
数据集地址: :https://pan.baidu.com/s/10yCWxYrgknZBsz6BX7JWsw 密码:3mq1
一,词表与字典封装
import sys
import os
import jieba
import tensorflow as tf
import numpy as np
import pandas as pd
import math
#tf打印日志
#tf.logging.set_verbosity(tf.logging.INFO)
train_file = "./Data/cnews.train.txt"
val_file = "./Data/cnews.val.txt"
test_file = "./Data/cnews.test.txt"
#分词结果
seg_train_file = "./Data/cnews.train.seg.txt"
seg_val_file = "./Data/cnews.val.seg.txt"
seg_test_file = "./Data/cnews.test.seg.txt"
#词典
vocab_file = "./Data/cnews.vocab.txt"
category_file = "./Data/cnews.category.txt"
#1.分词
def generate_seg_file(input_file,output_seg_file):
with open(input_file,'r',encoding='utf-8') as f:
lines = f.readlines()
with open(output_seg_file,'w',encoding='utf-8') as f:
for line in lines:
label,content = line.strip('\r\n').split('\t')
word_iter = jieba.cut(content)
#删除jieba中的空格
word_content = ''
for word in word_iter:
word = word.strip(' ')
if word != '':
#如果不为空,则合并
word_content += word + ' '
out_line = '%s\t%s\n' % (label,word_content.strip(' '))
f.write(out_line)
# f.write(out_line) 前面decode成utf-8,后面就需要encode成utf-8
#调用方式
#generate_seg_file(train_file,seg_train_file)
#generate_seg_file(val_file,seg_val_file)
#generate_seg_file(test_file,seg_test_file)
#2.生成字典并计算词频
def generate_vocab_file(input_seg_file,output_vocab_file):
with open(input_seg_file,'r',encoding='utf-8') as f:
lines = f.readlines()
word_dict = {}
for line in lines:
label , content = line.strip('\r\n').split('\t')
for word in content.split():
word_dict.setdefault(word,0) #没有这个词时,默认词频为0
word_dict[word] += 1
#按词频排序
#sorted_word_dict中每个元素都是一个元组:(word,frequency)
#key = lambda d: d[1] ,按第二个元素(词频)排序,d[1]就是词频
sorted_word_dict = sorted(word_dict.items(), key = lambda d:d[1],reverse = True)
with open(output_vocab_file,'w',encoding='utf-8') as f:
f.write('<Unknown>\t66666666\n') #找不到这个词时,用<Unknown>代替,默认词频为66666666
for item in sorted_word_dict:
f.write('%s\t%d\n' % (item[0].encode('utf-8'), item[1]))
#generate_vocab_file(seg_train_file,vocab_file)
def generate_category_dict(input_file,category_file):
with open(input_file,'r',encoding = 'utf-8') as f:
lines = f.readlines()
category_dict = {}
for line in lines:
label,content = line.strip('\r\n').split('\t')
category_dict.setdefault(label,0)
category_dict[label] += 1
category_number = len(category_dict)
with open(category_file,'w',encoding = 'utf-8') as f:
for category in category_dict:
line = '%s\n' % category
print ('%s\t%d' % (category , category_dict[category]))
f.write(line)
#generate_category_dict(train_file,category_file)
#构建计算图——LSTM模型
# embedding层
# LSTM层
# 全连接层
#调用数据集: next_batch(batch_size):
#调用词典: sentence2id(text_sentence):句子转换为id
#调用类别: category2id(text_category)
#LSTM中的参数
def get_default_params():
return tf.contrib.training.HParams(
num_embedding_size = 16,
num_timesteps = 50,
#两层LSTM,每层有32个神经单元
num_lstm_nodes = [32,32],
num_lstm_layers = 2,
num_fc_nodes = 32,
batch_size = 100,
#设置lstm的梯度
clip_lstm_grads = 1.0,
learning_rate = 0.001,
num_word_threshold = 10
)
hps = get_default_params()
#获得参数
#example : hps.learning_rate
output_folder = './run_text_rnn'
#文件夹不存在时,就去创建
if not os.path.exists(output_folder):
os.mkdir(output_folder)
#词表封装
class Vocab:
def __init__(self,filename,num_word_threshold):
self._word_to_id = {}
self._unk = -1
self._num_word_threshold = num_word_threshold
self._read_dict(filename)
def _read_dict(self,filename):
with open(filename,'r',encoding = 'utf-8') as f:
lines = f.readlines()
for line in lines:
word , frequency = line.strip('\r\n').split('\t')
frequency = int(frequency)
if frequency < self._num_word_threshold:
continue
idx = len(self._word_to_id)
if word == 'Unknown':
self._unk = idx
self._word_to_id[word] = idx
#word不存在时,返回unk指代的id
#了解一下字典的get()函数
def word_to_id(self,word):
return self._word_to_id.get(word,self._unk)
@property
def unk(self):
return self._unk
def size(self):
return len(self._word_to_id)
def sentence_to_id(self,sentence):
word_ids = [self.word_to_id(cur_word) for cur_word in sentence.split()]
return word_ids
