
数据库管理系统索引技术概述
2018年4月23日 Wray Zheng9
文章目录
为什么需要索引?
索引中的一些概念
索引如何提高查询效率?
索引的分类
稀疏索引与稠密索引
主索引与辅助索引
聚簇索引和非聚簇索引
总结
为什么需要索引?
我们知道,磁盘的读写效率是比较低的,以传统机械硬盘为例,读写时涉及到读写头的寻道和定位,这部分时间开销可能比实际读写数据时所花的时间还要长。即使是固态硬盘,由于数据的存储可能是散落在各个磁盘块中,通过指针连接起来,因此访问数据时需要对磁盘进行多次读写,同样会带来效率上的问题。
再来看数据库的存储,数据库中的一个表可能存储在多个文件中,而每个文件包含了多个磁盘块(扇区),我们讨论最好的情况,也就是所有记录都是按查询的字段进行排序,那么此时可以利用二分法等高效的算法进行搜索。如果是在内存中进行这种搜索,log(n) 的时间确实非常高效,但放在磁盘中就未必了,为什么这么说?
因为这些高效算法通常都是在内存中操作的,也就是说数据都已经被加载到内存中。而一个表中包含的数据量可能很大,没办法将这些数据一次性装载到内存中,因此我们需要通过多次读写磁盘来完成这些操作。这样一来,磁盘本身的文件组织方式就会对算法的效率造成影响。
比如我们用二分法来查找数据,二分法是建立在数据能够被随机访问的基础上的,这样可以计算出中间位置,并直接访问该位置。如果磁盘块是连续的还好,假设每条记录定长,那么我们可以得到中间位置的扇区号,直接访问该扇区,从而得到目标记录;但如果磁盘块不连续,那么只能通过指针进行连接,这样我们就没办法直接得出中间位置的扇区号,只能从第一个磁盘块开始,依次访问它的下一个磁盘块,也就是顺序访问,即使记录是有序的,二分法也没有用武之地,只能从头遍历记录进行查找。
总结上述提到的问题,就是当数据量大的时候,数据无法被一次性加载到内存中,因此对数据的查找操作受限于文件在磁盘中的存储方式,特别是利用指针来连接不连续磁盘块的情况,极大影响查询效率。
因此,我们想到了用索引来定位记录,提高查询的效率。
索引中的一些概念
以字典为例,每个字及其解释都可以看作一条记录,这条记录大致可分为几个字段:字、读音、解释。
我们是如何查找一个字对应的记录呢?通过目录。
因此目录就相当于 索引,目录中记录了每个字及其对应的页码,相当于一个个 索引项。
我们是根据什么来找到索引项的?对了,是字。因此字就是用于索引的字段,叫做 索引字段,页码相当于一条记录的实际存储地址,等价于指向记录所在磁盘位置的指针。
存储索引项的文件称为 索引文件,而存储实际数据(表)的文件称为 主文件。
索引如何提高查询效率?
