
插播一条新闻,为什么要插播,嗯不知道可能今天心情比较好,毕竟中秋了嘛~
今天跟小伙伴们聊聊另外一个统计算法, Roaring BitMaps。
这个改怎么翻译呢??咆哮的位图?s?我翻译不出来,但是小蕉头一歪,就给它起了一个狂拽酷霸叼扎天的翻译 -> 咆哮吧,位图君们。
来了喔。
根据官方统计,已经有这么多大项目在用Roaring BitMaps了,老牛逼了。
Apache Lucene and derivative systems such as Solr and Elasticsearch,
Metamarkets’ Druid,
Apache Spark,
Apache Hive,
Apache Tez,
Netflix Atlas,
LinkedIn Pinot,
OpenSearchServer,
Cloud Torrent,
Whoosh,
Pilosa,
Microsoft Visual Studio Team Services (VSTS),
Jive Miru,
eBay’s Apache Kylin.
那么勤劳又聪明的你一定会问了,这是什么东西?用来干啥的?怎么用的?从用途来看,Roaring BitMaps 就是一个用来进行基数统计的算法。
用途有三只:
第一只当然就是基数统计啦,count之类的,可节省空间了。
第二只呢,数据库在执行Join的时候,要知道Join之前是多少量级,Join完又是什么量级,再执行相应的优化策略。
第三只呢,是作为索引存在,可以作为数据库判断唯一索引的唯一性。
等等。
关于这个算法呢,也不是什么非常难的东西,原始论文其实讲得蛮详细的了,看看原始论文一般就能看懂了。但小蕉在这里,其实用三句话就可以把这个算法说清楚了。
1、把n长的区间划分为2^16个桶(n为Roaring BitMaps 的总长度),每个桶放一个Container,作为一级索引存在。
2、每个int数值k为32位的bit,我们取前16位找到对应的桶(k % 2^16),Container里面只保存后16位 (k mod 2^16) 。若Container为BitMap,直接把第 (k mod 2^16) 位设置为1即可,若Container为Array,则用二分查找插入法,有序插入。
3、若一个Container里面的Integer数量小于4096,就用Short类型的有序数组来存储值。若大于4096,就用BitMap来存储值。数据用来放稀疏的数据,BitMap用来放紧密的数据(至于为啥,请重新看BitMap的定义及使用范围)。
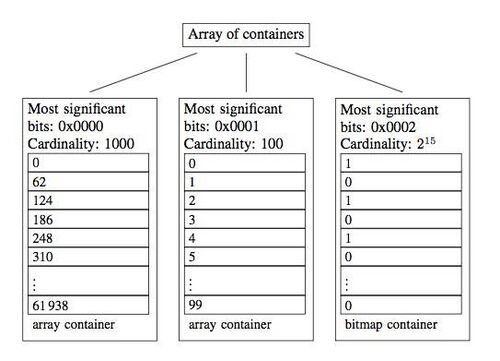
实际使用的时候怎么找到值呢?跟原来插入值一样,因为Containers是有序的嘛,也有自己的数据范围,所以首先用二分查找找到数据对应的Container。然后分两种情况,如果是Container是数组,就再用一次二分查找。如果Container是BitMap,直接找到对应的位是不是1就行了。
好啦,算法方面就这样说完了,但是又有小朋友要问了,那这样存储完有什么用呢?只需要定义三种操作,AND,OR,NOT,就可以快速进行两个集合的操作了。
因为Container有两种,BitMap和Array ,所以进行合并操作的时候会有三种情况。
1、Array vs Array
2、Array vs BitMap
3、BitMap vs BitMap
分别是怎么处理呢,下面所说的操作指的你所希望的功能是AND、OR、还是NOT?选一种操作进行计算就行了。
Array vs Array ,直接用算法merge成一个数组,再进行相应的操作即可。
Array vs BitMap,遍历一下Array,把它的值一个一个映射到BitMap上并操作,最终统计一下BitMap即可。
BitMap vs BitMap,直接按位操作即可。
实际实现的时候,不仅仅会有Short类型的Array,拓展开可以是任何基础数据类型的Array,功能越来越丰富了。
关于论文和Github地址,后台直接回复 Roaring 可以获取到。
沉迷学习,日渐消瘦。大家如果有什么健身、Java入门、大数据、机器学习入门方面的问题也可以问我,我看到会回的,有什么想看的想听的也可以告诉我,我会把放入我的需求池的,啊哈哈哈哈哈。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



