
KubeSphere排错实战(二)
接上一篇《KubeSphere实战排除》近期在使用kubesphere中也记录了一些使用问题,希望可以对其他人有帮助
八 kubesphere应用上传问题
8.1 文件上传413
将应用部署进入kubesphere中,应用中有设置上传文件功能,测试上次异常无法正常上传,文件上传,ingress413报错,kubesphere使用的是ingress-nginx控制器,可以在其中注解添加k-v来支持,
解决方案:应用路由自定义max body size
8.2 大文件上传后端504
大文件上传后端响应504解决方案:
proxy read timeoutnginx.ingress.kubernetes.io/proxy-read-timeout
九 跨域问题
kubesphere使用ingress-nginx支持跨域,可以参考以下链接在注解中添加
测试环境可以使用可以使用hosts,将域名解析到本地,前端利用nginx来做静态文件服务,反向代理后端api,可以参考示例:
server {
listen 80;
server_name localhost;
# 强制https跳转
# rewrite ^(.*)$ https://$host$1 permanent;
location / {
index index.html;
root /smart-frontend;
try_files $uri $uri/ /index.html;
client_body_buffer_size 200m;
charset utf-8;
}
location /api {
proxy_pass http://smart-backend:8080/api;
proxy_read_timeout 1200;
client_max_body_size 1024m;
}
gzip on; #开启gzip
gzip_vary on;
gzip_min_length 1k; #不压缩临界值,大于1k的才压缩,一般不用改
gzip_buffers 4 16k;
gzip_comp_level 6; #压缩级别,数字越大压缩的越好
gzip_types text/plain application/javascript application/x-javascript text/css application/xml text/javascript application/x-httpd-php image/jpeg image/gif image/png image/x-icon;
}
十 添加节点
后期逐渐业务上来,集群节点资源不足,新增node节点,将node节点的数据盘添加到ceph节点
10.1 ceph集群添加节点
-
系统配置
-
免费密钥配置
-
hosts配置
-
docker安装并迁移至数据盘
-
cgroup启用
-
ceph数据节点添加
ceph集群配置添加node03集群的数据盘节点(如果数据存储类足够,可以不用添加数据节点)
[root@node03 docker]# mkfs.xfs /dev/vdd
[root@node03 docker]# mkdir -p /var/local/osd3
[root@node03 docker]# mount /dev/vdd /var/local/osd3/
