
个人经历:低不成,高不就
依稀还记得15年刚出来工作那会,在第一个互联网公司实习,在公司听惯了身边人说公司这不好,那不好,作为新人的我深受影响,不知从何时开始就想快点结束实习期换一份更好的工作;
千盼万盼,终于迎来第二年的毕业,毕业后我也选择了大部分实习生的选择,没有再回到公司,在之后,懵懂的我终于迎来人生的第一次打击,在之后的两个月的时间,我开始在做比较,结果没有找到一家比上家更好的工作,由于当初的不辞而别,我也感觉没脸回到上家公司,终于到了身无分文的地步,而我也不得以选择一家“差”的公司,想着做几个月存点钱再去找一份更好的工作;
这样的恶性循环在我身上循环了一年,“低不成,高不就”的现象也许不只是出现在我身上,下面教你如果找到一份自己相对满意的工作!

正文:找一份自己满意的工作
拿一个招聘网站用来分析:
1、分析网站结构,确定我们要抓取的数据内容
通过 Chrome 浏览器右键检查查看 network 并对网站结构进行分析发现我们在 ajax 请求界面中,可以看到这些返回的数据正是网站页面中Python岗位招聘的详情信息。
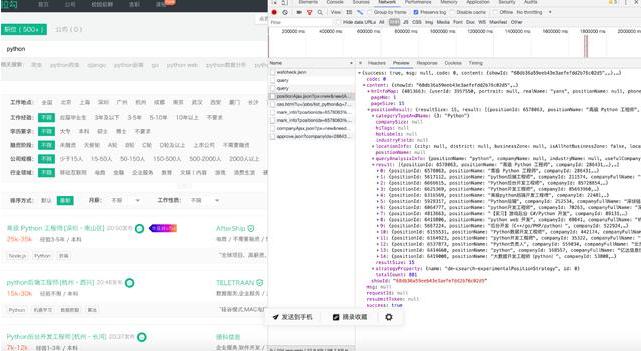
之后我们在查看headers的时候发现该网站请求的方式是Post请求,也就是说在请求的过程中需要携带Form Data数据
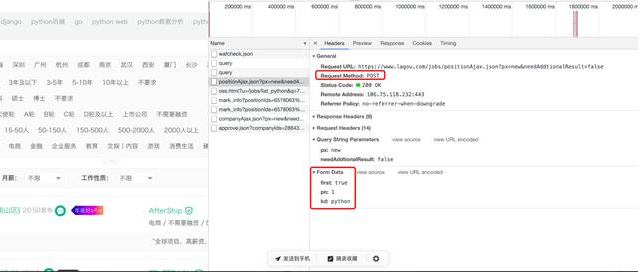
在多次对网页界面进行分析评测的时候,发现在点击第二页的时候Form Data的携带格式发生了变化。可以看到 pn=2 肯定是咱们的当前的页数。
2、不管三七二十一 ,先请求拿到数据在说
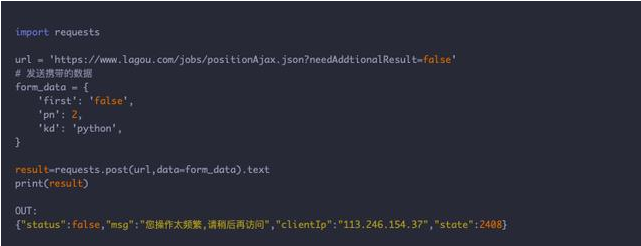
在直接请求界面的时候我们发现网站有反爬机制,不让我们请求《“msg”:“您操作太频繁,请稍后再访问”》,我们携带请求头伪装一下,不行
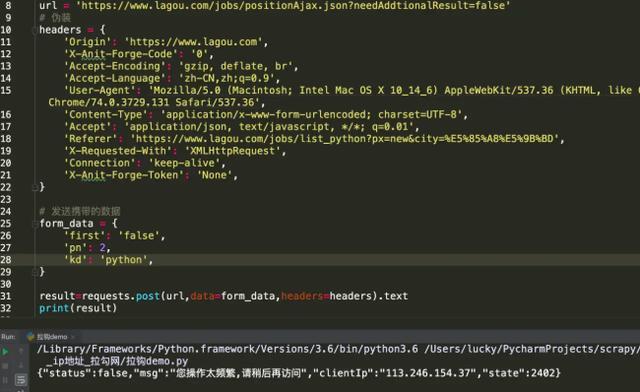
这里我用了一种可以快速生成headers以及cookie的工具:
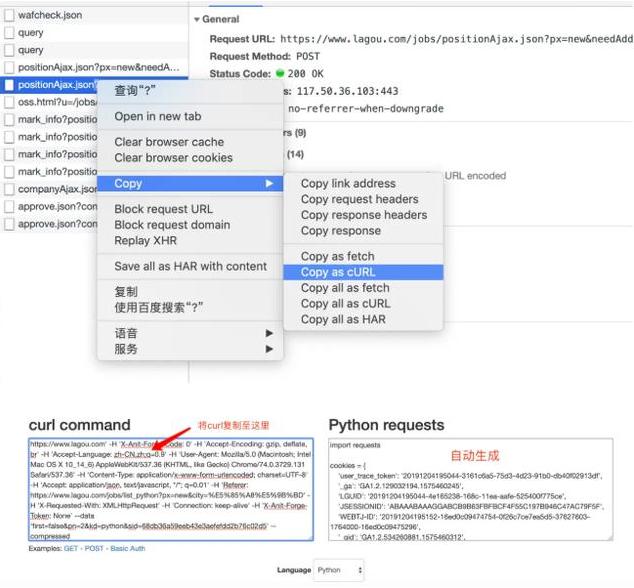
我怀疑该网站具有多重反爬策略,当我在次添加cookies试一下的时候;我们发现数据可以正常获取了;难道就这么简单就解决拉勾网数据获取的问题了吗?然而机智的我察觉到事情并没有想像的那么简单;
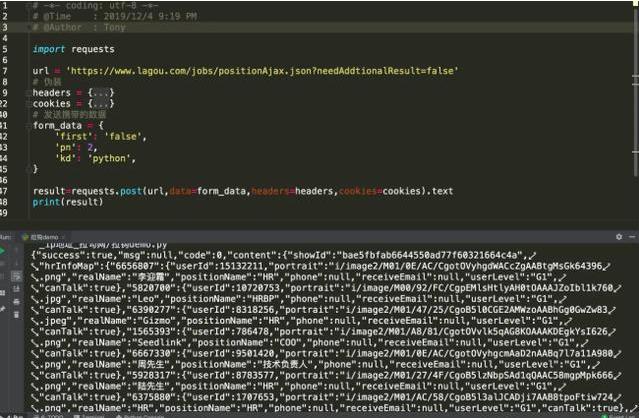
我的最终解决方案是共用 session,就是说我们在每次请求界面的时候先获取session然后原地更新我们的session之后在进行数据的抓取,最后拿到想要的数据。
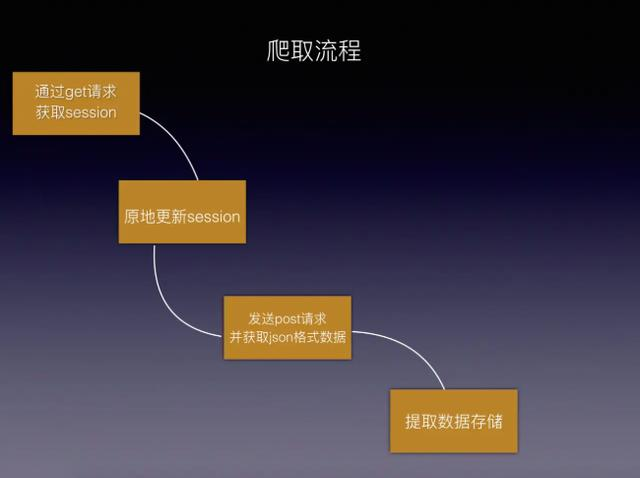
第二步:对数据进行分解
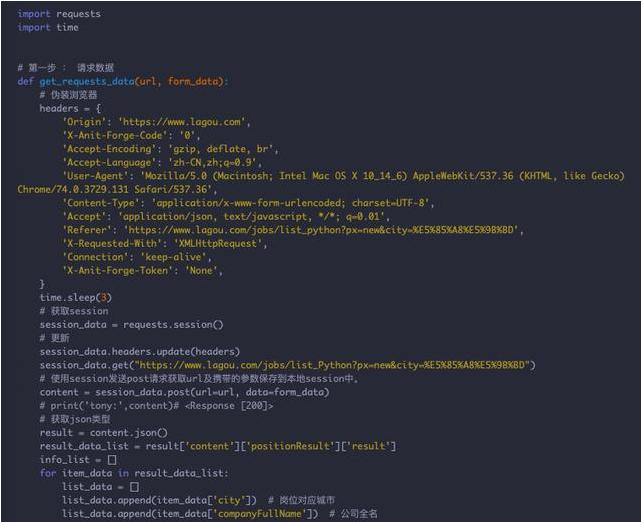
运行结果:
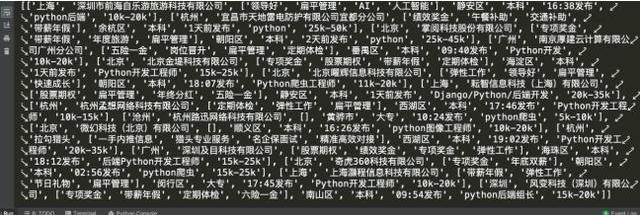
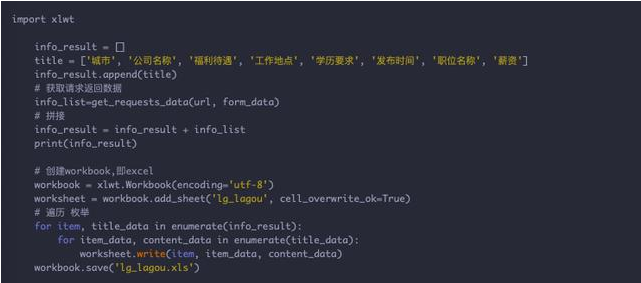
第三步:对解析数据进行存储
这里通过 excel 表格的形式进行存储;
需要 pip install xlwt 安装一下 xlwt 库.
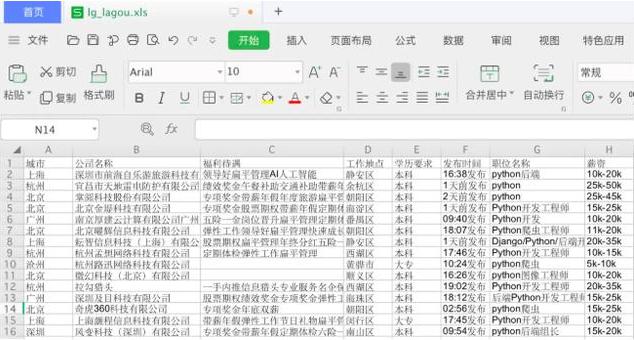
最终显示数据内容
最后
如果需要源码,可以看下图
点击了解更多,获取更多Python爬虫全栈学习资料
共同学习,写下你的评论
评论加载中...
作者其他优质文章