索引的意义,就在于它只抽取了原记录中的一部分关键的信息,并与记录的位置建立关联,以此定位记录在磁盘上的真正位置。
索引存储的数据较少,更容易被加载到内存中,也就意味着我们可以通过高效的算法在索引上查找目标记录的索引项,得到目标记录在磁盘上的位置,然后直接读取该记录。
例如以字段 A 作为索引,那么每个索引项只存 A 的值,以及 A 对应记录所在磁盘的位置。这样一来,我们通常可以将索引文件加载到内存中,然后根据待查询记录字段 A 的值,找到索引项,得到该记录在磁盘中的位置,就能直接到特定磁盘块将目标记录读取出来。
索引的分类
稀疏索引与稠密索引
首先说说稀疏索引。
稀疏索引只包含了索引字段中一部分的值,通过这些值可以确定目标记录的范围,然后再到这个范围中顺序查找。因此,稀疏索引要求主文件必须按照索引字段进行排序,通常索引文件本身也有相同的排序关系。
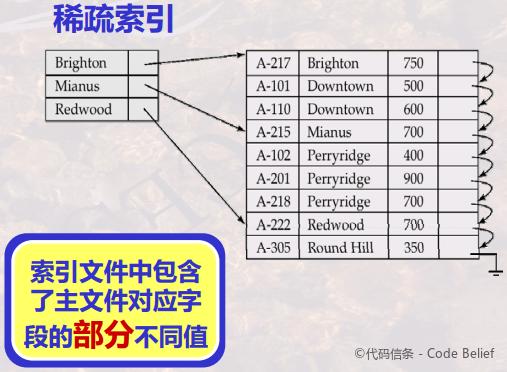
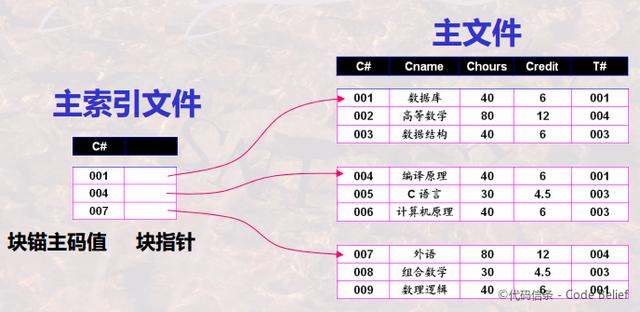
下面会讲到主索引,它是一种特殊的稀疏索引,它的索引项并不是指向记录,而是指向记录所在的存储块。也就是说,一个存储块对应一个索引项。
再来说说稠密索引。
稠密索引,顾名思义,就是索引项非常稠密,到什么程度呢?每个索引字段的值都对应一个索引项。
如果索引字段没有重复值,那么索引和记录就是一一对应的关系:
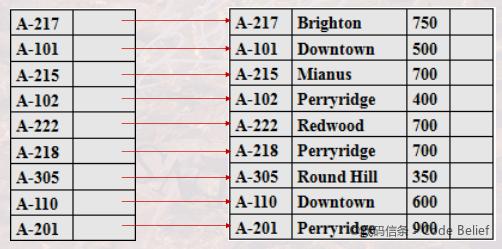
如果索引字段包含重复的值,有三种索引策略。
一是索引中包含重复值:
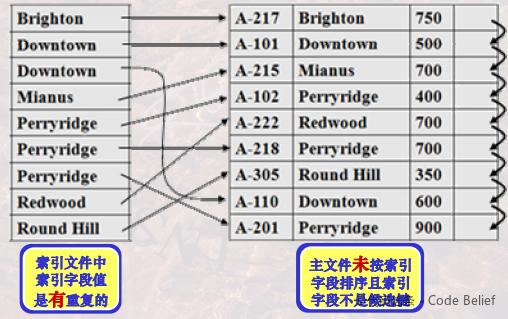
此时索引项和记录也是一一对应的关系。
二是索引中不包含重复值,主文件按索引字段排序:
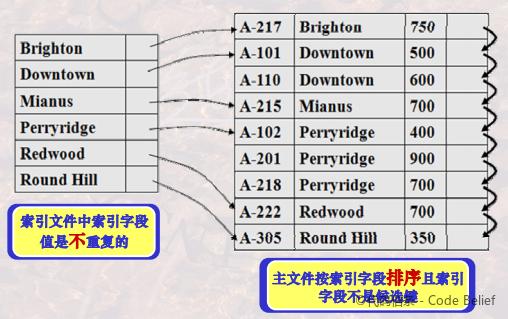
因为索引字段值相同的记录是连续放在一起的,因此索引项只需指向索引字段值相同记录中的第一条记录。
三是索引中不包含重复值,主文件不按索引字段排序:
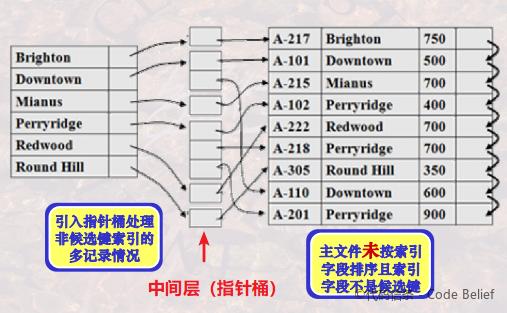
这里引入了一个中间层。因为主文件中索引字段值存在重复,并且没有按照索引字段排序,因此必须对每条记录建立一个索引,才能由索引文件找到主文件中的记录。但是由于索引中不包含重复值,因此我们可以引入一个中间层,让索引项不直接指向记录,而是指向中间层。中间层的指针桶与记录一一对应,并且索引字段值相同的记录对应的指针桶是连续存放的,这样就等价于中间层是按索引字段进行排序。
