
一.IMDB数据集
关于数据集的描述:
官网译文: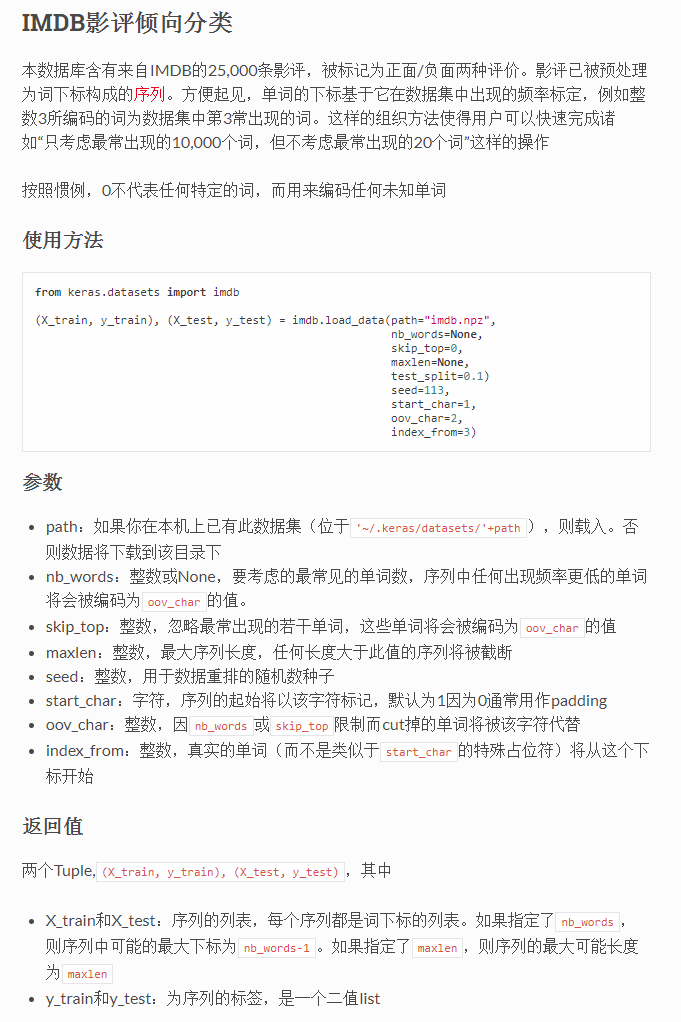
kaggle的IMDB数据集提供了一个CSV文件,而keras自带的那个数据源没有。看kaggle的CSV文件:
第二栏,第一条评论的内容:
" Once again Mr. Costner has dragged out a movie for far longer than necessary. Aside from the terrific sea rescue sequences, of which there are very few I just did not care about any of the characters. Most of us have ghosts in the closet, and Costner’s character are realized early on, and then forgotten until much later, by which time I did not care. The character we should really care about is a very cocky, overconfident Ashton Kutcher. The problem is he comes off as kid who thinks he’s better than anyone else around him and shows no signs of a cluttered closet. His only obstacle appears to be winning over Costner. Finally when we are well past the half way point of this stinker, Costner tells us all about Kutcher’s ghosts. We are told why Kutcher is driven to be the best with no prior inkling or foreshadowing. No magic here, it was all I could do to keep from turning it off an hour in."
————————————————
为了 让算法进行处理,首先将评论内容转换为词向量,也就是WordEmbedding
首先要有一个字典,字典有固定的长度,字典囊括了数据集中出现的词,词在字典中的位置按照词在数据集中出现的次数从大到小排列。比如这个字典中,‘the’在评论中出现次数最大,the放在字典的第一个位置上;‘and’出现的次数第二多,所以排在第二 …
字典参见下面的 imdb.vocab文件
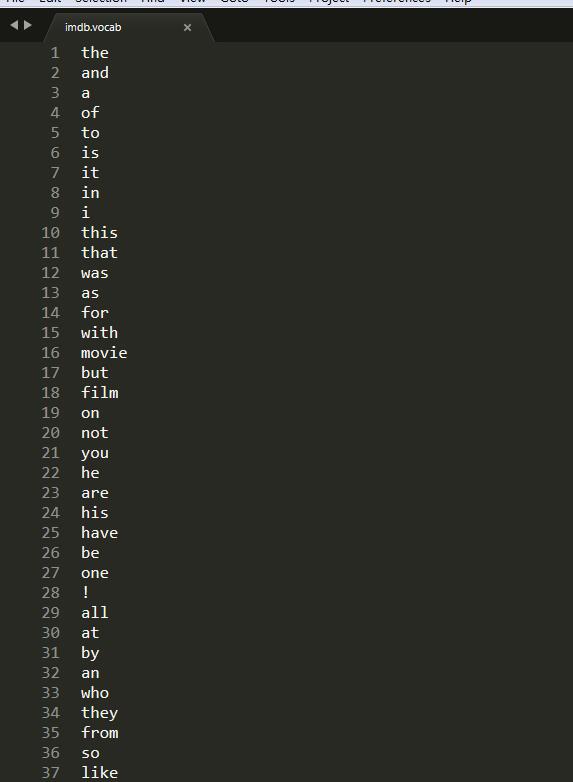
有了字典,给定一个词,就能找到它在字典中的位置。比如评价中出现了单词a,在字典中a的位置为3;评论中出现的词在字典中不存则为0。所谓词向量就是把每个词用其在字典中的index来表示。每一个评论都将会构造一个对应长度的词向量。
举个栗子:
评论为“I like this movie!”
