
聊聊面试必考-递归思想与实战
本篇文章你将学到
为什么要写这篇文章
- “递归”算法对于一个程序员应该算是最经典的算法之一,而且它越想越乱,很多复杂算法的实现也都用到了递归,例如深度优先搜索,二叉树遍历等。
- 面试中常常会问递归相关的内容(深拷贝,对象格式化,数组拍平,走台阶问题等)
- 最近项目中有一个需求,裂变分享,但是不仅仅给分享人返利,还会给最终分享人返利,但是只做到4级分销(也用到了递归,文中会讲解)
作者简介:koala,专注完整的 Node.js 技术栈分享,从 JavaScript 到 Node.js,再到后端数据库,祝您成为优秀的高级 Node.js 工程师。【程序员成长指北】作者,Github 博客开源项目 https://github.com/koala-coding/goodBlog
递归算法是什么
维基百科:递归是在一个函数定义的内部用到自身。有此种定义的函数叫做递归。听起来好像会导致无限重复,但只要定义适当,就不会这样。 一般来说,一个递归函数的定义有两个部分。首先,至少要有一个底线,就是一个简单的线,越过此处,递归。
我自己简单地理解递归就是:自己调用自己,有递有归,注意界限值。
一张有趣的图片:

递归算法思想讲解用和注意事项
什么时候使用递归?
看一个十一假期发生的小例子,带你走进递归。十一放假时去火车站排队取票,取票排了好多人,这个时候总有一些说时间来不及要插队取票的小伙伴,我已经排的很遥远了,发现自己离取票口越来越远了呢,我超级想知道我现在排在了第几位(前提:前面不再有人插队取票了),用递归思想我们应该怎么做?
满足递归的条件
一个问题只要同时满足以下3 个条件,就可以用递归来解决。
- 一个问题的解可以分解为几个子问题的解。
何为子问题 ?就是数据规模更小的问题。
比如,前面说的你想知道你排在第几位的例子,你要知道,自己在哪一排的问题,可以分解为每个人在哪一排这样一个子问题。
- 这个问题分解之后的子问题,除了数据规模不同,求解思路完全一样
比如前面说的你想知道你排在第几的例子,你求解自己在哪一排的思路,和前面一排人求解自己在哪一排的思路,是一模一样的。
- 存在递归终止条件
比如前面说的你想知道你排在第几的例子,第一排的人不需要再继续询问任何人,就知道自己在哪一排,也就是 f(1) = 1,这就是递归的终止条件,找到终止条件就会开始进行“归”的过程。
如何写递归代码?(满足上面条件,确认使用递归后)
记住最关键的两点:
-
写出递归公式(注意几分支递归)
-
找到终止条件
分析排队取票的例子(单分支层层递归)
排队取票例子的子问题已经分析出来,我想知道我的位置在哪一排,就去问前面的人,前面的人位置加一就是这个人当前队伍的位置,你前面的人想知道继续向前问(一层问一层,思路完全相同,最后到第一个人终止)。递推公式是不是想出来了。
f(n) = f(n-1) + 1
//f(n) 为我所在的当前层
//f(n-1) 为我前面的人所在的当前层
// +1 为我前面层与我所在层
再看一个走台阶例子(多分支并列递归)
具体学习如何分析和写出递归代码,以最经典的走台阶例子进行讲解。
题:假设有n个台阶,每次你可以跨一个台阶或者两个台阶,请问走这n个台阶有多少种走法?用编程求解。
按照上面说的关键点,先找递归公式:根据第一步的走法可分为两类,第一类是第一步走了一个台阶,第二类是第一步走了两个台阶。所以n个台阶的走法=(先走1台阶后,n-1个台阶的走法)+(先走2台阶后,n-2个台阶的走法)。写出的递归公式就是:
f(n) = f(n-1)+f(n-2)