添加vdd到/etc/fstab中
[root@node03 docker]# yum -y install yum-plugin-priorities epel-release
[root@node03 yum.repos.d]# chmod 777 -R /var/local/osd3/
[root@node03 yum.repos.d]# chmod 777 -R /var/local/osd3/* master节点利用ceph-deploy部署node03节点[root@master ceph]# ceph-deploy install node03
[root@master ceph]# ceph-deploy gatherkeys master
[root@master ceph]# ceph-deploy osd prepare node03:/var/local/osd3
- 激活osd
[root@master ceph]# ceph-deploy osd activate node03:/var/local/osd3
- 查看状态
[root@master ceph]# ceph-deploy osd list master node01 node02 node03
- 拷贝密钥
[root@master ceph]# ceph-deploy admin master node01 node02 node03
- 在node03节点设置权限
[root@node03 yum.repos.d]# chmod +r /etc/ceph/ceph.client.admin.keyring
- 在master设置MDS
[root@master ceph]# ceph-deploy mds create node01 node02 node03
- 查看状态
[root@master ceph]# ceph health
[root@master ceph]# ceph - 由于是新增node节点,数据需要平衡回填,此刻查看集群状态[root@master conf]# ceph -s
cluster 5b9eb8d2-1c12-4f6d-ae9c-85078795794b
health HEALTH_ERR
44 pgs backfill_wait
1 pgs backfilling
1 pgs inconsistent
45 pgs stuck unclean
recovery 1/55692 objects degraded (0.002%)
recovery 9756/55692 objects misplaced (17.518%)
2 scrub errors
monmap e1: 1 mons at {master=172.16.60.2:6789/0}
election epoch 35, quorum 0 master
osdmap e2234: 4 osds: 4 up, 4 in; 45 remapped pgs
flags sortbitwise,require_jewel_osds
pgmap v5721471: 192 pgs, 2 pools, 104 GB data, 27846 objects
230 GB used, 1768 GB / 1999 GB avail
1/55692 objects degraded (0.002%)