‘I’在字典中的index为9;
‘like’在字典中的index为37;
‘this’‘在字典中的index为10;
‘movie’在字典中的index为16;
‘!’在字典中的index为28;
这个评论对应的词向量为[9 37 10 16 28]
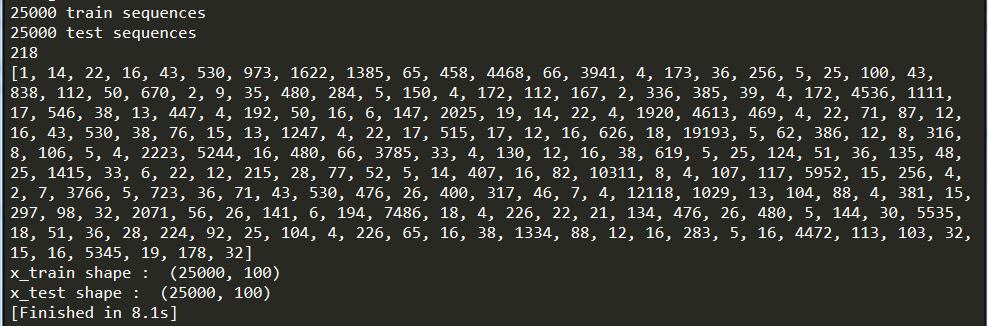
Demo1,查看IMDB数据
# coding=utf-8
from keras.datasets import imdb
from keras.preprocessing import sequence
max_features = 20000
maxlen = 100
embedding_size = 128
(x_train,y_train),(x_test,y_test) = imdb.load_data(num_words = max_features)
print(len(x_train),'train sequences')
print(len(x_test),'test sequences')
print(len(x_train[0]))
print(x_train[0])
#设定向量的最大长度,小于这个长度的补0,大于这个长度的截断
x_train = sequence.pad_sequences(x_train,maxlen = maxlen)
x_test = sequence.pad_sequences(x_test,maxlen = maxlen)
print('x_train shape : ',x_train.shape)
print('x_test shape : ',x_test.shape)
分类算法:
1.TextCNN ;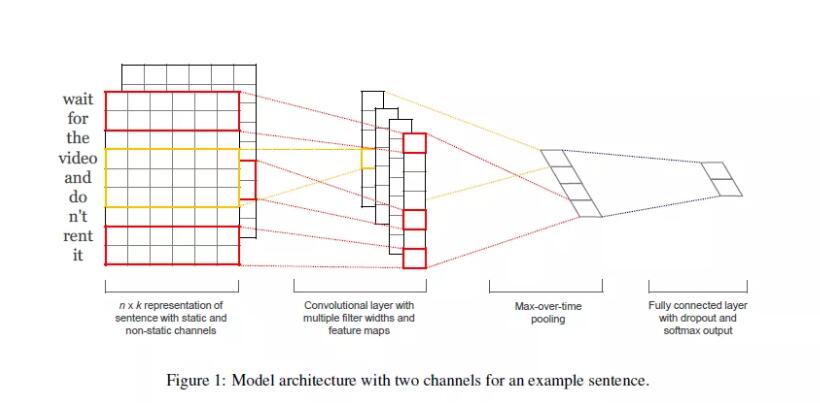


2.TextRNN(GRU版)

代码实现 :
环境参数:
Python 3.6
NumPy 1.15.2
Keras 2.2.0
Tensorflow 1.8.0
Demo1:TextCNN :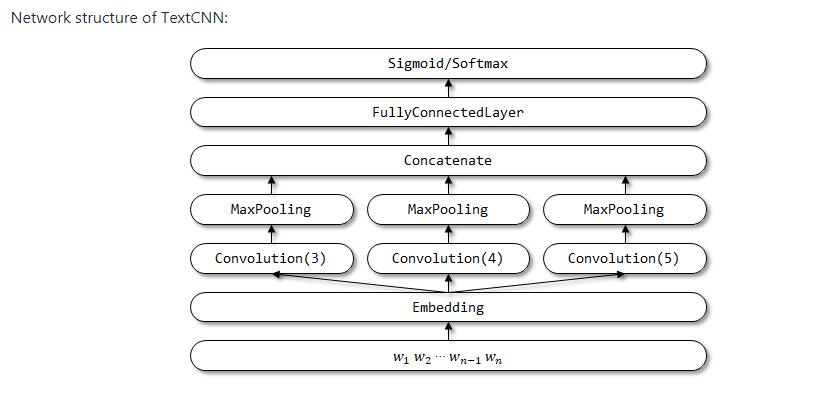
Text_cnn.py:
# coding=utf-8
from keras import Input, Model
from keras.layers import Embedding, Dense, Conv1D, GlobalMaxPooling1D, Concatenate, Dropout
class TextCNN(object):
def __init__(self, maxlen, max_features, embedding_dims,
class_num=1,
last_activation='sigmoid'):
self.maxlen = maxlen
self.max_features = max_features
self.embedding_dims = embedding_dims
self.class_num = class_num
self.last_activation = last_activation
def get_model(self):
input = Input((self.maxlen,))
# Embedding part can try multichannel as same as origin paper
embedding = Embedding(self.max_features, self.embedding_dims, input_length=self.maxlen)(input)
convs = []
for kernel_size in [3, 4, 5]:
