
们整个 DevOps 流程是建立在容器编排的基础上的,目的是简化流程和实现自动化 CI/CD 和自动化运维。当中会有很多没有想到的地方,可能也不太适用于复杂场景。
随着 DevOps 和 SRE 概念的流行,越来越多的 developer 和 operater 们摒弃传统的开发部署流程,转向了如下图所示的无线循环模式:
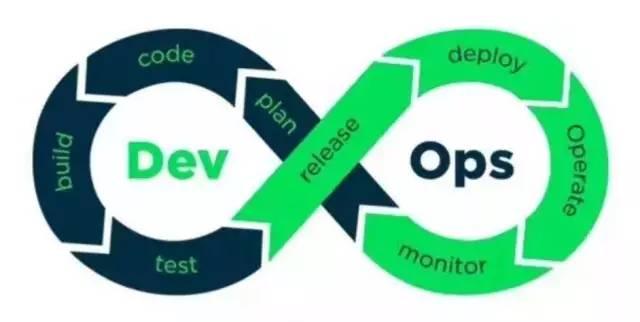
在我理解 DevOps 包含三个大块:敏捷开发(Agile)、持续集成与交付(CI/CD)、自动运维(ITSM)。
在容器化的时代,我们是如何实现 DepOps 或者 SRE 的呢?下面我就来分享一下沪江学习产品线团队基于容器编排的 DevOps 流程。
敏捷开发
大道至简,所有血的教训告诉我们,不要把简单的事情复杂化。换句话说,不要用复杂的方法处理简单的事情。我对敏捷的理解是「快」和「微」。快指迭代快,开发快,上线快,性能快。微指微服务、微镜像。围绕这两点,在开发阶段我们需要做以下几件事:
应用微服务化
这是个比较大的概念,不在这里讨论,有兴趣可以参考我的其他文章。但只有应用小了,才有可能快起来。
给 Docker 镜像瘦身
为了让 Docker 启动和运行得快,首先就是要对 Docker 瘦身。由于所有的应用全部会统一为 Java 语言开发,所以我们以 Java 为例,选用了 jre-alpine 作为我们的基础镜像,下面是 Dockerfile 的例子:
FROM java:8-jre-alpineadd timezone and default it to ShanghaiRUN apk --update add --no-cache tzdataENV TZ=Asia/ShanghaiRUN mkdir -p /app/logCOPY ./target/xxx.jar /app/xxx.jarEXPOSE 9999VOLUME ["/app/log"]WORKDIR /app/ENTRYPOINT ["java","-Xms2048m", "-Xmx2048m", "-Xss512k", "-jar","xxx.jar"]CMD []
使用上述 Dockerfile 生成的镜像平均只有 80 多 MB,启动时间几乎在 5 秒内。使用 Alpine 镜像虽然减小了体积,但缺少一些工具命令,例如 curl 等,可以根据需要酌情安装。另外遇到的一个坑是时区问题:由于 Docker 镜像内的时区是 UTC 时间,和宿主机的东 8 区不一致,所以必须安装 timezone 工具并设置 TZ,才能使容器内时间和宿主机保持一致,对数据库的写入和日志的输出都是非常必要的一环。
把所有环境配置包含在镜像中
早在虚拟机时代,我们已经做到了使用包含依赖的虚拟机镜像来加速部署,那么为什么要止步于此呢?我们可以更进一步,把服务本身也包含在镜像中,Docker 用了更轻量的方式已经实现了这一点。
这里我们还要介绍一个概念,要让制作的镜像,能在所有安装了 Docker 的服务器上运行,而不在乎宿主机的操作系统及环境。借用 Java 的一句话来说:一次制作,多平台运行。所以,我们还会把所有环境的配置文件,以不同的文件名全部放入镜像中,通过参数来选择 Docker 启动时使用的环境配置文件。
值得注意的是,如果开发的应用是基于 Spring 框架的话,这个功能很好实现。但如果是其他语言开发,会有一定的开发量。
本文以默认 Java 开发当所有的开发工作完成后,推荐程序目录结构是这样的:
│ ├── main│ │ ├── java│ │ ├── resources│ │ │ ├── application.yaml│ │ │ ├── application-dev.yaml│ │ │ ├── application-qa.yaml│ │ │ ├── application-yz.yaml│ │ │ ├── application-prod.yaml│ │ │ ├── logback.xml│ ├── test├── scripts│ ├── Dockerfile│ ├── InitDB.sql├── pom.xml
