1.8.0_101/ /usr/local/jdk1.8
> scp /app/install/jdk-8u101-linux-x64.tar.gz hadoop@hadoop-2:~
> scp /app/install/jdk-8u101-linux-x64.tar.gz hadoop@hadoop-3:~
在hadoop-2 和 hadoop-3 上以root的身份执行
> sudo mv ~/jdk-8u101-linux-x64.tar.gz /app/install
> cd /app/install
> sudo tar -zxvf jdk-8u101-linux-x64.tar.gz
> sudo mv jdk1.8.0_101/ /usr/local/jdk1.8
所有节点环境变量增加如下内容
> sudo vim /etc/profile
# java
export JAVA_HOME=/usr/local/jdk1.8
export JRE_HOME=/usr/local/jdk1.8/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$PATH
# 使环境变量生效
> source /etc/profile
如下结果为安装成功
> java -version
java version "1.8.0_101"
Java(TM) SE Runtime Environment (build 1.8.0_101-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.101-b13, mixed mode)
Hadoop环境
首先在hadoop-1上准备hadoop环境
> cd /app/install
> sudo tar -zxvf hadoop-2.7.3.tar.gz
> sudo mv hadoop-2.7.3 /usr/local/
> sudo chown -R hadoop:hadoop /usr/local/hadoop-2.7.3
所有节点环境变量增加如下内容
> sudo vim /etc/profile
# hadoop
export HADOOP_HOME=/usr/local/hadoop-2.7.3
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
# 使环境变量生效
> source /etc/profile
配置Hadoop集群
集群/分布式模式需要修改 /usr/local/hadoop-2.7.3/etc/hadoop 中的6个配置文件,更多设置项可点击查看官方说明,这里仅设置了正常启动所必须的设置项:vim hadoop-env.sh 、 slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml 。
1.修改hadoop-env.sh中的JAVA环境变量
> vim /usr/local/hadoop-2.7.3/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8
1, 文件 slaves,将作为 DataNode 的主机名写入该文件,每行一个,默认为 localhost,所以在伪分布式配置时,节点即作为 NameNode 也作为 DataNode。分布式配置可以保留 localhost,也可以删掉,让 hadoop-1 节点仅作为 NameNode 使用。
本教程让 Master 节点仅作为 NameNode 使用,因此将文件中原来的 localhost 删除,只添加如下内容。
> vim /usr/local/hadoop-2.7.3/etc/hadoop/slaves
hadoop-2
hadoop-3
2, 文件 core-site.xml 改为下面的配置:
> vim /usr/local/hadoop-2.7.3/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop-2.7.3/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
