

大数据互联网时代下大家耳熟能详的名词,但是我们离大数据有多远呢?从2011Hadoop1.0问世到现在,渐渐地大数据解决方案已经趋向成熟,笔者觉得也是时间来学习接触一下大数据解决一些在工作中实际遇到的一些棘手的问题,今天开始笔者会带来一整套亲生在大数据里面探索的经验已经一些实践经验来与大家一同分享学习.
附上:
喵了个咪的博客:w-blog.cn
1.什么是大数据,为什么需要大数据
大家可以一起来思考这个问题:什么是大数据?存储的数据很多就是大数据吗? 10TB 1PB?
其实不然,我们通过Hadoop其中的各个组件就可以了解到,大数据并不只是数据量大而已,它是数据存储+分布式调度+数据分析的结合:
- 数据存储 : Hadoop-HDFS — 用户高可靠性的来存储原始数据
- 分布式调度 : Hadoop-YARN — 用户分布式任务调度管理分配任务
- 数据分析 : Hadoop-MapReduce — 任务处理分析引擎
不知道大家是否还记得马云在杭州峰会上说你们知道全国哪个省的女人胸最小吗?他说他知道,但是实际上他真的就对比过吗?并不是这就是大数据技术实现的
大数据可以存放原来不敢想的数据,比如大量的请求日志,大量的操作日志,之前我们使用的数据能够存储1TB的容量千万基本条数据基本已经是极限了更别说分析了,大数据能够做到TB甚至PB级别的数据存储,还能在其中进行分析,举几个例子大家就很好理解:
- 有多少人每天中午吃中餐外卖?
- 购买衣服用户购买最多的颜色和尺码是什么?
- 上海那个地方的人流量最多最适合投放广告?
上面的每一个结果都需要通过大量的数据来分析出来,大数据就是起到这个作用最终来实现数据价值就是大数据的最终目标!
2.大数据生态
为什么这个时间段来说大数据呢?大数据不是已经很多年了吗? 现在在来说大数据是不是太晚了?
笔者觉得这个时间一点也不晚,马云说未来10年是大数据和人工智能的十年,尤其经过的一段时间的发展完善,之前少数人能够使用的大数据已经变得更加大众化了拥有了自己的生态,让使用者入门成本大幅降低,让普通开发者和小企业也可以能够比较轻松的接入到自己的业务中,其中有一些生态中大家耳熟能详的代表:
- Hadoop : 生态中的老大,提供了大数据的基础HDFS分布式文件系统以及YARN任务调度和MapReduce处理引擎
- Hive : 基于Hadoop的一个数据仓库工具,结构化的数据文件映射为一张数据库表,使用SQL语句的查询方式大大降低了需要编写MapReduce难度(复杂的语句会转换为MapReduce执行也可以使用其他引擎)
- Pig : 一种轻量级脚本语言可以很方便的在HDFS上进行各项操作,可以操作结构化,半结构化,非结构化数据,和Hive相比Hive只能操作结构化数据
- Hbase : 一个NoSql的数据库,Hbase的数据操作基本可以做到实时,比如一些短链接很大一部分使用Hbase来存储
- KafKa : 高吞吐量的分布式发布订阅消息系统,用于海量日志的传输较多
- Spark : 使用scala开发大规模数据处理而设计的快速通用的计算引擎,和MapReduce不同Spark使用内存分布数据集,内存计算下,Spark 比 Hadoop 快100倍.
- Storm : 实时计算系统,俗称流处理引擎实时分析,在线机器学习,持续计算,分布式远程调用和ETL使用较多
- Sqoop : 数据导入导出工具,可以用于Hadoop(Hive)与传统的数据库(mysql、postgresql…)间数据互相传递
- Presto : Facebook开发的数据查询引擎,可以与Hive和关系型数据库结合,实现直接的关联查询等
大数据生态中还有很多其他的生态组件这里就不一一列举.
3.大数据解决方案
既然要说大数据肯定要有具体的场景,笔者这里的场景是对所有服务器的访问日志进行记录,最终达到通过操作日志对用户行为数据分析,大致流程如下:
(有的童鞋说为什么一定要用大数据来分析呢? 直接业务汇总也可以啊! 大家要注意通过大数据分析原始数据都是存在的可以通过多个维度进行分析不局限,而业务汇总往往只是一个总数已经丢失了所有的维度,如果统一有误直接影响数据结构,而大数据只要改一下查询的方式就好了)
来自一份日志的生命周期
- 通过业务服务器接口请求分别进行业务处理到数据库并且写入到日志系统中,filebeat读取日志文件把数据发送到KafKa中
- 日志暂时存在KafKa中,分别被storm和Go程序消费(笔者后期会开源),storm试试计算处理到mysql库和hive库中
- Go程序会提前建立好Hive和Hbase中的表结构(按照每天分表),Go收到数据会进行配置的规则解析并且写入数据到Hbase中
- Hbase和Hive进关联,并且每天定时对数据进行汇总分区,最终日志会存放到Hadoop-HDFS中
- Sqoop会把Mysql的数据同步到HIVE库中,Spark对数据进行离线分析得到需要的结构存入HIVE,Sqoop吧处理的数据在同步会Mysql
- 使用Presto对数据进行实时查询检索
(未经过作者允许请不要善自使用图片)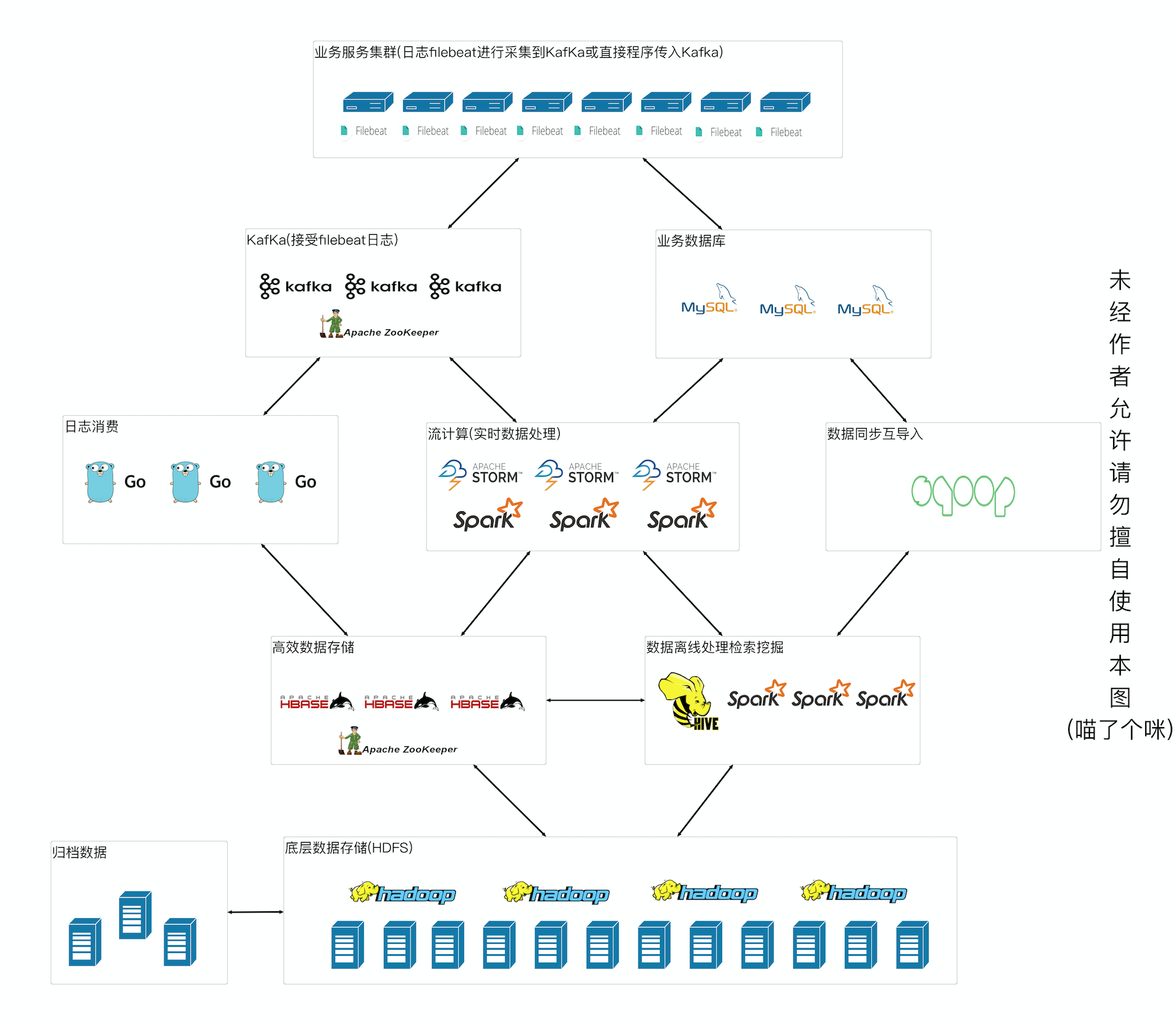
猫咪后续大致的一个大数据内容如下:
- [喵咪大数据]Hadoop单机模式
- [喵咪大数据]Hadoop集群模式
- [喵咪大数据]Hadoop节点添加下线和磁盘扩容操作
- [喵咪大数据]Hive2搭建
- [喵咪大数据]Hbase搭建
- [喵咪大数据]Hive+Hbase关联
- [喵咪大数据]HUE大数据可视化管理工具
- [喵咪大数据]Presto查询引擎
- [喵咪大数据]Airpal在线Presto管理工具
- [喵咪大数据]Spark集群搭建
- [喵咪大数据]Spark-SQL查询引擎
- [喵咪大数据]KafKa搭建配置
- [喵咪大数据]filebeat采集日志进入KafKa
- [喵咪大数据]sqoop数据导入导出(Mysql <-> Hive)
4 总结
大数据已经深入到各行各业无处不在,笔者也希望在子学习的过程中能够和大家一同分享学习收货知识一同成长,如果大家感兴趣请关注喵咪的博客,将给大家带来更多的精品博客,谢谢大家的支持!
注:笔者能力有限有说的不对的地方希望大家能够指出,也希望多多交流!
共同学习,写下你的评论
评论加载中...
作者其他优质文章



