

秒杀系统是一件复杂的事,从我们上篇文章中就能看出来,洋洋洒洒又臭又长接近5000字。这样复杂的东西,如果每个系统都要写一次,势必是个非常大的人力浪费。其中一个环节考虑不周,就会功败垂成。
从上次在技术交流群里聊到秒杀系统的设计,到目前为止已经招募到8位对其非常感兴趣的小伙伴,主笔编码。经过大家的讨论,感觉除了做成一个秒杀的demo,我们还可以更近一步,将其做成一个秒杀引擎。
在这里,xjjdog将和大家分享这个过程。结果并不重要,重要的是思路和过程。你可能会获取一些框架类代码的开发经验,希望或许如此吧。
一个黑盒
最主要的思路,就是把秒杀引擎看成是一个黑盒,对完成秒杀的逻辑进行屏蔽。一端输入,一端输出。也就是说,你把要秒杀的数据,经过清洗倒入秒杀引擎后,剩下的就没原来系统的什么事了。
“精致秒杀引擎,云加速,弹性可伸缩高可用架构。SLA全年5个9,绿色无公害,为您的业务保驾护航。专业的售前技术支持,协助您完成最优配置。”是不是非常熟悉而扯淡的宣传语?这就是黑盒,我只要完成功能了,你管我是牛鬼蛇神。
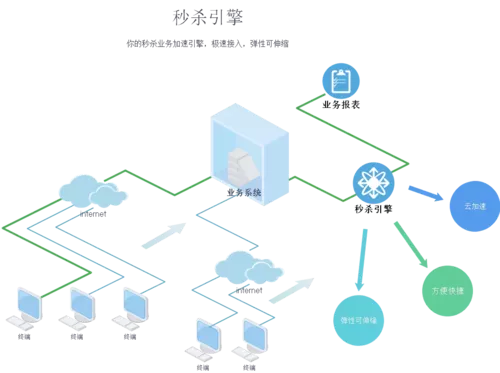
概念抽象
从过程上来讲,我们将秒杀的代码也归类为三个阶段:准备、秒杀、清算。为了完成上面的目标,还是需要对涉及的资源进行进一步抽象。以下是初步定下的一些概念,后续或有变动。
actor 秒杀参与者
根据字面意思,就能够看到这里抽象的是操作的主体,也就是参与的人。actor会带有一些附着信息,比如用户的一些基本信息。这样,就能够实现一些个体的流控策略,或者风控策略。举个例子,假如有一个逻辑:最新注册的账号没有秒杀资格。那么actor的附加信息里,就应该包含用户的注册时间。
queue 缓冲队列
队列是秒杀请求的缓冲,是首先落地的地方。无论是内存队列,还是分布式队列,其实操作起来都是差不多的。我们也对其进行一下抽象。这样,通过配置参数,就可以调节秒杀队列的行为和性能。
source 秒杀数据源
数据的提供者。数据可能来源于一个外部的数据库(db),也可能来自于外部的推送(push),也可能来自于外部接口的拉取(pull)。这个数据获取的过程,我们就给它起个名字,叫做source。当然,这部分的功能也是可以扩展的,比如source数据来自ES。
sink 秒杀数据落地下沉
主要处理秒杀完成后,数据的去向。与source类似,它是一个反向的动作。处理的是类似库存扣减一类的落地动作。这个组件的行为,或许是推送,也或许是直接发送一个事件消息。source和sink,组成了一个秒杀目标的具体数据流向,是黑盒之外的东西。
target 秒杀目标
是时候给秒杀目标起个名字了。它拥有一个在秒杀引擎中唯一的名字:targetID,用来标识是哪一种商品。非常非常多的个性化配置参数,就在这里,比如秒杀开始时间,队列长度,是否懒加载商品等。
stock 库存操作
库存操作指的是在黑盒之内的操作,这些信息会不定期的进行合并,sink到业务端。对stock的操作,就需要保证其正确性和吞吐量。这也是我们的核心概念之一。
action 动作
类似消息总线的作用。动作,action,指的是actor所产生的所有行为的载体,在整个生命周期中,是不可变的(Immutable)。动作会被缓冲,追踪,调度,记录,是穿插整个引擎的行为实体。
runtime 实时运行单元
runtime是变化的,用于秒杀混沌期的信息缓冲,原则上不会记录和下沉。我们的运行单元会做很多运算和判断,直到最终的数据,达到BASE的状态。
目标
秒杀引擎会用到各种各样的技术,我们手到拈来,但是也需要一种方式进行分享。配合教程+源码的方式,会有更好的效果。为了保证程序的健壮性,会使用单元测试,尽量的覆盖代码;为了评估整个系统的性能,我们也会介绍一些压力测试方面的工具;最后,会使用一个springboot项目集成秒杀引擎,做一个最终的效果。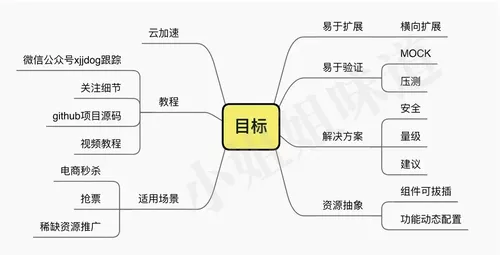
其中的抽象概念部分,要能够做到动态替换,并提供自定义的扩展方式。
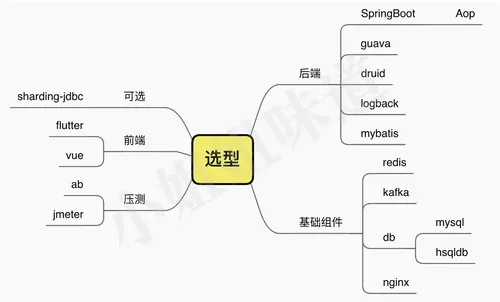
暂定的技术选型
秒杀引擎包含三部分。
1、核心部分
此模块会依赖尽量少的组件,以便用在各种开发环境中(不仅仅是spring),涵盖了重要的概念和实现逻辑。会有特别多的精细化配置参数进行性能调节。
2、demo部分
使用springboot、vue、flutter等最流行的技术,展现一个完整的示例。
3、方案部分
对一些特殊场景的优化,或者某个扩展性的主题,出具的具有典型性代表的方案。
用最有营销力的一个词来说,就是行业解决方案。
代码
项目代码在github,目前只有部分抽象概念。有兴趣可以跟踪。
https://github.com/xjjdog/seckill-engine
共同学习,写下你的评论
评论加载中...
作者其他优质文章