9756/55692 objects misplaced (17.518%)
146 active+clean
44 active+remapped+wait_backfill
1 active+remapped+backfilling
1 active+clean+inconsistent
recovery io 50492 kB/s, 13 objects/s
client io 20315 B/s wr, 0 op/s rd, 5 op/s wr
- 最终的问题,目前由于新增了node节点,新增ceph数据节点需要数据同步
[root@master conf]# ceph -s
cluster 5b9eb8d2-1c12-4f6d-ae9c-85078795794b
health HEALTH_ERR
1 pgs inconsistent
2 scrub errors
monmap e1: 1 mons at {master=172.16.60.2:6789/0}
election epoch 35, quorum 0 master
osdmap e2324: 4 osds: 4 up, 4 in
flags sortbitwise,require_jewel_osds
pgmap v5723479: 192 pgs, 2 pools, 104 GB data, 27848 objects
229 GB used, 1769 GB / 1999 GB avail
191 active+clean
1 active+clean+inconsistent
client io 78305 B/s wr, 0 op/s rd, 18 op/s wr修复[root@master conf]# ceph -s
cluster 5b9eb8d2-1c12-4f6d-ae9c-85078795794b
health HEALTH_OK
monmap e1: 1 mons at {master=172.16.60.2:6789/0}
election epoch 35, quorum 0 master
osdmap e2324: 4 osds: 4 up, 4 in
flags sortbitwise,require_jewel_osds
pgmap v5724320: 192 pgs, 2 pools, 104 GB data, 27848 objects
229 GB used, 1769 GB / 1999 GB avail
192 active+clean
client io 227 kB/s wr, 0 op/s rd, 7 op/s wr
# 同步完成
[root@master conf]# ceph health
HEALTH_OK
10.2 node节点添加
kubesphere为方便新增节点,提供了方便的脚步一键新增,可参考:https://kubesphere.com.cn/docs/v2.1/zh-CN/installation/add-nodes/
修改host.ini
master ansible_connection=local ip=172.16.60.2
node01 ansible_host=172.16.60.3 ip=172.16.60.3