持续集成与交付
自动化的持续集成和交付在整个 DevOps 流中起了重要的角色,他是衔接开发和运维的桥梁。如果这一环做的不好,无法支撑大量微服务的快速的迭代和高效运维。在这一环节,我们需要灵活的运用工具,尽量减少人参与,当然仍然需要围绕「快」和「微」做文章。
如何减少人工参与到持续集成与持续交付呢?我们最希望的开发过程是:对着计算机说出我们的想要的功能,计算机按照套路,自动编码,自动发布到测试环境,自动运行测试脚本,自动上线。当然,目前时代要实现自动编码的过程还需要发明那只「猫」。
但只要对测试有足够信心,我们完全可以实现一种境界:在炎热的下午,轻松地提交自己编写的代码,去休息室喝杯咖啡,回来后看见自己的代码已经被应用在生产环境上了。在容器时代,我们可以很快速的实现这一梦想,其具体步骤如下图:
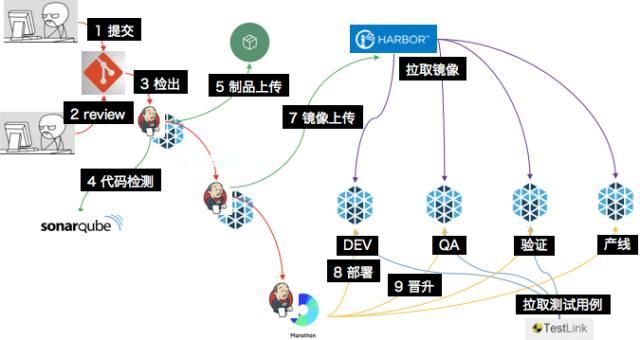
Gitfolw 与 Anti-Gitflown
持续集成的第一步是提交代码(Code Commit),VCS 也由 CVS,SVN 进化到如今的 Git,自然不得不说一下 Gitflow。谈起无人不晓的 Gitflow,大家一定会大谈其优点:支持多团队,设置多国家的开发人员并行开发,减小代码冲突或脏代码的上线概率。它的大致流程如下:
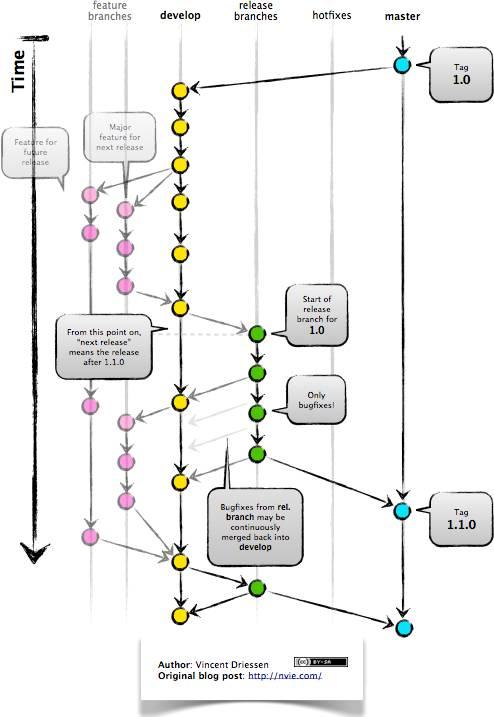
Gitflow 给我们展示了复杂团队在处理不通代码版本的优雅解决方案,它需要feature、develop、release、hotfix、master 5 条分支来处理不同时段的并行开发。但这真的合适于一个不超过 20 人的本地合作团队开发吗?我们的开发团队不足 6 人,每个人负责 3 个以上的微服务,几乎不可能在同个项目上安排两个以上的同学并行开发。
在初期我们准守规定并使用标准的 Gitflow 流程,开发人员立刻发现一个问题,他们需要在至少 3 条分支上来回的 merge 代码,且不会有任何代码冲突(因为就一个人开发),降低了开发的效率。这让我意识到,Gitflow 模式也许并不适合于小团队微服务的世界,一种反 Gitflow 模式的想法出现在脑海中。我决定对Gitflow 进行瘦身,化繁至简。
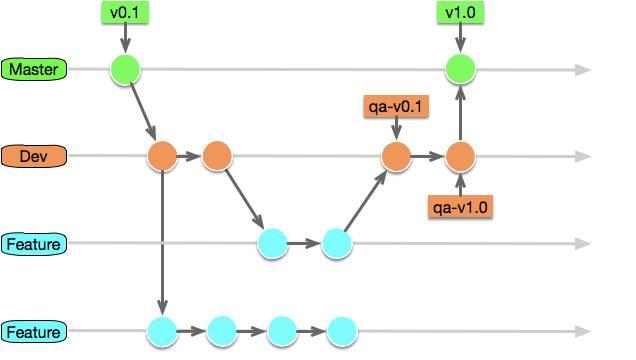
我们把 5 条分支简化为 3 条分支,其中 Master 分支的作用只是维护了最新的线上版本的作用,Dev 分支为开发的主要分支,所有的镜像是以此分支的代码为源头生成的。这时开发的过程变为:
开发人员从 Dev 分支中 checkout 新的 feature 分支,在 feature 分支上进行开发
当开发完成后 merge 回 Dev 分支中,根据 Dev 分支的代码打成镜像,部署 QA 环境交给 QA 人员测试
测试中如有 bug 便在新分支中修复问题循环步骤 2
测试完成 merge 回 Master 分支
如此一来,只有从 Feature 把代码 merge 到 Dev 分支的一次 merge 动作,大大提升可开发效率。
使用Jenkins Pipeline
Jenkins 作为老牌 CI/CD 工具,能够帮我们自动化完成代码编译、上传静态代码分析、制作镜像、部署测试环境、冒烟测试、部署上线等步骤。尤其是Jenkins 2.0 引入 Pipeline 概念后,以上步骤变的如此行云流水。它让我们从步骤 3 开始,完全可以无人值守完成整个集成和发布过程。
工欲善其事必先利其器,首先我们必须要在 Jenkins 上安装插件 :
