

小姐姐味道【ID:xjjdog】
作者:十年架构,日百亿流量经验,与你分享。
宝剑锋从磨砺出,梅花香自苦寒来。
诗人白居易,三月下江南,看到沿路开放的桃花,心潮澎湃,作下了这首流传千秋的诗。表现了诗人对美好事物的向往,以及对其背后苦情的感慨。算了…我编不下去了。
前半句还好,是因果关系。但诗的后半句,却狗屁不通,典型的从结果找原因的思路。哪怕改成“狗屎臭自菊花来”,也比这通畅的多。
这就是理论和实践的区别,只靠臆想,是撑不起现实的骨感的。
本篇文章,将会介绍一个常见的、烂大街的elkb方案,并附赠一套精致的配置文件,以便减少重复工作。
ELKkB
不久之前,elkb还是叫elk。beats系列是最近几年才发展起来的,目的是为了替换flume等收集组件。但为了让这个过程更加平滑具有扩展性,一般会加入一个叫做kafka的组件。所以整体看起来是这样的。
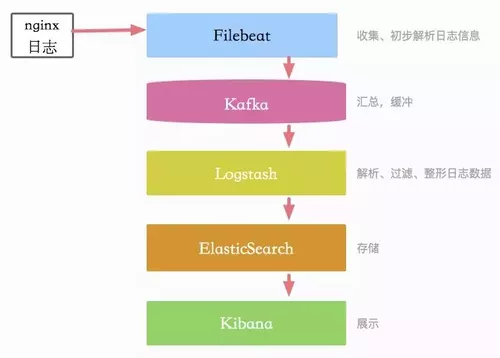
简单点评一下几个组件。
1)filebeat。用于收集日志组件,经测试其使用简单,占用资源比flume更少。但是对资源的占用不是那么智能,需要调整一些参数。filebeat会同时耗费内存和cpu资源,需要小心。
2)kafka。流行的消息队列,在日志收集里有存储+缓冲的功能。kafka的topic过多,会有严重的性能问题,所以需要对收集的信息进行归类。更进一步,直接划分不同的kafka集群。kafka对cpu要求较低,大内存和高速磁盘会显著增加它的性能。
3)logstash。主要用于数据的过滤和整形。这个组件非常贪婪,会占用大量资源,千万不要和应用进程放在一块。不过它算是一个无状态的计算节点,可以根据需要随时扩容。
4)elasticsearch。可以存储容量非常大的日志数据。注意单个索引不要过大,可以根据量级进行按天索引或者按月索引,同时便于删除。
5)kibana。和es集成度非常好的展示组件
选择的组件越多,整个过程会越优雅。尤其是kafka的加入,会让整个链条的头和屁股都变得完美可换,比较魔幻。一个晋级方式就是:ELK->ELKB->ELKkB。
实践旅程
日志格式
为了串联我们的这些组件,需要准备一些小小的数据。其中,nginx日志是最常见的,它已经默认成为了http服务的负载均衡器。
首先,需要对它的日志格式进行一下规整,我这里有一个比较好用的配置。
log_format main
'$time_iso8601|$hostname|$remote_addr|$upstream_addr|$request_time|''$upstream_response_time|$upstream_connect_time|$status|$upstream_status|''$bytes_sent|$remote_user|$uri|$query_string|$http_user_agent|$http_referer|$scheme|''$request_method|$http_x_forwarded_for' ;access_log logs/access.log main;最终,生成的日志可能会长下面这个样子,内容还是比较全的。这种格式的日志,无论是交给程序处理,还是使用脚本处理,都方便的多。
2019-11-28T11:26:24+08:00|nginx100.server.ops.pro.dc|101.116.237.77|10.32.135.2:41015|0.062|0.060|0.000|200|200|13701|-|/api/exec|v=10&token=H8DH9Snx9877SDER5627|-|-|http|POST|112.40.255.152
收集器
接下来,需要配置filebeat组件。上面也提到了,由于这个东西是部署在业务机器上的,那就需要严格控制它的资源。完整配置文件可以在附件中获取。
比如cpu资源限制。
max_procs: 1
内存资源限制。
queue.spool:
file:
path: "${path.data}/spool.dat"
size: 512MiB
page_size: 32KiB
write:
buffer_size: 10MiB
flush.timeout: 5s
flush.events: 1024另外,还可以增加一些额外的字段。
fields:
env: pro接下来需要配置kafka。由于日志量级一般都比较大,又没有非常明显的意义,所以副本数超过2,没有什么用处,反而会增加故障恢复的时间。
过滤器
logstash的配置可能是最让人迷惑的地方了,这也是我们主要介绍的点。因为上面的nginx日志,将会被解析成elasticsearch能够识别的json串。
通过input部分,就可以接入一些数据源。在这里,我们的数据源变成了kafka。如果你有多个kakfa,或者多个数据源,都可以在这里定义。
然后,就可以在filter部分,定义一些数据的清洗动作。这里有着非常蛋疼的语法,用着非常蹩脚的api,尤其是日期处理方面。如果代码没有格式化,嵌套的层次会让人发晕。据说使用的是ruby语法。
注意,event是个内置变量,代表的是当前的一行数据,包括一些基础属性。可以通过get方法获取一些值。
比如,获取最主要的body信息,也就是具体的行信息。
body = event.get('message')然后,把它解析成相应的key/value值。这个分隔符|就是我们nginx日志的分割符。有没有一股蓬勃而出的冲动?
reqhash = Hash[@mymapper.zip(message.split('|'))]
query_string = reqhash['query_string']
reqhash.delete('query_string')日期处理也是让人心碎的旅程。
time_local = event.get('time_local')
datetime = DateTime.strptime(time_local,'%Y-%m-%dT%H:%M:%S%z')
source_timestamp = datetime.to_time.to_i * 1000
source_date = datetime.strftime('%Y-%m-%d') event.set('source_timestamp',source_timestamp)
event.set('source_date',source_date)假如想要解析query param,这个也是有的,不过依然比较绕。
query_string = reqhash['query_string']
query_param = CGI.parse(query_string)
query_param.each { |key,value| query_param[key]=value.join() }
reqhash['query_param'] = query_param
buffer_map = LogStash::Event.new(reqhash)
event.append(buffer_map)这么多奇形怪状的函数,是从何而来呢?logstash不会告诉你,我是从ruby官方查的。可能是L并不屑于与我们交流。
https://ruby-doc.org/core-2.5.1/
如果你的日志格式定义的比较怪异,或者嵌套层次比较深,要注意了。注定解析是要下一番功夫了。
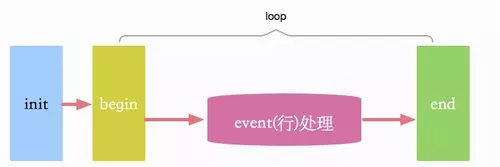
不过logstash有一个output,叫做stdout,可以实时的调试这个过程,你需要肉眼判断结果。这就比较考验一次性编程成功的能力了。
End
共同学习,写下你的评论
评论加载中...
作者其他优质文章