node02 ansible_host=172.16.60.4 ip=172.16.60.4
node03 ansible_host=172.16.60.5 ip=172.16.60.5
[kube-master]
master
[kube-node]
master
node01
node02
node03
在 “/script” 目录执行 add-nodes.sh脚本。待扩容脚本执行成功后,即可看到包含新节点的集群节点信息,可通过 KubeSphere 控制台的菜单选择 基础设施 然后进入 主机管理 页面查看,或者通过 Kubectl 工具执行 kubectl get node命令,查看扩容后的集群节点详细信息。
[root@master scripts]# ./add-nodes.sh
查看验证
[root@master conf]# kubectl get nodes -owide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
master Ready master 136d v1.15.5 172.16.60.2 <none> CentOS Linux 7 (Core) 3.10.0-693.el7.x86_64 docker://18.6.2
node01 Ready node,worker 136d v1.15.5 172.16.60.3 <none> CentOS Linux 7 (Core) 3.10.0-693.el7.x86_64 docker://18.6.2
node02 Ready node,worker 136d v1.15.5 172.16.60.4 <none> CentOS Linux 7 (Core) 3.10.0-693.el7.x86_64 docker://18.6.2
node03 Ready worker 10m v1.15.5 172.16.60.5 <none> CentOS Linux 7 (Core) 3.10.0-693.el7.x86_64 docker://19.3.5
[root@master conf]# kubectl label node node-role.kubernetes.io/node=
common.yaml hosts.ini plugin-qingcloud.yaml
[root@master conf]# kubectl label node node03 node-role.kubernetes.io/node=
node/node03 labeled
[root@master conf]# kubectl get nodes -owide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
master Ready master 136d v1.15.5 172.16.60.2 <none> CentOS Linux 7 (Core) 3.10.0-693.el7.x86_64 docker://18.6.2
node01 Ready node,worker 136d v1.15.5 172.16.60.3 <none> CentOS Linux 7 (Core) 3.10.0-693.el7.x86_64 docker://18.6.2
