
prometheus的小缺陷
prometheus在数据量少的时候可以很快搭建起一套监控系统,但是呢,当数据量上来的时候就必须做水平的业务切割,伴随着业务量变大,紧跟的问题也就来了。
- 查询时间有限。prometheus数据保存在本地毕竟是有限的空间,我们不可能查询特别久的时间,主要是本地的磁盘有限。
- 查询范围有限。prometheus只能查询他自己抓取的数据,当我们的数据是由两个prometheus分别抓取的时候,这样就无法选出两个集群的topk这种,也无法跨越prometheus进行聚合操作。
- 告警范围有限。告警这个查询是一个问题,prometheus的告警是通过定时轮训做的,查不到的情况无法进行告警。
thano
针对以上的问题,thanos的解决方案出现了。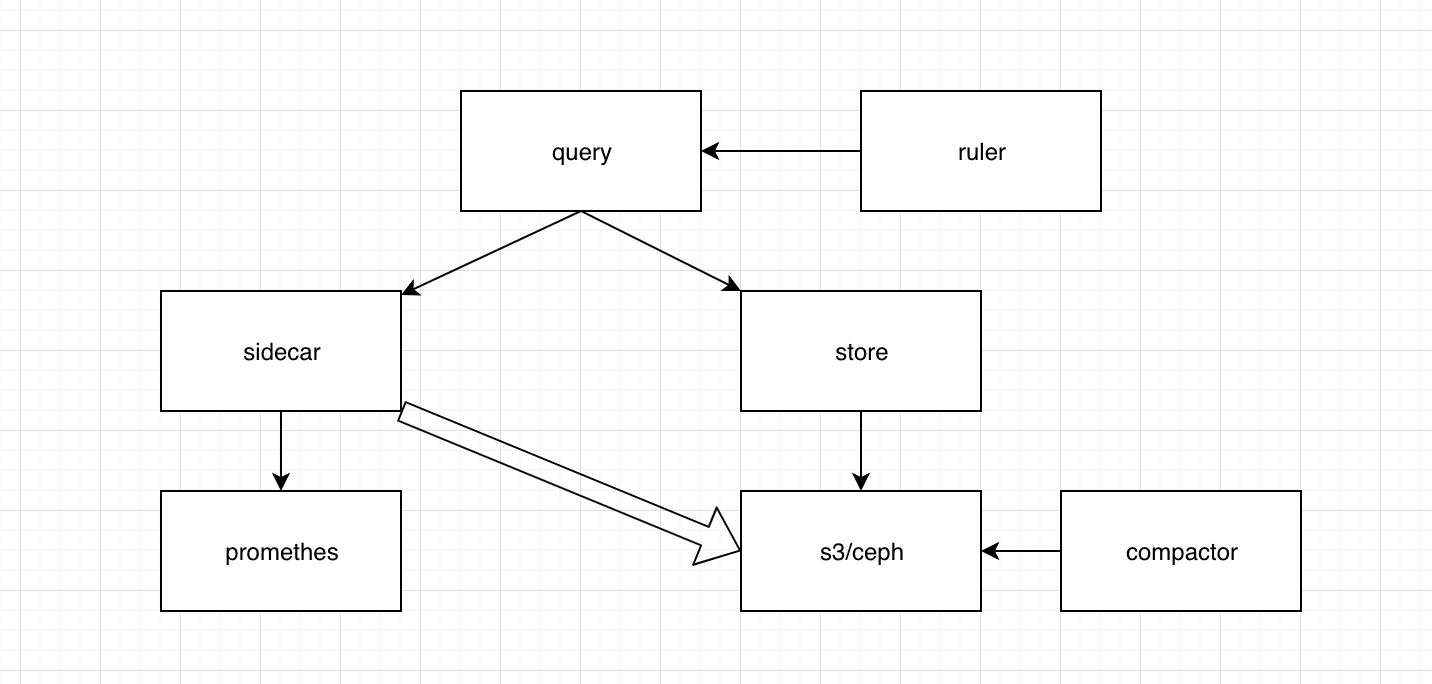
以上是一个thanos的整体结构和流程,我们下面来分析,thanos是如何解决以上问题的。
- sidecar
抓取依旧是prometheus来做,有一个sidecar组件,他的作用有两个,一个是代理prometheus提供查询,一个是把prometheus已经合成块的数据搬入其他高可用文件存储系统,例如上面的s3,ceph等。
sidecar把数据存入ceph等文件存储系统,就解决了文件存储的问题,数据可以保存的更久。 - store
文件已经存入了其他文件存储系统,那么需要提供查询的功能,这里有store组件来做,可以设置时间切面,store组件用来查询高可用文件系统中的数据。这样解决了存储和存储查询的问题了。 - query
query是查询的分发和数据的合并组件。他负责和查询的请求发给所有的store和sidecar,然后各个组件会把查询结果返回给query。最终query提供了查询结果出去。这里需要注意的是发送给所有的store和sidecar。这里就解决了多个prometheus抓取后查询不到的问题。现在query会把多个prometheus的数据进行合并。 - ruler
ruler组件是用来做全局告警的,解决的就是上面提出的prometheus的告警问题。ruler基于query进行查询。 - compactor
prometheus本身是有压缩的功能的,在和thanos配合的时候必须关闭。由compactor组件进行压缩和下采样。以此节省一部分存储,并且通过下采样提供更快捷的查询能力。
小结
看到thanos的结构,就可以发现thanos的主要的设计思路就是把prometheus的功能组件化,集群化。
查询的时候利用query对多个组件进行数据的查询合并,这里主要是把提供数据的地方都查询了一遍,代表本地磁盘的是prometheus提供的,sidecar组件代理,代表高可用存储的是store。
ruler就直接调用query。query查询的功能齐全,ruler就是直接把prometheus的告警逻辑搬出来单独成一个组件。
compactor也是一样,压缩和下采样功能直接组件化。
点击查看更多内容
1人点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中




感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