我们来总结一下稠密索引:
若索引字段不重复,则索引与记录自然一一对应;
若索引字段重复,要么让索引重复,这样索引和记录也可以一一对应;
要么索引不重复,这就要求索引指向的结构是按索引字段排序的(中间层也可以认为是按索引字段排序),这样才可以仅仅指向索引字段值相同记录中的第一条记录。
主索引与辅助索引
主索引通常是针对每个存储块建立一个索引项,索引项的个数与存储表所占的磁盘块数相同。
存储表中位于每一存储块的第一条记录称为锚记录,或称为块锚。
主索引和主文件通常都是按照索引字段进行排序,如前面所说,主索引是稀疏索引。
辅助索引是稠密索引,它是建立在一个或多个非排序字段上的辅助存储结构,通常不同的索引字段值对应一个索引,如果有重复的索引字段值,则用类似链表的结构来存储具有相同索引字段值记录的位置,也就是前面提到的引入中间层的策略。
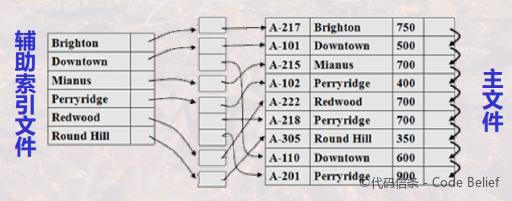
总结和对比主索引与辅助索引:
主索引是稀疏索引,辅助索引是稠密索引;
一个主文件只能有一个主索引,但可以有多个辅助索引;
主索引通常建立在主码/排序码上,辅助索引建立在其它属性上;
可以利用主索引重新组织主文件数据,但不能利用辅助索引来改变主文件数据。
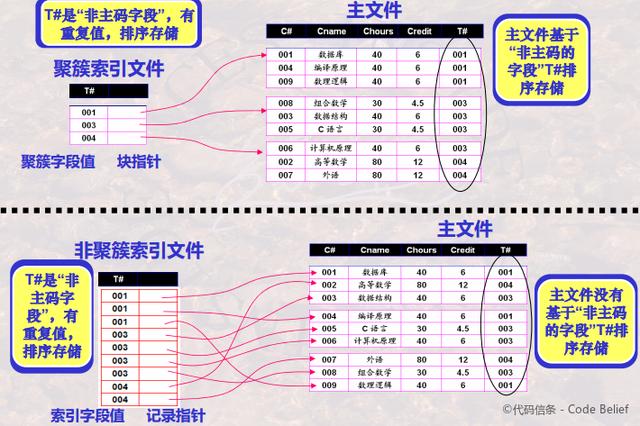
聚簇索引和非聚簇索引
聚簇索引 —— 索引中邻近的记录在主文件中也是邻近存储的;
非聚簇索引 —— 索引中邻近的记录在主文件中不一定是临近存储的。
如果主文件的某一排序字段取值不唯一,那么该字段就称为聚簇字段。聚簇索引通常定义在聚簇字段上;
聚簇索引通常是对聚簇字段上的每一个不同值建立一个索引项;
一个主文件只能有一个聚簇索引文件,但可以有多个非聚簇索引文件;
主索引通常是聚簇索引,辅助索引通常是非聚簇索引;
主索引/聚簇索引能够决定记录的存储位置,而非聚簇索引只能用于查询已存储记录的位置。
总结
这篇文章对索引进行了概括性的介绍,说明了索引在数据库查询中的意义,并介绍了索引的几种分类方式。
有关索引的具体实现,包括 B+ 树索引以及散列索引,后续将会单独进行介绍。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