3, 文件 hdfs-site.xml,dfs.replication 一般设为 3,但我们只有两个 Slave 节点,所以 dfs.replication 的值还是设为 2:
NameNode:管理文件系统的元数据,所有的数据读取工作都会先经过NameNode获取源数据在哪个DataNode里面在进行获取操作
DataNode:实际数据存储节点,具体的映射关系会存储在NameNode下
replication:复制因子,HDFS还有一个重要功能就是复制,当磁盘损坏的时候HDFS的数据并不会丢掉,可以理解为冗余备份机制
这里和单机模式不同的是需要配置NameNode的调用地址,DataNode节点才能连接上
> vim /usr/local/hadoop-2.7.3/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop-1:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop-2.7.3/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop-2.7.3/tmp/dfs/data</value>
</property>
</configuration>
4, 文件 mapred-site.xml (可能需要先重命名,默认文件名为 mapred-site.xml.template),然后配置修改如下:
> mv /usr/local/hadoop-2.7.3/etc/hadoop/mapred-site.xml.template /usr/local/hadoop-2.7.3/etc/hadoop/mapred-site.xml
> vim /usr/local/hadoop-2.7.3/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop-1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop-1:19888</value>
</property>
</configuration>
5, 文件 yarn-site.xml:
> vim /usr/local/hadoop-2.7.3/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
配置好后,将 Master 上的 /usr/local/Hadoop-2.7.3 文件夹复制到各个节点上。因为之前有跑过伪分布式模式,建议在切换到集群模式前先删除之前的临时文件。在 Master 节点上执行:
> scp -r /usr/local/hadoop-2.7.3 hadoop-2:/home/hadoop
> scp -r /usr/local/hadoop-2.7.3 hadoop-3:/home/hadoop
在 2和3节点上执行:
> sudo mv ~/hadoop-2.7.3 /usr/local
> sudo chown -R hadoop /usr/local/hadoop-2.7.3
首次启动和单机模式一样需要先在 Master 节点(hadoop1)执行 NameNode 的格式化:
> hdfs namenode -format
接着可以启动 hadoop 了,启动需要在 Master 节点上进行:
> start-dfs.sh
> start-yarn.sh
> mr-jobhistory-daemon.sh start historyserver
运行start-dfs.sh有如下提示
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
该警告通过如下方法消除了:
在hadoop-env.sh中 修改HADOOP_OPTS:
export HADOOP_OPTS="-Djava.library.path=$HADOOP_PREFIX/lib:$HADOOP_PREFIX/lib/native"
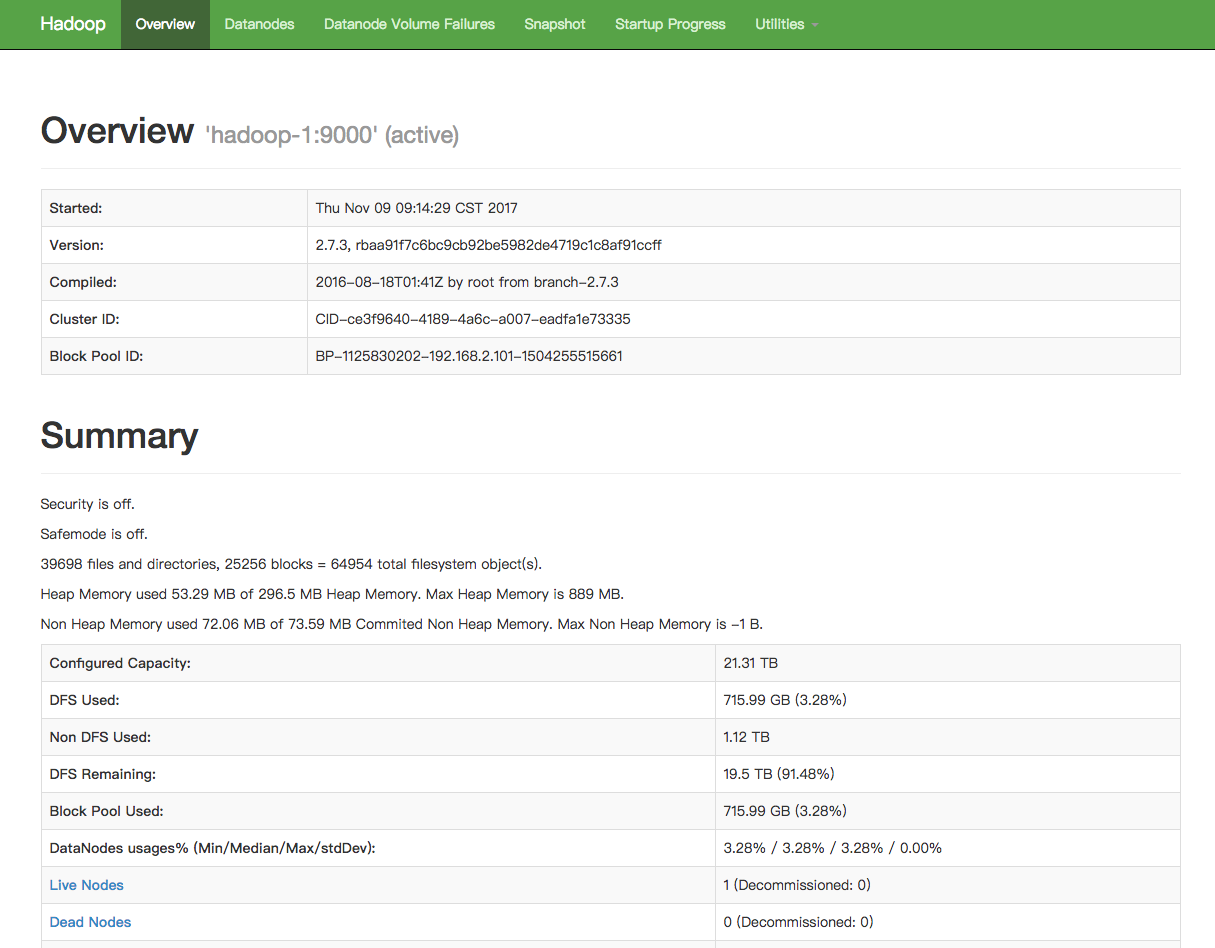
查看集群情况(关于磁盘占用,服务器状态等)
当整个集群运行起来之后可以通过hadoop-1:50070进行集群状态的查看和hdfs dfsadmin -report效果一样
> hdfs dfsadmin -report
如果不在需要使用可以使用如下命令关闭整个集群
> stop-yarn.sh
> stop-dfs.sh
> mr-jobhistory-daemon.sh stop historyserver
因为在环境变量中配置了**$HADOOP_HOME/sbin**也可以直接使用Hadoop快速启动快速关闭命令来对Hadoop整个集群启动或关闭
start-all.sh
stop-all.sh
3.集群模式下运行测试程序
执行集群任务执行过程与伪分布式模式一样,首先创建 HDFS 上的用户目录:
> hdfs dfs -mkdir -p /user/hadoop
将 /usr/local/hadoop-2.7.3/etc/hadoop 中的配置文件作为输入文件复制到分布式文件系统中:
> hdfs dfs -mkdir input
> hdfs dfs -put /usr/local/hadoop-2.7.3/etc/hadoop/*.xml input
> hdfs dfs -ls /user/hadoop/input
接着就可以运行 MapReduce 作业了:
> hadoop jar /usr/local/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar grep input output 'dfs[a-z.]+'
运行时的输出信息与伪分布式类似,会显示 Job 的进度。
可能会有点慢,但如果迟迟没有进度,比如 5 分钟都没看到进度,那不妨重启 Hadoop 再试试。若重启还不行,则很有可能是内存不足引起,建议增大虚拟机的内存,或者通过更改 YARN 的内存配置解决。
需要在所有集群中yarn-site.xml中增加
> vim /usr/local/hadoop-2.7.3/etc/hadoop/yarn-site.xml
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>20480</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
如果你使用的是阿里云的服务器这里有一个大坑,阿里云默认的host里面会写一些配置影响的hadoop正常运行,如下:
如果还是出现 failed on connection exception 异常运行不起来的情况可以去/etc/hosts中注释如下配置:
#127.0.0.1 localhost localhost.localdomain localhost4 localhost
#127.0.0.1 izbp1cvz54m4x8i9l5clyiz
#127.0.0.1 izbp1cvz54m4x8i9l5clyiz4.localdomain4
#::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
同样可以通过 Web 界面查看任务进度 hadoop-1:8088/cluster,在 Web 界面点击 “Tracking UI” 这一列的 History 连接,可以看到任务的运行信息,如下图所示:
查看处理结果
> hdfs dfs -cat output/*
4 总结
本节已经成功的在集群的情况下协调进行了任务的处理工作数据的存储工作,下一节中我们将讲到一些关于Hadoop维护相关的内容,最后多谢大家的支持欢迎大家一同交流!
注:笔者能力有限有说的不对的地方希望大家能够指出,也希望多多交流!
共同学习,写下你的评论
评论加载中...
作者其他优质文章