#调用方式
#vocab = Vocab(vocab_file, hps.num_word_threshold)
#print (vocab.size())
#tf.logging.info(vocab.size())
#test_str = '的 在 了 是'
#print (vocab.sentence_to_id(test_str))
#类别封装
class CategoryDict:
def __init__(self, filename):
self._category_to_id = {}
with open(filename,'r',encoding = 'utf-8') as f:
lines = f.readlines()
for line in lines:
category = line.strip('\r\n')
idx = len(self._category_to_id)
self._category_to_id[category] = idx
def category_to_id(self,category):
if not category in self._category_to_id:
raise Exception('%s is not in our category list' % category)
return self._category_to_id[category]
#调用方式
#vocab = Vocab(vocab_file,hps.num_word_threshold)
#tf.logging.info('vocab_size: %d' % vocab.size())
#category_vocab = CategoryDict(category_file)
#test_str = '时尚'
#print('label: %s, id: %d' % (test_str , category_vocab.category_to_id(test_str)))
运行结果: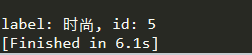
二,数据集封装
class TextDataSet:
def __init__(self,filename,vocab,category_vocab,num_timesteps):
self._vocab = vocab
self._category_vocab = category_vocab
self._num_timesteps = num_timesteps
#matrix
self._inputs = []
#vector
self._outputs = []
self._indicator = 0
self._parse_file(filename)
def random_shuffle(self):
p = np.random.permutation(len(self._inputs))
self._inputs = self._inputs[p]
self._outputs = self._outputs[p]
def _parse_file(self,filename):
print('Loading data from %s', filename)
with open(filename,'r',encoding = 'utf-8') as f:
lines = f.readlines()
for line in lines:
label , content = line.strip('\r\n').split('\t')
id_label = self._category_vocab.category_to_id(label)
id_words = self._vocab.sentence_to_id(content)
#让id_words长度对齐,对较长的进行截断,对较短的进行填充
id_words = id_words[0:self._num_timesteps]
padding_num = self._num_timesteps - len(id_words)
#填充padding_num个unk
id_words = id_words + [self._vocab.unk for i in range(padding_num)]
self._inputs.append(id_words)
self._outputs.append(id_label)
self._inputs = np.asarray(self._inputs, dtype = np.int32)
self._outputs = np.asarray(self._outputs,dtype = np.int32)
#打乱
self.random_shuffle()
def next_batch(self, batch_size):
end_indicator = self._indicator + batch_size
if end_indicator > len(self._inputs):
self._random_shuffle()
self._indicator = 0
end_indicator = batch_size
#batch_size 超过了样本的大小
if end_indicator > len(self._inputs):
raise Exception("batch_size : %d is too large" % batch_size)
batch_inputs = self._inputs[self._indicator:end_indicator]
batch_outputs = self._outputs[self._indicator:end_indicator]
self._indicator = end_indicator
return batch_inputs,batch_outputs
#调用
#vocab = Vocab(vocab_file,hps.num_word_threshold)
#category_vocab = CategoryDict(category_file)
#train_dataset = TextDataSet(train_file,vocab,category_vocab,hps.num_timesteps)
#val_dataset = TextDataSet(val_file,vocab,category_vocab,hps.num_timesteps)
#test_dataset = TextDataSet(test_file,vocab,category_vocab,hps.num_timesteps)
#print (train_dataset.next_batch(2))
#print (val_dataset.next_batch(2))
#print (test_dataset.next_batch(2))
三,定义LSTM神经网络模型
def create_model(hps, vocab_size, num_classes):
num_timesteps = hps.num_timesteps
batch_size = hps.batch_size
inputs = tf.placeholder(tf.int32, (batch_size, num_timesteps))
outputs = tf.placeholder(tf.int32, (batch_size, ))
keep_prob = tf.placeholder(tf.float32, name = 'keep_prob')
global_step = tf.Variable(
tf.zeros([], tf.int64), name = 'global_step', trainable=False)
embedding_initializer = tf.random_uniform_initializer(-1.0, 1.0)
with tf.variable_scope(
'embedding', initializer = embedding_initializer):
embeddings = tf.get_variable(
'embedding',
[vocab_size, hps.num_embedding_size],
tf.float32)
# [1, 10, 7] -> [embeddings[1], embeddings[10], embeddings[7]]
embed_inputs = tf.nn.embedding_lookup(embeddings, inputs)
scale = 1.0 / math.sqrt(hps.num_embedding_size + hps.num_lstm_nodes[-1]) / 3.0
lstm_init = tf.random_uniform_initializer(-scale, scale)
def _generate_params_for_lstm_cell(x_size, h_size, bias_size):
"""generates parameters for pure lstm implementation."""
