
在绝大多数情况下,Mysql索引都是基于B+树的,而索引可以提高数据查询的效率。
但是Mysql是如何利用B+树进行查询的呢?索引的作用只是提高查询效率吗?
Mysql中的B+Tree索引
假设有一张教师表,里面有教师编号、名字、学科、薪资四个字段。
当你执行下面这条创建索引的sql语句时:
create index id_name on teacher(name);
Mysql就会在磁盘中构建这样一颗B+树:
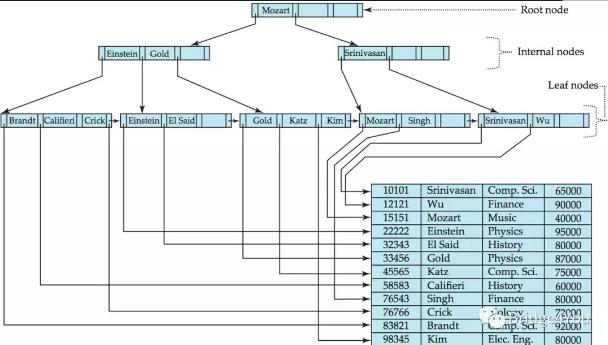
这样一棵树有什么用呢?首先当然是加速查询。
举个简单的例子,假设现在要查找名字为“Mozart”的教师的数据:
select * from teacher where name = “Mozart”;
既然我们已经建立了B+树,那么就要好好利用它来加速查询,而不是傻傻的去遍历整张表。
从根节点开始,我们发现,根节点就是”Mozart”,不过很可惜,根节点上面只有name字段的信息,没有其他字段的数据。
这是B+树的一个特点——只有叶子节点(leaf nodes)会指向行数据。
我们比较了要查找的值和搜索码值,发现相等,于是跳到搜索码右边的指针指向的节点,也就是“Srinivasan”所在的节点(注意,这里的节点是指下图红色框画出的区域)。
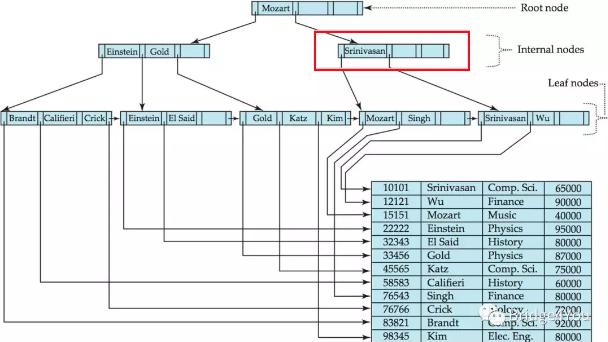
接着,我们遍历当前节点的搜索码值,和要查找的值做比较。
我们发现“Srinivasan”已经大于我们要查找的”Mozart”了,于是就此止步,跟随着“Srinivasan”左边的指针,跳到下一级的节点。
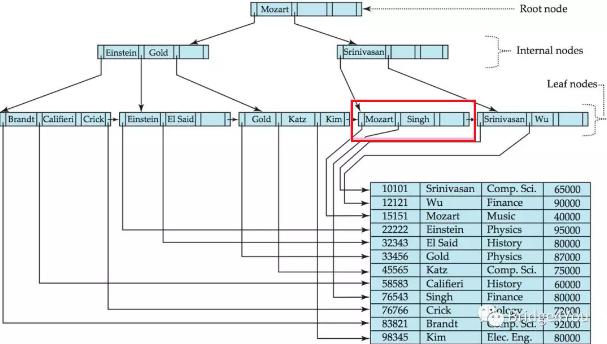
接着,还是一样,我们继续遍历当前节点的搜索码值,和要查找的值做比较。
这时我们又碰到了一个搜索码值为”Mozart”的块,和上次不同的是,这次是在叶子节点找到的,而不是根节点。叶子节点的指针指向行数据。
于是,我们循着”Mozart”左边指针的指引,找到了”Mozart”的行数据。
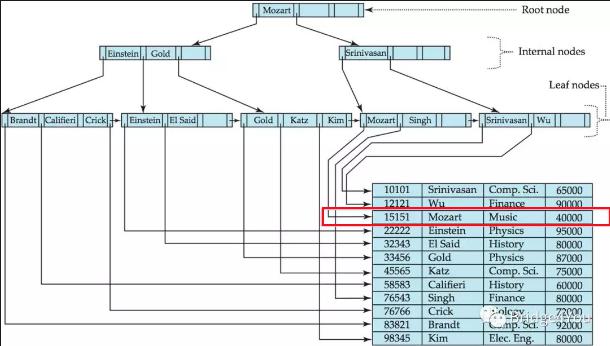
当然,这只是最最简洁的描述,如果name没有加唯一索引,那么mysql还需要遍历下一个块,看看搜索码值是不是也是”Mozart”。另外,叶子节点也不会直接存储行数据的位置,而是存储聚簇索引(clustered index)的值,通过聚簇索引去找到数据的位置,这个在后面会解释。
** B+树的查找原则:**
1、从节点最左边的搜索码值开始,向右遍历
2、如果搜索码值大于被查找值,则跳到搜索码值左边指针指向的节点
3、如果等于,则跳到右边指针指向的节点
4、如果小于,则遍历下一个搜索码值
5、如果遍历完了整个节点,还是没发现有大于等于被查找值的搜索码,则跳到该节点最后一个非空指针指向的节点
6、不断循环,直到找到被查找值,或者发现被查找值不存在
作为测验,大家可以模拟上面查找”Mozart”的过程,试着查找”Brandt”和“El Said”。
复合索引
上面讲的只是单索引,那么如果是复合索引呢?