Pipeline Plugin(如果使用Jenkins2.0默认安装)
Git
Sonar Scaner
Docker Pipeline Plugin
Marathon
如果你第一次接触 Jenkins Pipeline,可以从https://github.com/jenkinsci/p ... AL.md找到帮助。
现在,我们开始编写 Groove 代码。基于容器编排的 Pipeline 分为如下几个步骤:
1、检出代码
这个步骤使用 Git 插件,把开发好的代码检出。
stage('Check out')gitUrl = "git@gitlab.xxxx.com:xxx.git"git branch: "dev", changelog: false, credentialsId: "deploy-key", url: gitUrl2、Maven 构建 Java 代码
由于我们使用的是 Spring Boot 框架,生成物应该是一个可执行的 jar 包。
stage('Build')sh "${mvnHome}/bin/mvn -U clean install"3、静态代码分析
通过 Sonar Scaner 插件,通知 Sonar 对代码库进行静态扫描。
stage('SonarQube analysis')// requires SonarQube Scanner 2.8+def scannerHome = tool 'SonarQube.Scanner-2.8';withSonarQubeEnv('SonarQube-Prod') { sh "${scannerHome}/bin/sonar-scanner -e -Dsonar.links.scm=${gitUrl} -Dsonar.sources=. -Dsonar.test.exclusions=file:**/src/test/java/** -Dsonar.exclusions=file:**/src/test/java/** -Dsonar.language=java -Dsonar.projectVersion=1.${BUILD_NUMBER} -Dsonar.projectKey=lms-barrages -Dsonar.projectDescription=0000000-00000 -Dsonar.java.source=8 -Dsonar.projectName=xxx"}4、制作 Docker 镜像
此步骤会调用 Docker Pipeline 插件通过预先写好的 Dockerfile,把 jar 包和配置文件、三方依赖包一起打入 Docker 镜像中,并上传到私有 Docker 镜像仓库中。
stage('Build image')docker.withRegistry('https://dockerhub.xxx.com', 'dockerhub-login') {docker.build('dockerhub.xxx.com/xxxx').push('test') //test是tag名称}5、部署测试环境
通过事先写好的部署文件,用 Marathon 插件通知 Marathon 集,在测试环境中部署生成好的镜像。
stage('Deploy on Test')sh "mkdir -pv deploy"dir("./deploy") { git branch: 'dev', changelog: false, credentialsId: 'deploy-key', url: 'git@gitlab.xxx.com:lms/xxx-deploy.git' //Get the right marathon url marathon_url="http://marathon-qa" marathon docker: imageName, dockerForcePull: true, forceUpdate: true, url: marathon_url, filename: "qa-deploy.json"}6、自动化测试