有了递推公式第,第二步有了递推公式,递归代码基本上就完成了一半。我们再来看下终止条件。当有一个台阶时,我们不需要再继续递归,就只有一种走法。所以 f(1)=1。这个递归终止条件足够吗?我们可以用 n=2,n=3 这样比较小的数试验一下。
n=2 时,f(2)=f(1)+f(0)。如果递归终止条件只有一个 f(1)=1,那 f(2) 就无法求解了。所以除了 f(1)=1 这一个递归终止条件外,还要有 f(0)=1,表示走 0 个台阶有一种走法,不过这样子看起来就不符合正常的逻辑思维了。所以,我们可以把 f(2)=2 作为一种终止条件,表示走 2 个台阶,有两种走法,一步走完或者分两步来走。
所以,递归终止条件就是 f(1)=1,f(2)=2。这个时候,你可以再拿 n=3,n=4 来验证一下,这个终止条件是否足够并且正确。
我们把递归终止条件和刚刚推出的递归公式合在一起就是:
f(1) = 1;
f(2) = 2;
f(n) = f(n-1)+f(n-2);
最后根据最终的递归公式转换为代码就是
function walk(n){
if(n === 1) return 1;
if(n === 2) return 2;
return f(n-1) + f(n-2)
}
写递归代码时注意事项
上面提到了两个例子(去十一去车站排队取票,走台阶问题),根据这两个例子(选择这两个例子的原因,十一去车站排队取票问题单分支递归,走台阶问题多分支并列递归,两个例子刚刚好),接下来我们具体讲一下递归的注意事项。
1. 爆栈
十一去车站排队取票,假设这是个无敌长队,可能以及排了1000人(嘿嘿,请注意是个假设),这个时候如果栈的大小为1KB。
递归未考虑爆栈时代码如下:
function f(n){
if(n === 1) return 1;
return f(n-1) + 1;
}
函数调用会使用栈来保存临时变量。栈的数据结构是先进后出,每调用一个函数,都会将临时变量封装为栈帧压入内存栈,等函数执行完成返回时才出栈。系统栈或者虚拟机栈空间一般都不大。如果递归求解的数据规模很大,调用层次很深,一直压入栈,就会有堆栈溢出的风险。
这么写代码,对于这种假设的无敌长队肯定会出现爆栈的情况,修改代码
// 全局变量,表示递归的深度。
let depth = 0;
function f(n) {
++depth;
if (depth > 1000) throw exception;
if (n == 1) return 1;
return f(n-1) + 1;
}
修改代码后,加了防止爆栈加了递归次数的限制,这是防止爆栈的比较不错的方式,但是大家请注意,递归次数的限制一般不会限制到1000,一般次数5次,10次还好,1000次,并不能保证其他的的变量不会存入栈中,事先无法计算
,也有可能出现爆栈的问题。
温馨提示:如果递归深度比较小,可以考虑限制递归次数防止爆栈,如果出现像这种
1000的深度,还是考虑下其他方式实现吧。
2.重复计算
走台阶的例子,前面我们已经推导出了递归公式和代码实现。在这里再写一遍:
function walk(n){
if(n === 1) return 1;
if(n === 2) return 2;
return walk(n-1) + walk(n-2)
}
重复计算说的就是这种,可能这么说大家还不明白,画了一个重复调用函数的图,应该就懂了。
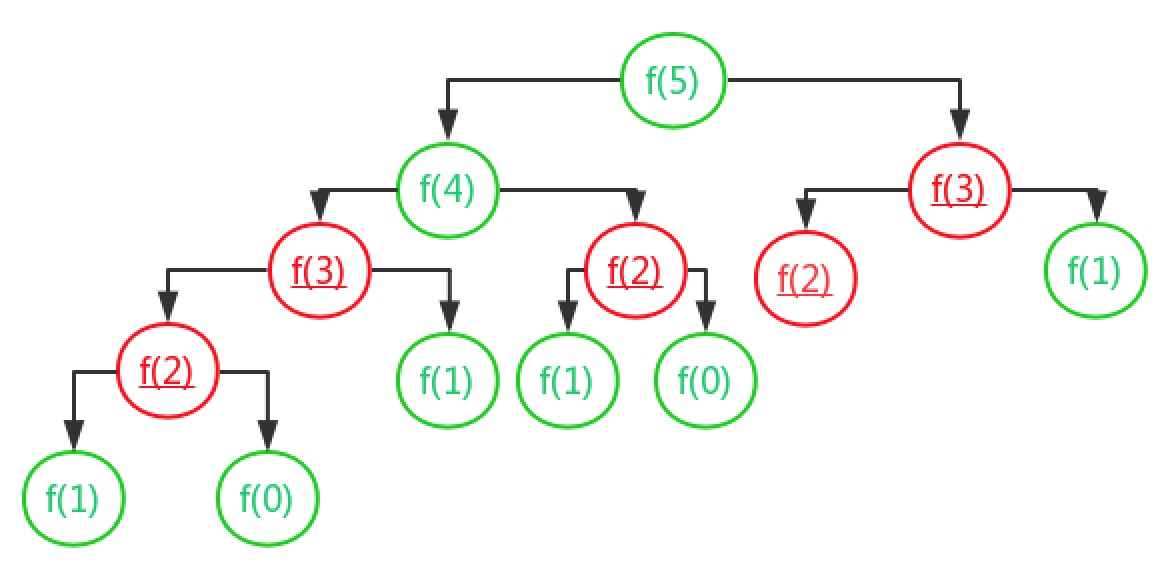
看图中的函数调用,你会发现好多函数被调用多次,比如 f(3) ,计算 f(5) 时候需先计算 f(4) 和 f(3),到了计算 f(4) 的时候还要计算 f(3) 和 f(2) ,这种 f(3) 就被多次重复计算了,解决办法。我们可以使用一个数据结构(注:这个数据结构可以有很多种,比如 js 中可以用set,weakMap,甚至可以用数组。java 中也可以好多种散列表,爱思考的童鞋可以想一下哪一种更优秀哦,后面深拷贝例子我也会具体讲)来存储求解过的 f(k),再次调用的时候,判断数据结构中是否存在,如果有直接从散列表中取值返回,不需要重复计算,这就避免了重复计算问题。
具体代码如下:
let mapData =new Map();
function walk(n){
if(n === 1) return 1;
if(n === 2) return 2;
// 值的判断和存储
if(mapData.get(n)){
return setDatas.get(n);
}
let value = walk(n-1) + walk(n-2);
mapData.set(n,value);
return value;
}
3.循环引用
循环引用是指递归的内容中出现了重复的内容,
例如给下面内容实现深拷贝:
const target = {
field1: 1,
field2: undefined,
field3: {
child: 'child'
},
field4: [2, 4, 8]
};
target.target = target;
具体如何实现深拷贝又要避免循环引用的详细讲解在文中实战部分,请继续往下看,小伙伴。
递归算法的一点感悟
前面提到了使用递归算法时满足的三个条件,确定满足条件后,写递归代码时候的关键点((写出递归公式,找到终止条件),这个关键点文中已经三次提到了哦,请记住它,最后根据递归公式和终止条件翻译成代码。
递归代码,不要试图用我们的大脑一层一层分解递归的每个步骤,这样只会越想越烦躁,就算大神也做不到这点哦。
- 递归算法优点:代码的表达力很强,写起来很简洁。
- 递归算法缺点:递归算法有堆栈溢出(爆栈)的风险、存在重复计算,过多的函数调用会耗时较多等问题(写递归算法的时候一定要考虑这几个缺点)、归时函数的变量的存储需要额外的栈空间,当递归深度很深时,需要额外的内存占空间就会很多,所以递归有非常高的空间复杂度。
递归算法使用场景(开篇提到的几个面试题)
写下面几道应用场景实战问题的时候,思想还是之前说的,再重复一遍(写出递归公式,找到终止条件)
1.经典走台阶问题
走台阶问题在前面已经具体讲了,这里就不再细说,可以看上面内容哦。
2.四级分销-找到最佳推荐人
给定一个用户,如何查找用户的最终推荐 id,这里面说了四级分销,终止条件已经找到,只找到 四级分销。
代码实现:
let deep = 0;
function findRootReferrerId(actorId) {
deep++;
let referrerId = select referrer_id from [table] where actor_id = actorId;
if (deep === 4) return actorId; // 终止条件
return findRootReferrerId(referrerId);
}
尽管可以这样完成了代码,但是还要注意前提:
- 数据库中没有
脏数据(脏数据可能是测试直接手动插入数据产生的,比如A推荐了B,B又推荐了A,造成死循环,循环引用)。 - 确认推荐人插入表中数据的时候,一定判断二者之前的推荐关系是否已经存在。
3.数组拍平
let a = [1,2,3, [1,2,[1.4], [1,2,3]]]
对于数组拍平有时候也会被这样问,这个嵌套数组的层级是多少?
