
最近接了一个私活,指导学妹完成毕业设计。核心思想就是利用SVM模型来预测股票涨跌,并完成策略构建,自动化选择最优秀的股票进行资产配置。
废话少说,言归正传。这里有关SVM、PCA等等这些与项目相关的数学知识不会提及,我以后会在算法专题里详细描述。
本项目用pycharm + anaconda3.6开发,涉及到的第三方库有pandas,numpy,matplotlib,skllearn。
流程图
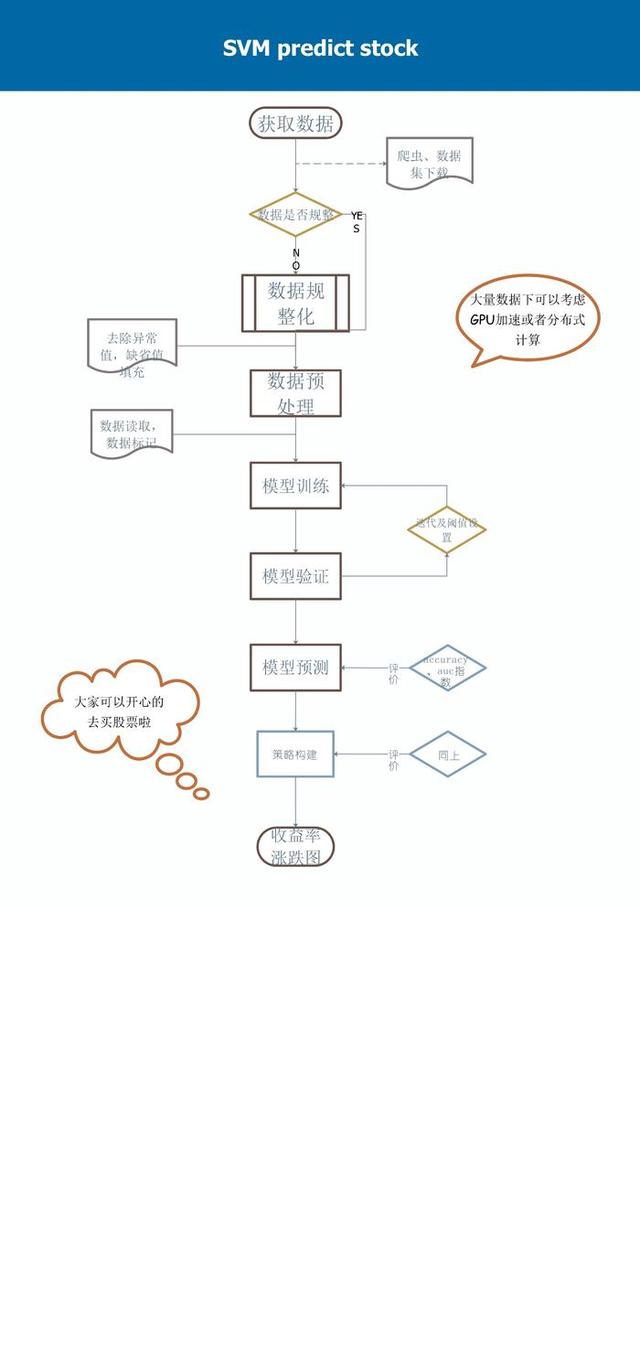
在做这个项目的过程中,我体会到想成为一个合格的数据分析或者数据挖掘工程师不仅技术要过关,还需要了解所要挖掘数据涉及到的领域的相关知识。举个例子,在做数据预处理的时候,不知道超额收益率是怎么个意思,查阅资料才了解,超额收益率是股票行业里的一个专有名词,指大于无风险投资的收益率,在我国无风险投资收益率即是银行定期存款。
参数设置
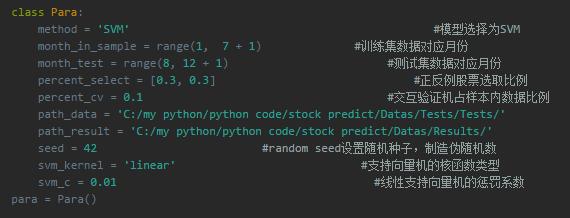
这个就是参数的初始化,没有什么要说的。
数据读取以及标记

代码的基本功能注释里也写了一些,不过不够全面,我再详细说一下。这三部分代码所实现的功能是读取数据,并对数据进行预处理。我已经把最原始的数据整理好放在了excel表格里,并且将第一个月的全部股票的参数放在一个excel里,并将其命名为1.csv,以此类推,我爬取了157个月的数据,总共有157个excel。因此代码里循环的便是excel的文件名,也就是依次读取excel文件。因为数据量太大,所以我一般调试的时候只跑12个月。所以我在参数初始化阶段,训练集(1,8),测试集(8,12)。