运行事先测试人员写好的自动化测试脚本来检验程序是否运行正常。
stage('Test')// 下载测试用例代码git branch: 'dev', changelog: false, credentialsId: 'deploy-key', url: 'git@gitlab.xxx.com:lms/xxx-test.git'parallel(autoTests: { // 使用nosetests 运行测试用例 sh "docker run -it --rm -v $PWD:/code nosetests nosetests -s -v -c conf unapi_test.cfg --attr safeControl=1"},manualTests:{ sleep 30000})7、人工测试
如果对自动化测试不放心,此时可选择结束 Pipeline,进行人工测试。为了说明整个流程,我们这里选择跳过人工测试环节。
8、部署生产环境
当所有测试通过后,Pipeline 自动发布生产环境。
stage('Deploy on Prod')input "Do tests OK?"dir("./deploy") { //Get the right marathon url marathon_url="http://marathon-prod" marathon docker: imageName, dockerForcePull: true, forceUpdate: true, url: marathon_url, filename: "prod-deploy.json"}最后我们来看看整个 Pipeline 的过程:
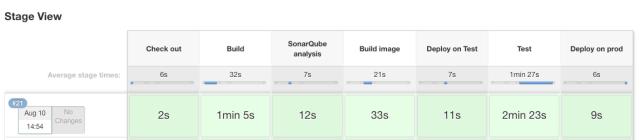
容器编排配置文档化
在介绍敏捷开发时,曾介绍过根据不同环境的配置参数部署到不同的环境。如何告知部署程序用什么样的配置文件启动服务,每个环境又用多少 CPU,内存和 instance 呢?
下面我们就来介绍一下容器编排的配置文件。由于我们使用 Mesos+Marathon的容器编排方式,部署的重任从以前的写部署脚本变成了写一个 Marathon 的配置,其内容如下:
{"id": "/appName","cpus": 2,"mem": 2048.0,"instances": 2,"args": ["--spring.profiles.active=qa"],"labels": {"HAPROXY_GROUP": "external","HAPROXY_0_VHOST": "xxx.hujiang.com"},"container": {"type": "DOCKER","docker": { "image": "imageName", "network": "USER", "forcePullImage": true, "portMappings": [ { "containerPort": 12345, "hostPort": 0, "protocol": "tcp", "servicePort": 12345 } ]},"volumes": [ { "containerPath": "/app/log", "hostPath": "/home/logs/appName", "mode": "RW" }]},"ipAddress": {"networkName": "calico-net"},"healthChecks": [{ "gracePeriodSeconds": 300, "ignoreHttp1xx": true, "intervalSeconds": 20, "maxConsecutiveFailures": 3, "path": "/health_check", "portIndex": 0, "protocol": "HTTP", "timeoutSeconds": 20}],"uris": ["file:///etc/docker.tar.gz"]}我们把这个配置内容保存为不同的 Json 文件,每个对应的环境都有一套配置文件。