具体实现代码如下:
function flat(a=[],result=[]){
a.forEach((item)=>{
console.log(Object.prototype.toString.call(item))
if(Object.prototype.toString.call(item)==='[object Array]'){
result=result.concat(flat(item,[]));
}else{
result.push(item)
}
})
return result;
}
console.log(flat(a)) // 输出结果 [ 1, 2, 3, 1, 2, 1.4, 1, 2, 3 ]
4.对象格式化
对象格式化这个问题,这种一般是后台返回给前端的数据,有时候需要格式化一下大小写等,一般层级不会太深,不需要考虑终止条件,具体看代码
// 格式化对象 大写变为小写
let obj = {
a: '1',
b: {
c: '2',
D: {
E: '3'
}
}
}
function keysLower(obj){
let reg = new RegExp("([A-Z]+)", "g");
for (let key in obj){
if(Object.prototype.hasOwnProperty.call(obj,key)){
let temp = obj[key];
if(reg.test(key.toString())){
temp = obj[key.replace(reg,function(result){
return result.toLowerCase();
})]= obj[key];
delete obj[key];
}
if(Object.prototype.toString.call(temp)==='[object Object]'){
keysLower(temp);
}
}
}
return obj;
}
console.log(keysLower(obj));//输出结果 { a: '1', b: { c: '2', d: { e: '3' } } }
5.实现一个深拷贝
const target = {
field1: 1,
field2: undefined,
field3: {
child: 'child'
},
field4: [2, 4, 8]
};
target.target = target;
代码实现如下:
function clone(target, map = new WeakMap()) {
if (typeof target === 'object') {
let cloneTarget = Array.isArray(target) ? [] : {};
if (map.get(target)) {
return map.get(target);
}
map.set(target, cloneTarget);
for (const key in target) {
cloneTarget[key] = clone(target[key], map);
}
return cloneTarget;
} else {
return target;
}
};
深拷贝也是递归常考的例子
每次拷贝发生的事:
- 检查 map 中有无克隆过的对象
- 有,直接返回
- 没有, 将当前对象作为 key,克隆对象作为 value 进行存储
- 继续克隆
在这段代码中我们使用了 weakMap ,用来防止因循环引用而出现的爆栈。
weakMap 补充知识
都知道js中有好多种数据存储结构,我们为什么要用 weakMap 而不直接用 Map 进行存储呢?
WeakMap 对象虽然也是一组键/值对的集合,其中的键是弱引用的。其键必须是对象,而值可以是任意的。
弱引用这个概念在写 java 代码时候用的还是比较多的,但是到了 javascript 能使用的小伙伴并不多,网上很多深拷贝的代码都是直接使用的 Map 存储防止爆栈-- 弱引用,看完这篇文章可以试着使用 WeakMap 哦。
在计算机程序设计中,弱引用与强引用相对,是指不能确保其引用的对象不会被垃圾回收器回收的引用。 一个对象若只被 弱引用 所引用,则被认为是不可访问(或弱可访问)的,并因此可能在任何时刻被回收。
深拷贝这里有一个循环引用 走台阶问题是重复计算,我认为这是两个问题,走台阶问题是靠终止条件计算出来的。
总结
本篇文章就写到这里,其实还有复杂度问题想写,但是篇幅有限,以后有时间会单独写复杂度的文章。本篇文章重点再重复一篇,不要嫌弃我唠叨,什么条件使用递归(想一下使用递归的优缺点)?递归代码怎么写?递归注意事项?不要妄图用人脑想明白复杂递归。以上几点学明白了足以让你应付大多数的面试问题了,嘿嘿,注意思想哦(还有个 weakMap 小知识大家可以详细去学下,也是可以扩展为一篇文章的)。小伙伴们有时间可以去找几个递归问题练习一下。下篇文章见!
参考文章
参考文章
- 天明夜尽:https://juejin.im/post/5d1dab346fb9a07ec63b3249
- code秘密花园:https://juejin.im/post/5d6aa4f96fb9a06b112ad5b1
- 极客时间的递归学习
程序员成长指北(ID:coder_growth)
作者:koala 专注完整的 Node.js 技术栈分享,从 JavaScript 到
Node.js,再到后端数据库,祝您成为优秀的高级Node.js 工程师
文章同步到github博客:https://github.com/koala-coding/goodBlog
共同学习,写下你的评论
评论加载中...
作者其他优质文章