c = Conv1D(128, kernel_size, activation='relu')(embedding)
c = GlobalMaxPooling1D()(c)
convs.append(c)
x = Concatenate()(convs)
output = Dense(self.class_num, activation=self.last_activation)(x)
model = Model(inputs=input, outputs=output)
return model
main.py:
# coding=utf-8
from keras.callbacks import EarlyStopping
from keras.datasets import imdb
from keras.preprocessing import sequence
from Text_cnn import TextCNN
max_features = 5000
maxlen = 400
batch_size = 32
embedding_dims = 50
epochs = 10
print('Loading data...')
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)
print(len(x_train), 'train sequences')
print(len(x_test), 'test sequences')
print('Pad sequences (samples x time)...')
x_train = sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = sequence.pad_sequences(x_test, maxlen=maxlen)
print('x_train shape:', x_train.shape)
print('x_test shape:', x_test.shape)
print('Build model...')
model = TextCNN(maxlen, max_features, embedding_dims).get_model()
model.compile('adam', 'binary_crossentropy', metrics=['accuracy'])
print('Train...')
early_stopping = EarlyStopping(monitor='val_acc', patience=3, mode='max')
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
callbacks=[early_stopping],
validation_data=(x_test, y_test))
print('Test...')
result = model.predict(x_test)
运行结果: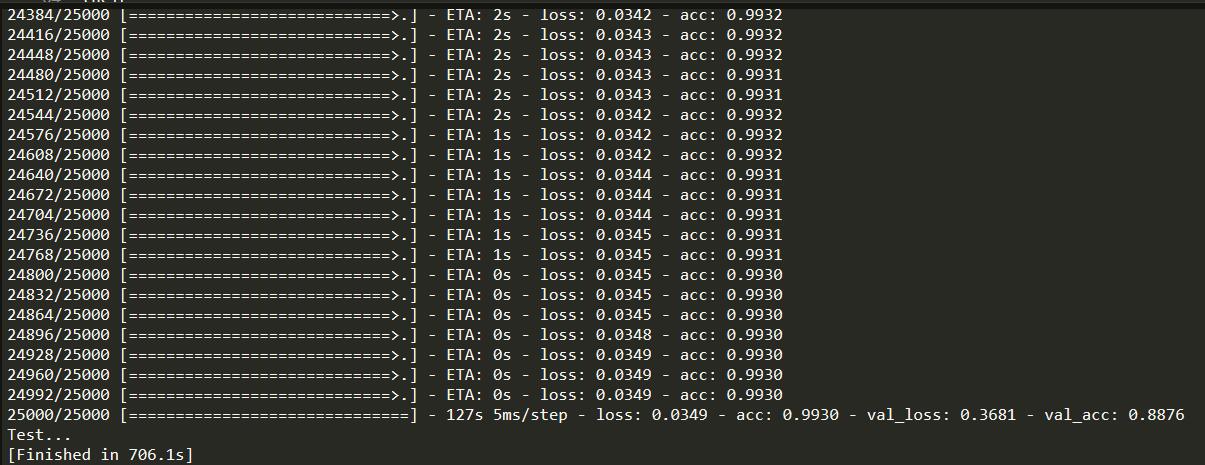
Demo2:TextRNN :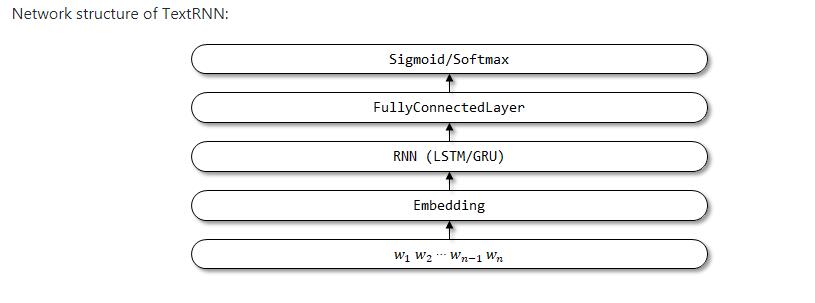
Text_rnn.py:
# coding=utf-8
from keras import Input, Model
from keras.layers import Embedding, Dense, Dropout, LSTM
class TextRNN(object):
def __init__(self, maxlen, max_features, embedding_dims,
class_num=1,
last_activation='sigmoid'):
self.maxlen = maxlen
self.max_features = max_features
self.embedding_dims = embedding_dims
self.class_num = class_num
self.last_activation = last_activation
def get_model(self):
input = Input((self.maxlen,))
embedding = Embedding(self.max_features, self.embedding_dims, input_length=self.maxlen)(input)
x = LSTM(128)(embedding) # LSTM or GRU
output = Dense(self.class_num, activation=self.last_activation)(x)
model = Model(inputs=input, outputs=output)
return model
main.py:
# coding=utf-8
from keras.callbacks import EarlyStopping
from keras.datasets import imdb
from keras.preprocessing import sequence
from Text_rnn import TextRNN
max_features = 5000
maxlen = 400
batch_size = 32
embedding_dims = 50
epochs = 10
print('Loading data...')
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)
print(len(x_train), 'train sequences')
print(len(x_test), 'test sequences')
print('Pad sequences (samples x time)...')
x_train = sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = sequence.pad_sequences(x_test, maxlen=maxlen)
print('x_train shape:', x_train.shape)
print('x_test shape:', x_test.shape)
print('Build model...')
model = TextRNN(maxlen, max_features, embedding_dims).get_model()
model.compile('adam', 'binary_crossentropy', metrics=['accuracy'])
print('Train...')
early_stopping = EarlyStopping(monitor='val_acc', patience=3, mode='max')
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
callbacks=[early_stopping],
validation_data=(x_test, y_test))
print('Test...')
result = model.predict(x_test)
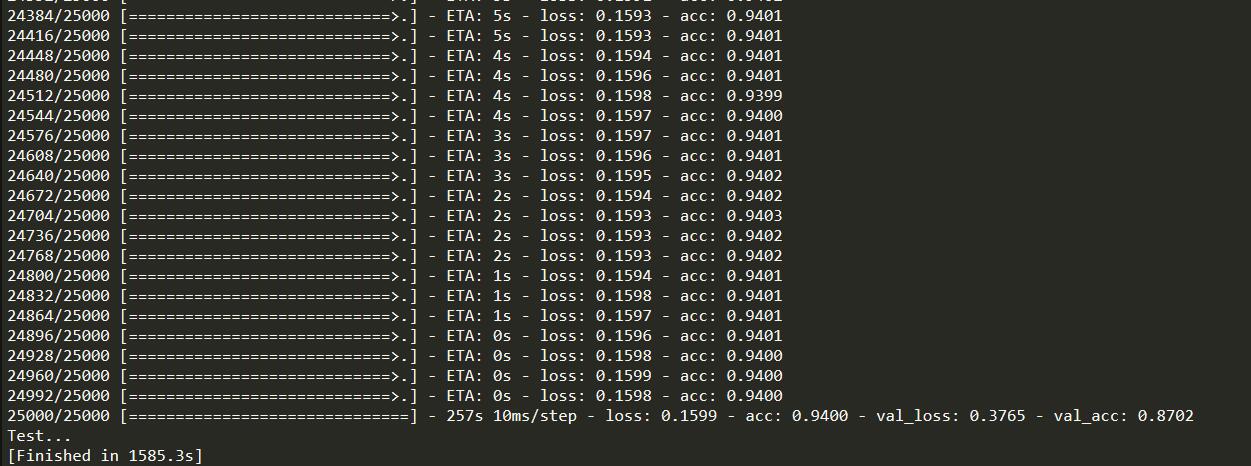
运行结果:
共同学习,写下你的评论
评论加载中...
作者其他优质文章