例如 Marathon-qa.json,Marathon-prod.json。当 Pipeline 部署时,可以通过Jenkins Marathon 插件,根据选择不同的环境,调用部署配置,从而达到自动部署的目的。
自动化流程和部署上线分离与管理
开发部署如此的简单快捷,是不是每个人都能方便的使用呢?答案是否定的,并不是因为技术上有难度,而是在于权限。在理想的情况下,通过这套流程的确可以做到在提交代码后,喝杯咖啡的时间就能看见自己的代码已经被千万用户使用了。
但风险过大,我们并不是每个人都能像 Rambo 一样 bug 的存在,大多数的情况还需要使用规范和流程来约束。就像自动化测试取代不了人工黑盒测试一样,部署测试后也不能直接上生产环境,在测试通过后还是需要有个人工确认和部署生产的过程。
所以我们需要把自动化流程和最后的部署上线工作分开来,分别变成两个 Job,并给后者单独分配权限,让有权限的人来做最后的部署工作。这个人可以是 Team leader、开发经理,也可以是运维伙伴,取决于公司的组织结构。
那这个部署的 Job 具体干什么呢?在容器编排时代,结合镜像既构建物的思想,部署 Job 不会从代码编译开始工作,而是把一个充分测试且通过的镜像版本,通过 Marathon Plugin 部署到产线环境中去。这里是 Deploy_only 的例子:
node('docker-qa'){if (ReleaseVersion ==""){ echo "发布版本不能为空" return}stage "Prepare image" def moduleName = "${ApplicationModule}".toLowerCase() def resDockerImage = imageName + ":latest" def desDockerImage = imageName + ":${ReleaseVersion}" if (GenDockerVersion =="true"){ sh "docker pull ${resDockerImage}" sh "docker tag ${resDockerImage} ${desDockerImage}" sh "docker push ${desDockerImage}" sh "docker rmi -f ${resDockerImage} ${desDockerImage}" }stage "Deploy on Mesos" git branch: 'dev', changelog: false, credentialsId: 'deploy-key', url: 'git@gitlab.xxx.com:lms/xxx-test.git' //Get the right marathon url echo "DeployDC: " + DeployDC marathon_url = "" if (DeployDC=="AA") { if (DeployEnv == "prod"){ input "Are you sure to deploy to production?" marathon_url = "${marathon_AA_prod}" }else if (DeployEnv == "yz") { marathon_url = "${marathon_AA_yz}" } }else if ("${DeployDC}"=="BB"){ if ("${DeployEnv}" == "prod"){ input "Are you sure to deploy to production?" marathon_url = "${marathon_BB_prod}" }else if ("${DeployEnv}" == "yz") { marathon_url = "${marathon_BB_yz}" } } marathon docker: imageName, dockerForcePull: true, forceUpdate: true, url: marathon_url, filename: "${DeployEnv}-deploy.json"}为什么不把这个文件跟随应用项目一起放到 scripts 下呢?因为把部署和应用分开后,可以由两拨人进行维护,兼顾公司的组织架构。
在 DevOps 的最后阶段是运维阶段。在容器时代,如何对庞大的镜像制品进行运维呢?我们的目标是尽量实现自动化运维,这里主要讲述两点:
容器的监控
容器的监控大致有两种方式:物理机上安装其他服务监控本机上的所有容器;通过 Mesos 或 Kubernates 自带 API 监控容器状态。两种方式其实都需要在物理机上安装相应的监控软件或 Agent。
在我们团队目前使用 cAdvisor + InfluxDB + Grafana 的组合套件实现对容器的监控。
首先需要在 Mesos 集中所有的 Agent 安装 cAdvisor 。他负责把宿主机上所有运行中的容器数据以数据点(data point)形式发送给时序数据库(InfluxDB),下面是 cAdvisor 监控的一些数据点:
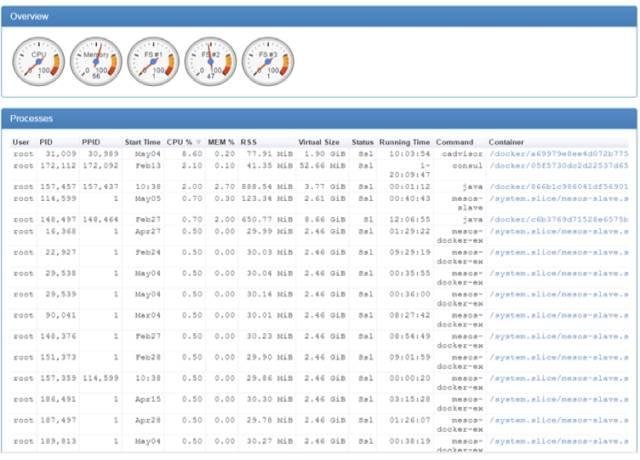
这些数据点经过 Grafana 整理,展示在界面上,这样我们就能掌握具体容器的性能指标了。下面是一个 Grafana 的截图:
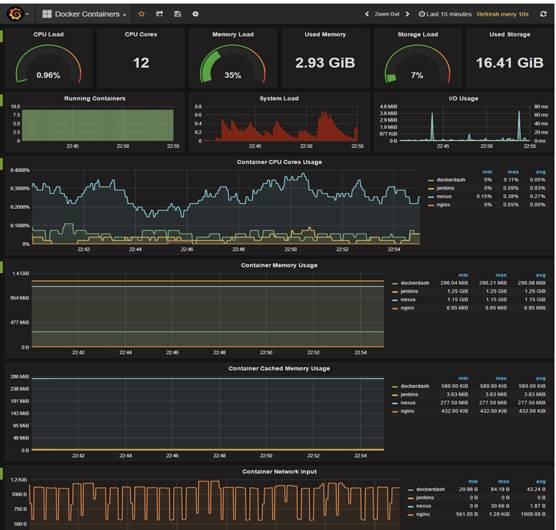
除了对容器本身的监控,宿主机的监控也是必不可少的。由于监控的点有很多,这里不一一例举。
自动伸缩
有了监控指标只是实现了自动化运维的第一步,当业务请求发生大量增加或减少,通过人工监测是不能及时的进行相应的,况且还不一定有那么多的人,7×24 小时的监控。一定需要有一套根据监控数据自行伸缩容的机制。在学习产品线,我们针对容器编排的 Mesos+Marathon 框架,开发了一套针对应用本身的自动扩容微服务。其原理如下:
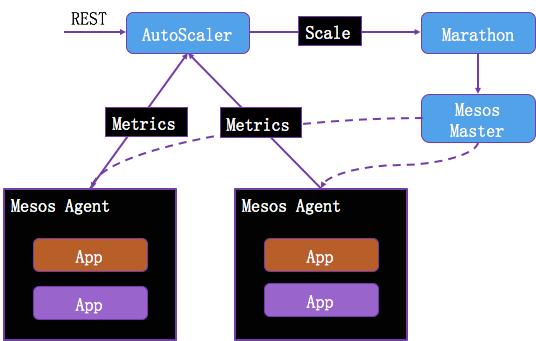
通过 Restful 的接口通知 AutoScaler 程序需要监控的应用服务。
AutoScaler 程序开始读取每台 Agent 上部署相关应用的 Metrics 数据,其中包括 CPU,内存的使用状况。
当发现有应用过于繁忙(其表现形式大多是 CPU 占用过高或内存占用过大)时调用 Marathon API 将其扩容
Marathon 收到消息后,立刻通知 Mesos 集发布新的应用,从而缓解当前的繁忙状况。
结束语
DevOps 和 SRE 并不是一个渴望而不可及的概念,它们需要在不同的环境中落地。我们整个 DevOps 流程是建立在容器编排的基础上的,目的是简化流程和实现自动化 CI/CD 和自动化运维。当中会有很多没有想到的地方,可能也不太适用于复杂场景。其次,本文中的例子也做了相应的隐私处理,可能无法直接使用。希望大家能通过我们在实践中产生的成功和遇到的问题,提炼出适合自己的 DevOps 流程。
作者:烂猪皮
来源:https://my.oschina.net/u/3636867/blog/1789575
共同学习,写下你的评论
评论加载中...
作者其他优质文章