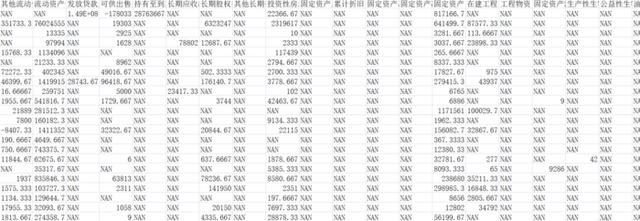
将数据读取到DataFrame表格里后,并不是全部使用,而是取超额收益值最好的前百分之三十,以及最差的后百分之三十,并在表格后追加一列,列名叫return_bin,将最好最差的百分之三十的股票的return_bin列各赋值1,0。然后将每个读取并加工的excel表格拼接在一起形成一个大表格,从总抽取70个因子作为X_in_sample,抽取return_bin作为y_in_sample作为训练集。
训练模型
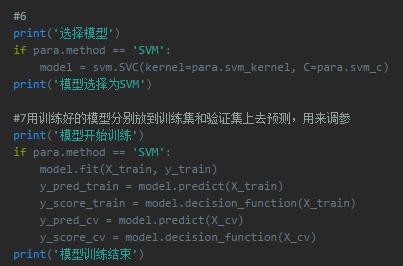
这个也比较好理解,就是选择sklearn库里的svm模块对数据进行训练。svm模型是集成封装好的,拿来用就可以。
模型预测与评价
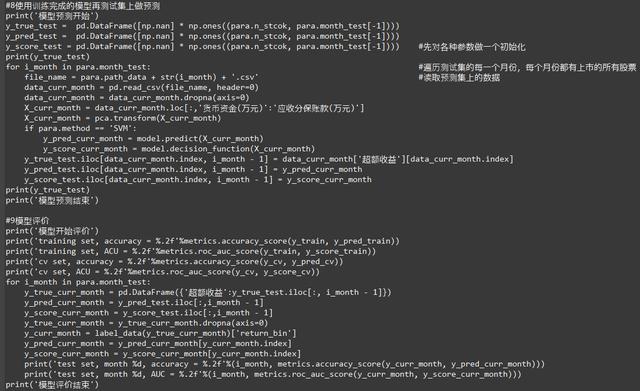
现在模型就训练好了,然后就那训练好的模型在测试集上来跑,看看情况到底如何。
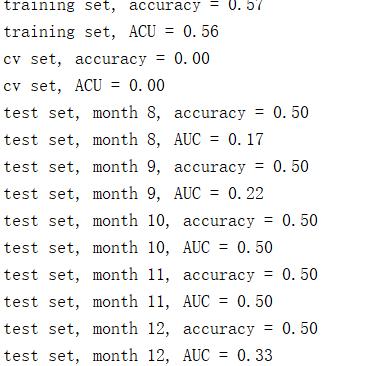
可以看到参数并不是多好,这是训练集上数据太少的原因。那我们来改动一下,把训练集改成(1,10),测试集改成(10,12)看看有没有改变。