node02 Ready node,worker 136d v1.15.5 172.16.60.4 <none> CentOS Linux 7 (Core) 3.10.0-693.el7.x86_64 docker://18.6.2
node03 Ready node,worker 11m v1.15.5 172.16.60.5 <none> CentOS Linux 7 (Core) 3.10.0-693.el7.x86_64 docker://19.3.5
[root@master conf]#
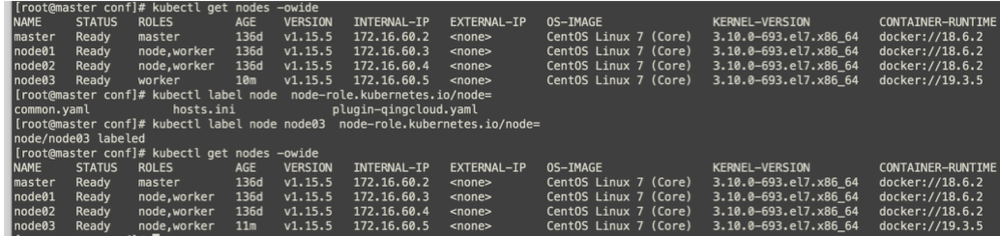
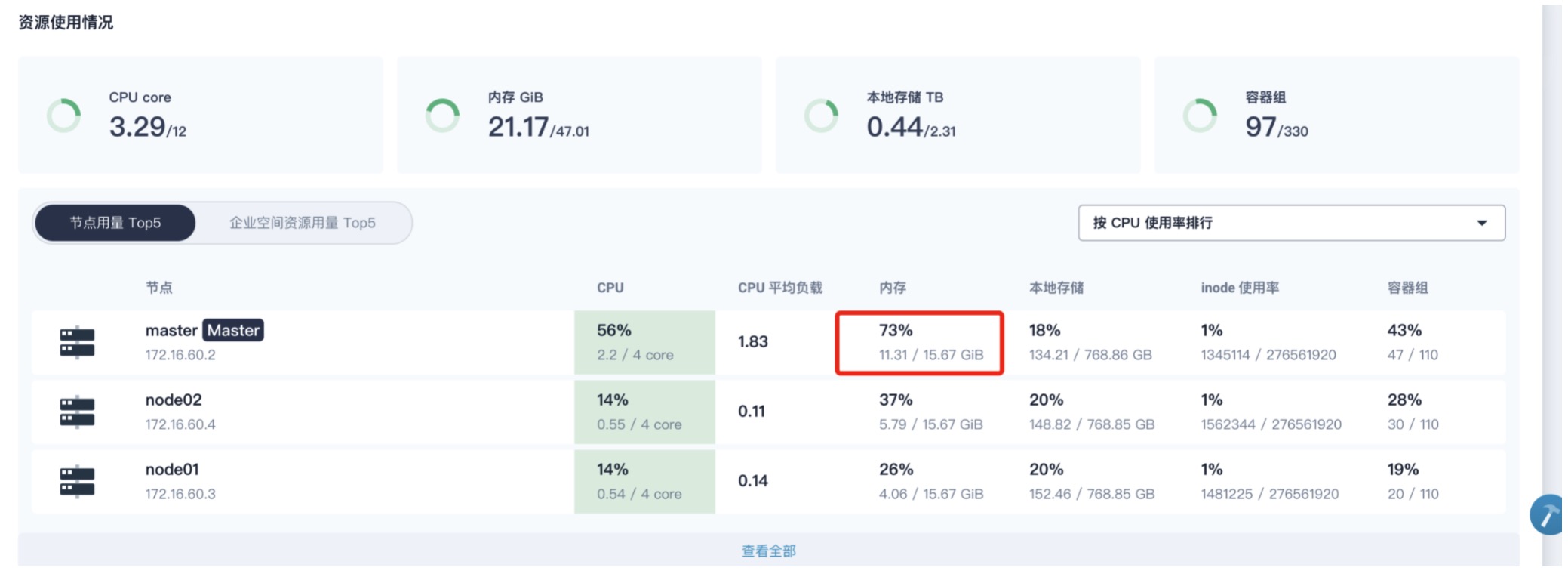
十一 K8s集群资源不均
可以发现k8s资源使用不均衡,之前的部署应用为制定nodeSelect,导致一些系统服务运行在node节点,查看node2内存占用很大,导致集群异常告警或重启
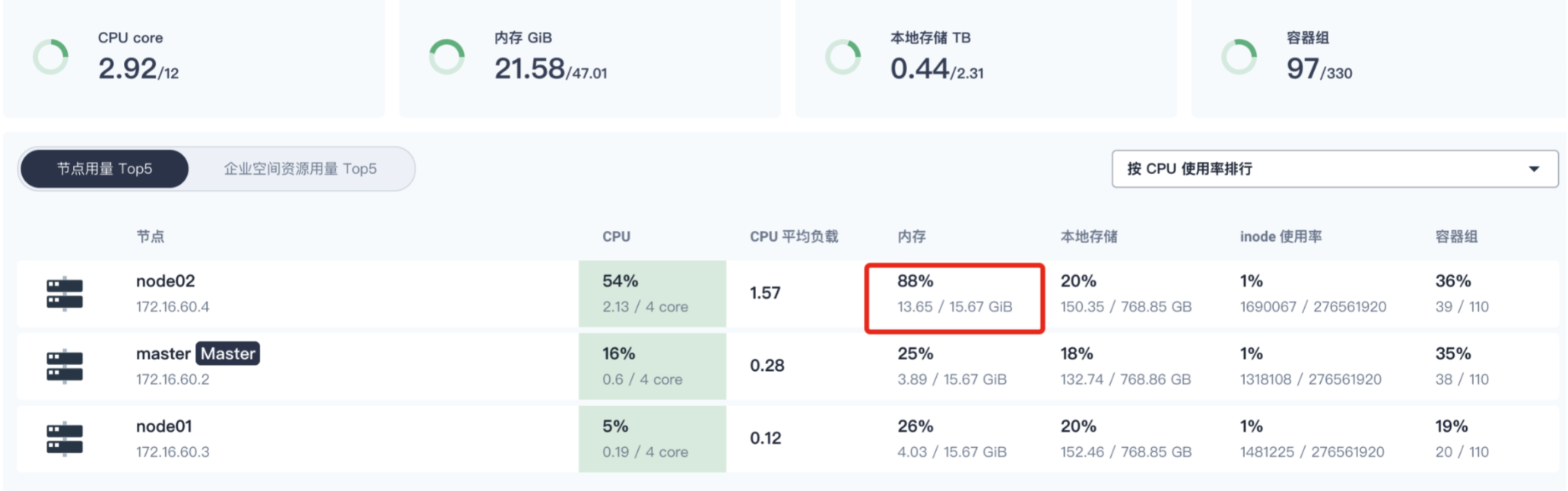
可以通过查看
kubectl get pods -o wide --all-namespaces |grep node02 |awk '{print $1, $2}'
将一些系统应用通过nodeselect来调度到master节点,以减轻node2节点的内存压力。
`kubectl get nodes --show-labels`
在node2上查看系统组建添加nodeselector来重新调度
nodeSelector:
node-role.kubernetes.io/master: master
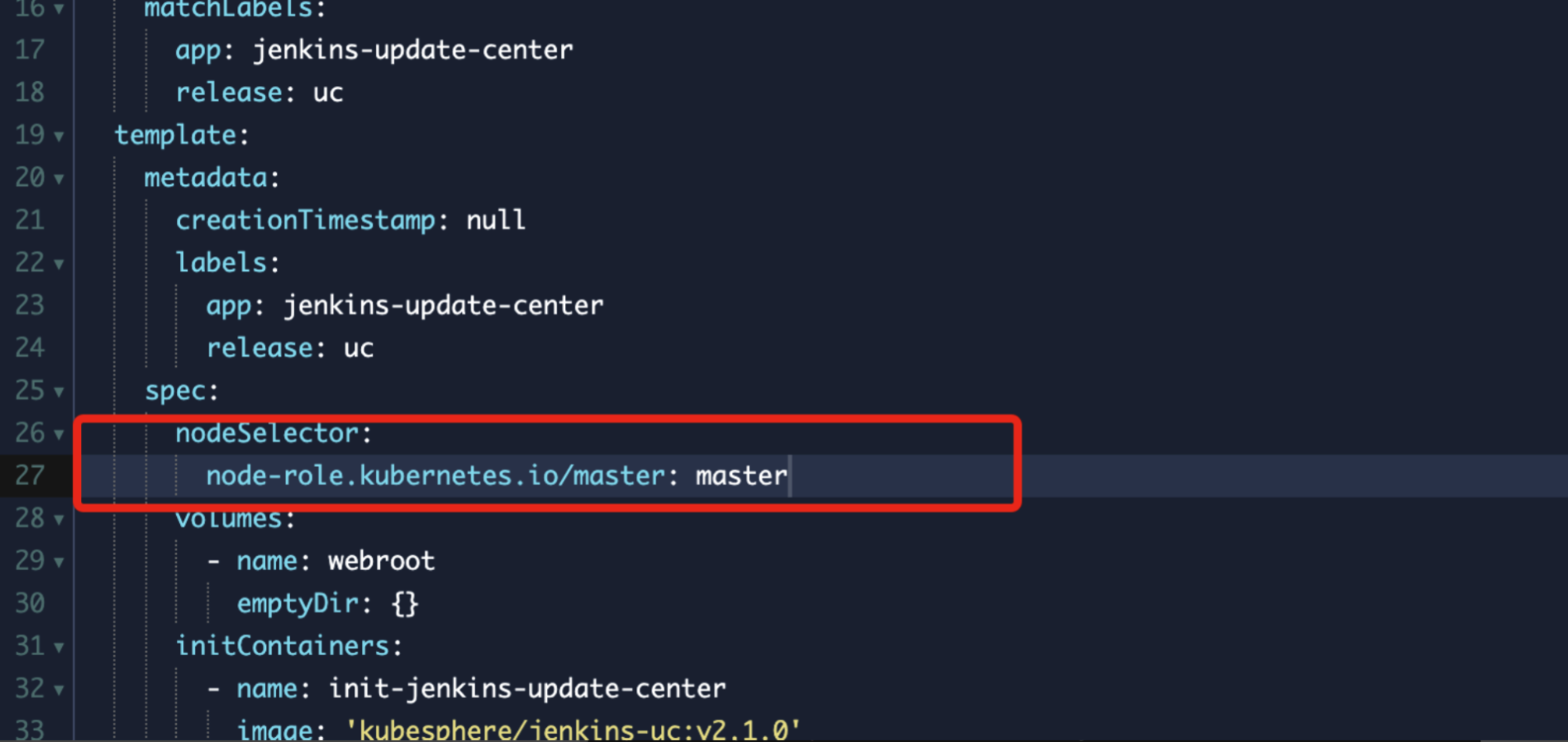
查看现存在node2上面的kubesphere系统deployment
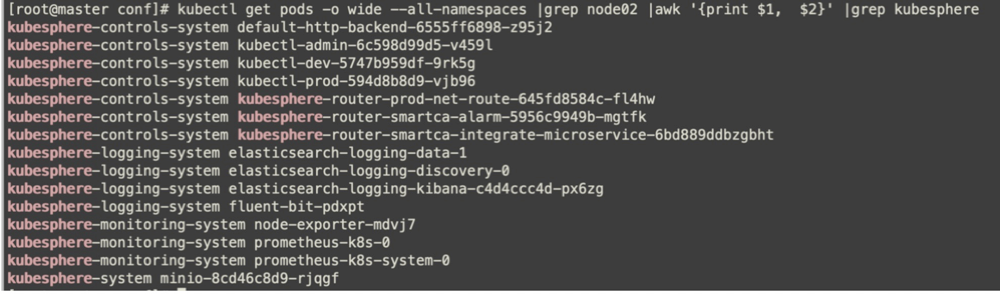
通过调度完成,查看node2的内存负载已经下来了
十二 kubesphere devops工程
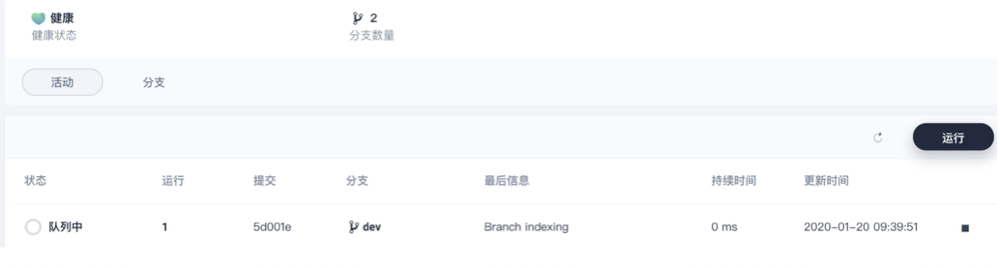
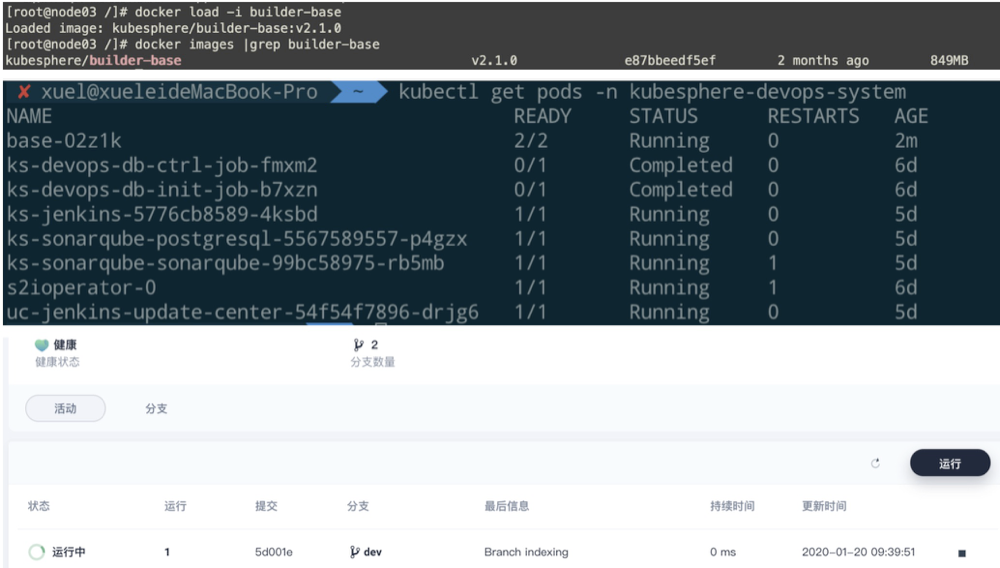
新增了node03节点,devops工程一周为队列中为此时运行该job的实例未完成初始化,登录集群查看,node03上的base pod在pull agent镜像,为了快速,直接在node节点,save base镜像然后在node03上load
[root@master ~]# kubectl describe pods -n kubesphere-devops-system $(kubectl get pods -n kubesphere-devops-system |grep -E "^base" |awk '{print $1}')
十三 kubesphere 应用安装
目前自己的kubesphere集群为2.1,在具体的在项目中添加了repo后,后台回自己去同步镜像数据还是需要为手动在那个地方触发下,我添加了几个helm 的repo,好像里面的chart没有在web界面显示,在添加了repo的项目下,我新建应用,然后选择来自kubesphere的应用商店,其中只有几个charts,发现不了添加的helm 源的chartscharts,在服务器内部是可以使用命令search到。咨询社区暂时为收到回复,记得v2.0版本后台有个任务会去同步charts,目前2.1版本,先使用helm命令在集群内进行手动helm安装
[root@master common-service]# helm install -n consul --namespace common-service -f consul/values-production.yaml consul/
NAME: consul
LAST DEPLOYED: Tue Jan 14 17:56:27 2020
NAMESPACE: common-service
STATUS: DEPLOYED
RESOURCES:
==> v1/Pod(related)
NAME READY STATUS RESTARTS AGE
consul-0 0/2 Pending 0 0s
==> v1/Service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
consul ClusterIP None <none> 8400/TCP,8301/TCP,8301/UDP,8300/TCP,8600/TCP,8600/UDP 1s
consul-ui ClusterIP 10.233.59.7 <none> 80/TCP 1s
==> v1/StatefulSet
NAME READY AGE
consul 0/3 0s
==> v1beta1/PodDisruptionBudget
NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE
consul-pdb 1 N/A 0 1s
NOTES:
** Please be patient while the chart is being deployed **
Consul can be accessed within the cluster on port 8300 at consul.common-service.svc.cluster.local
In order to access to the Consul Web UI:
kubectl port-forward --namespace common-service svc/consul-ui 80:80
echo "Consul URL: http://127.0.0.1:80"
Please take into account that you need to wait until a cluster leader is elected before using the Consul Web UI.
In order to check the status of the cluster you can run the following command:
kubectl exec -it consul-0 -- consul members
Furthermore, to know which Consul node is the cluster leader run this other command:
kubectl exec -it consul-0 -- consul operator raf

共同学习,写下你的评论
评论加载中...
作者其他优质文章