create index id_name_subject on teacher(name, subject);
一样的,只是这次的搜索码值,不再只是存放name一个字段,而是存放了name和subject两个字段。
熟悉Java的同学,可以理解为,之前只是一个字符串,现在变成了一个Object了。
之前只是单纯的字符串比较,现在是对象间的比较。
对象怎么比较呢?一项项来,如果前一项分不出胜负,那么再比下一项。
比较的顺序,就是你索引创建语句里写的顺序。
比如按照上面那条sql创建出来的索引,mysql会先比较name,如果name一样,再比较subject。
其他查找原则,和单索引一致。
最左前缀匹配
弄懂了单索引和复合索引的原理,再来理解Mysql中经常被提及的——最左前缀匹配(leftmost prefix),就轻松的多了。
什么是最左前缀匹配?简单说,就是你给一个表的a,b,c三个字段建了索引:
create index id_a_b_c on foo(a, b, c);
那么当你where条件是a或者a、b或者a、b、c时,都可以命中索引,除此之外,都不能命中索引,比如a、c,或者b、c等。
为什么?看看上面的单索引和复合索引就知道了。
有一个例外,当你select的字段里有复合索引里的字段,那么where语句不需要满足最左前缀匹配,Mysql也会走索引。
比如:
select a from foo where b = “xxx”;
不过这时走索引不是为了加速查询(这时候索引对查询效率提升效果几乎没有),而是为了利用下面要讲的,覆盖索引,来减少对数据的检索。
覆盖索引
覆盖索引(covering index)的原理很简单,就像你拿到了一本书的目录,里头有标题和对应的页码,当你想知道第267页的标题是什么的时候,完全没有必要翻到267页去看,而是直接看目录。
同理,当你要select的字段,已经在索引树里面存储,那就不需要再去检索数据库,直接拿来用就行了。
还是上面的例子,你给a、b、c三个字段建了复合索引,那么对于下面这条sql,就可以走覆盖索引:
select b,c from foo where a = “xxx”;
explain一下,你就会发现extra字段是“Using index”,或者使用explain FORMAT=JSON … ,输出一个json结果的结果,看“using_index”属性,你会发现是“true”,这都意味着使用到了覆盖索引。
Using index (JSON property: using_index):
The column information is retrieved from the table using only information in the index tree without having to do an additional seek to read the actual row.
聚簇索引和二级索引
现在问一个问题,下面这条sql,会走覆盖索引吗?还是需要去磁盘再一次检索?
select id,b,c from foo where a = “xxx”;
和上一条sql对比,这一次我们在select里头,加了一个字段,主键id。
有同学说,id不在复合索引里,B+树没有id的信息,只能再查一次数据库了。
非也,在上面介绍B+ tree时有提到过,叶子节点不会直接存储数据的位置,而是存储了聚簇索引(clustered index)的值,再通过聚簇索引,找到数据对应的位置。
那什么是聚簇索引呢?
Every InnoDB table has a special index called the clustered index where the data for the rows is stored.
简单说,聚簇索引就是用来存储行数据的位置的。
什么样的字段才可以作为聚簇索引?
那当然是要具有唯一性的字段,比如:主键、唯一索引(unique index)所在字段
这两个都没有?没关系,mysql会给你建一个rowid字段,用它作为聚簇索引:
If the table has no PRIMARY KEY or suitable UNIQUE index, InnoDB internally generates a hidden clustered index named GEN_CLUST_INDEX on a synthetic column containing row ID values.
除了聚簇索引,mysql中的其他索引,都叫二级索引(secondary index),有时也翻译为“辅助索引”。
All indexes other than the clustered index are known as secondary indexes.
回到本小节开头的问题,虽然id不在复合索引里头,但是mysql里所有的二级索引的叶子节点,都会存储聚簇索引的信息,而id是主键,所以所有的叶子节点,都会有id的信息,因此还是可以走覆盖索引。
总结
这篇文章从一颗简单的B+树,引申出了Mysql中常见的几个索引概念:
单索引(Column Indexes):当你为一个字段建了索引时,mysql默默种了一棵树。通过这颗树,可以实现高效的逐级查找。
复合索引(Multiple-Column Indexes/Compound Indexes):跟单索引原理一致,比较的方式变了一下,从字符串比较变为对象比较。
最左前缀匹配:一个理所当然的概念,只要你理解了上面两位。
覆盖索引:有些信息已经在树里面了,就不必再麻烦磁盘老人家了。
聚簇索引和二级索引:叶子节点不直接存储数据位置的信息,存储数据位置信息的,只有聚簇索引。
共同学习,写下你的评论
评论加载中...
作者其他优质文章