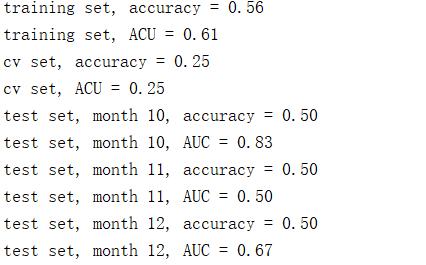
训练集从只有6个月变成9个月(1-10在代码上体现为1-9),参数情况大有改观。可见数据对机器学习模型训练的重要性。
策略构建以及策略评价
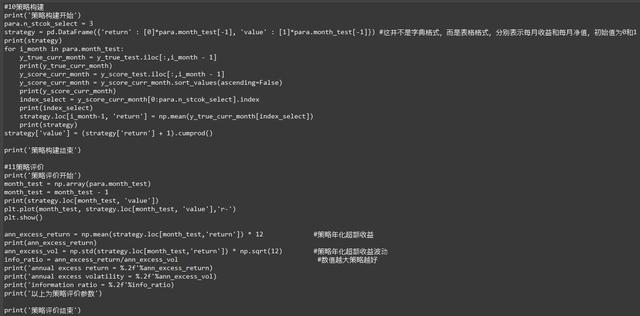
所谓策略构建就是选择什么样的股票,代码里将股票按照超额收益率进行排序,然后我设置para.n_stcok_select = 3意思就是选择超额收益率前三名进行购买。
所谓策略评价这里采用的评价体系就是将选择的三支股票的每月超额收益率取平均值乘12,来作为这三只股票在该月的年化收益率。
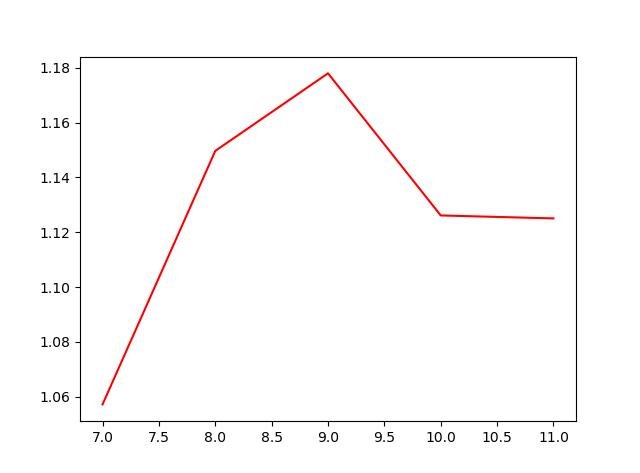
Figure_1.png
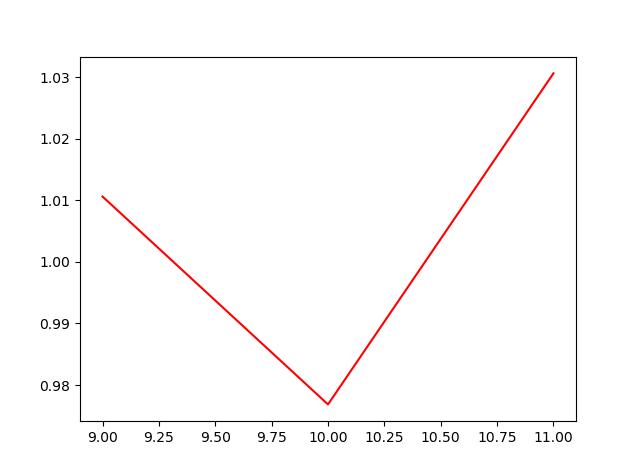
Figure_2.png
以上两张图是选择不同月份做训练集后,模型策略的表现。
在这里还要提及的是这行代码,month_test = np.array(para.month_test)
month_test = month_test - 1。这个涉及到了np数组的高阶用法。一般数组是无法和数字做运算的,可是将普通数组用np.array()加工过后,变成了np数组,他拥有一个广播属性,可以直接与数字运算。该行代码就是将数组里每个元素都减1。

共同学习,写下你的评论
评论加载中...
作者其他优质文章



