
一,查询与索引
1.Series和一维数组的不同:
在一维数组中就无法通过索引标签(index)获取数据,index默认是从0开始,步长为1的索引,也可以自己设置索引标签。
2.若有两个序列,对其进行算术运算,这时索引就体现了价值——自动化对齐
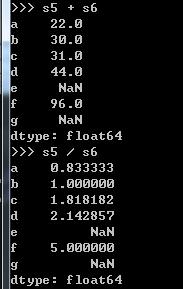
由于s5、s6中存在非对应索引,故结果存在NaN。这里的运算过程就应用了序列索引的自动对齐。对于DataFrame不仅自动对齐行,也会自动对齐列(columns_name)。
3.DataFrame索引
DataFrame数据: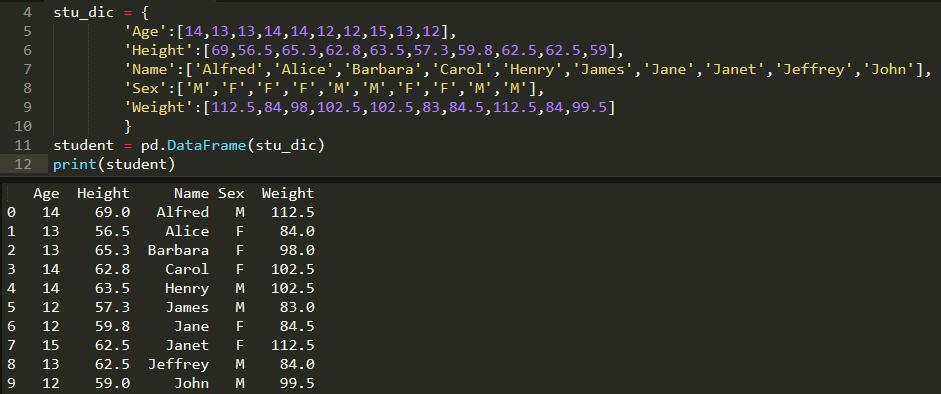
查询指定行:
print(student.loc[[0,2,4,5,7]]) #这里的loc索引标签函数必须是中括号[ ]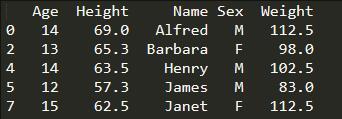
查询指定列:
print(student[‘Height’].head()) #只查询一列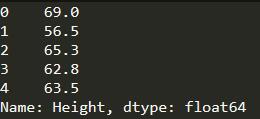
print(student[[‘Name’,‘Height’,‘Weight’]].head()) #如果多个列的话,必须使用双重中括号[]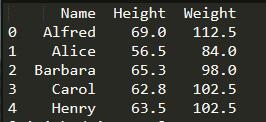
print(student.loc[:,[‘Name’,‘Height’,‘Weight’]].head())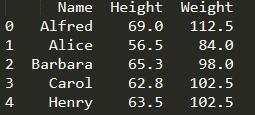
按条件查询:student[(条件1) & (条件2)]
eg1: 查询12岁以上的女生信息
print(student[(student['Sex'] == 'F') & (student['Age'] > 12)])
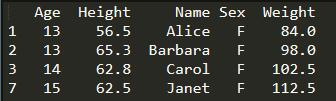
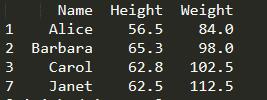
eg2:查询出12岁以上的女生的姓名、身高和体重
print(student[(student['Sex']=='F') & (student['Age']>12)][['Name','Height','Weight']])
如果是多个条件的查询,必须使用&(and)或者丨(or)的两端条件用括号括起来。
二,简单的统计分析
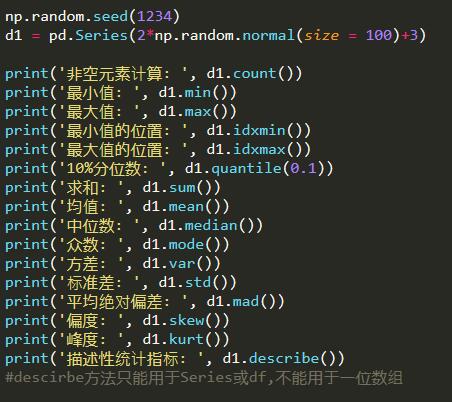
在实际工作中,可能处理一些数据型DataFrame,将函数应用到DataFrame中的每一列,可以使用apply函数。
import pandas as pd
import numpy as np
np.random.seed(1234)
d1 = pd.Series(2*np.random.normal(size = 100)+3)
d2 = np.random.f(2,4,size = 100)
d3 = np.random.randint(1,100,size = 100)
def stats(x):
return pd.Series(
[x.count(),x.min(),x.idxmin(),x.quantile(.25),x.median(),x.quantile(.75),
x.mean(),x.max(),x.idxmax(),x.mad(),x.var(),x.std(),x.skew(),x.kurt()],
index = ['Count','Min','Whicn_Min','Q1','Median','Q3','Mean','Max','Which_Max','Mad','Var','Std','Skew','Kurt']
)
df = pd.DataFrame(np.array([d1,d2,d3]).T,columns = ['x1','x2','x3'])
print(df.head())
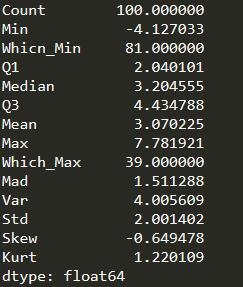
print(stats(df['x1']))
print(stats(d1))
点击查看更多内容
为 TA 点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中




感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