x_w = tf.get_variable('x_weights', x_size)
h_w = tf.get_variable('h_weights', h_size)
b = tf.get_variable('biases', bias_size,
initializer=tf.constant_initializer(0.0))
return x_w, h_w, b
with tf.variable_scope('lstm_nn', initializer = lstm_init):
"""
cells = []
for i in range(hps.num_lstm_layers):
cell = tf.contrib.rnn.BasicLSTMCell(
hps.num_lstm_nodes[i],
state_is_tuple = True)
cell = tf.contrib.rnn.DropoutWrapper(
cell,
output_keep_prob = keep_prob)
cells.append(cell)
cell = tf.contrib.rnn.MultiRNNCell(cells)
initial_state = cell.zero_state(batch_size, tf.float32)
# rnn_outputs: [batch_size, num_timesteps, lstm_outputs[-1]]
rnn_outputs, _ = tf.nn.dynamic_rnn(
cell, embed_inputs, initial_state = initial_state)
last = rnn_outputs[:, -1, :]
"""
with tf.variable_scope('inputs'):
ix, ih, ib = _generate_params_for_lstm_cell(
x_size = [hps.num_embedding_size, hps.num_lstm_nodes[0]],
h_size = [hps.num_lstm_nodes[0], hps.num_lstm_nodes[0]],
bias_size = [1, hps.num_lstm_nodes[0]]
)
with tf.variable_scope('outputs'):
ox, oh, ob = _generate_params_for_lstm_cell(
x_size = [hps.num_embedding_size, hps.num_lstm_nodes[0]],
h_size = [hps.num_lstm_nodes[0], hps.num_lstm_nodes[0]],
bias_size = [1, hps.num_lstm_nodes[0]]
)
with tf.variable_scope('forget'):
fx, fh, fb = _generate_params_for_lstm_cell(
x_size = [hps.num_embedding_size, hps.num_lstm_nodes[0]],
h_size = [hps.num_lstm_nodes[0], hps.num_lstm_nodes[0]],
bias_size = [1, hps.num_lstm_nodes[0]]
)
with tf.variable_scope('memory'):
cx, ch, cb = _generate_params_for_lstm_cell(
x_size = [hps.num_embedding_size, hps.num_lstm_nodes[0]],
h_size = [hps.num_lstm_nodes[0], hps.num_lstm_nodes[0]],
bias_size = [1, hps.num_lstm_nodes[0]]
)
state = tf.Variable(
tf.zeros([batch_size, hps.num_lstm_nodes[0]]),
trainable = False
)
h = tf.Variable(
tf.zeros([batch_size, hps.num_lstm_nodes[0]]),
trainable = False
)
for i in range(num_timesteps):
# [batch_size, 1, embed_size]
embed_input = embed_inputs[:, i, :]
embed_input = tf.reshape(embed_input,
[batch_size, hps.num_embedding_size])
forget_gate = tf.sigmoid(
tf.matmul(embed_input, fx) + tf.matmul(h, fh) + fb)
input_gate = tf.sigmoid(
tf.matmul(embed_input, ix) + tf.matmul(h, ih) + ib)
output_gate = tf.sigmoid(
tf.matmul(embed_input, ox) + tf.matmul(h, oh) + ob)
mid_state = tf.tanh(
tf.matmul(embed_input, cx) + tf.matmul(h, ch) + cb)
state = mid_state * input_gate + state * forget_gate
h = output_gate * tf.tanh(state)
last = h
fc_init = tf.uniform_unit_scaling_initializer(factor=1.0)
with tf.variable_scope('fc', initializer = fc_init):
fc1 = tf.layers.dense(last,
hps.num_fc_nodes,
activation = tf.nn.relu,
name = 'fc1')
fc1_dropout = tf.contrib.layers.dropout(fc1, keep_prob)
logits = tf.layers.dense(fc1_dropout,
num_classes,
name = 'fc2')
with tf.name_scope('metrics'):
softmax_loss = tf.nn.sparse_softmax_cross_entropy_with_logits(
logits = logits, labels = outputs)
loss = tf.reduce_mean(softmax_loss)
# [0, 1, 5, 4, 2] -> argmax: 2
y_pred = tf.argmax(tf.nn.softmax(logits),
1,
output_type = tf.int32)
correct_pred = tf.equal(outputs, y_pred)
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
with tf.name_scope('train_op'):
tvars = tf.trainable_variables()
for var in tvars:
tf.logging.info('variable name: %s' % (var.name))
grads, _ = tf.clip_by_global_norm(
tf.gradients(loss, tvars), hps.clip_lstm_grads)
optimizer = tf.train.AdamOptimizer(hps.learning_rate)
train_op = optimizer.apply_gradients(
zip(grads, tvars), global_step = global_step)
return ((inputs, outputs, keep_prob),
(loss, accuracy),
(train_op, global_step))
placeholders, metrics, others = create_model(
hps, vocab_size, num_classes)
神经网络的另一种实现方式:
def create_model(hps, vocab_size, num_classes):
num_timesteps = hps.num_timesteps
batch_size = hps.batch_size
inputs = tf.placeholder(tf.int32, (batch_size, num_timesteps))
outputs = tf.placeholder(tf.int32, (batch_size, ))
keep_prob = tf.placeholder(tf.float32, name = 'keep_prob')
global_step = tf.Variable(
tf.zeros([], tf.int64), name = 'global_step', trainable=False)
embedding_initializer = tf.random_uniform_initializer(-1.0, 1.0)
with tf.variable_scope(
'embedding', initializer = embedding_initializer):
embeddings = tf.get_variable(
'embedding',
[vocab_size, hps.num_embedding_size],
tf.float32)
# [1, 10, 7] -> [embeddings[1], embeddings[10], embeddings[7]]
embed_inputs = tf.nn.embedding_lookup(embeddings, inputs)
scale = 1.0 / math.sqrt(hps.num_embedding_size + hps.num_lstm_nodes[-1]) / 3.0
lstm_init = tf.random_uniform_initializer(-scale, scale)
with tf.variable_scope('lstm_nn', initializer = lstm_init):
cells = []
for i in range(hps.num_lstm_layers):
cell = tf.contrib.rnn.BasicLSTMCell(
hps.num_lstm_nodes[i],
state_is_tuple = True)
cell = tf.contrib.rnn.DropoutWrapper(
cell,
output_keep_prob = keep_prob)
cells.append(cell)
cell = tf.contrib.rnn.MultiRNNCell(cells)
initial_state = cell.zero_state(batch_size, tf.float32)
# rnn_outputs: [batch_size, num_timesteps, lstm_outputs[-1]]
rnn_outputs, _ = tf.nn.dynamic_rnn(
cell, embed_inputs, initial_state = initial_state)
last = rnn_outputs[:, -1, :]
fc_init = tf.uniform_unit_scaling_initializer(factor=1.0)
with tf.variable_scope('fc', initializer = fc_init):
fc1 = tf.layers.dense(last,
hps.num_fc_nodes,
activation = tf.nn.relu,
name = 'fc1')
fc1_dropout = tf.contrib.layers.dropout(fc1, keep_prob)
logits = tf.layers.dense(fc1_dropout,
num_classes,
name = 'fc2')
with tf.name_scope('metrics'):
softmax_loss = tf.nn.sparse_softmax_cross_entropy_with_logits(
logits = logits, labels = outputs)
loss = tf.reduce_mean(softmax_loss)
# [0, 1, 5, 4, 2] -> argmax: 2
y_pred = tf.argmax(tf.nn.softmax(logits),
1,
output_type = tf.int32)
correct_pred = tf.equal(outputs, y_pred)
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
with tf.name_scope('train_op'):
tvars = tf.trainable_variables()
for var in tvars:
tf.logging.info('variable name: %s' % (var.name))
grads, _ = tf.clip_by_global_norm(
tf.gradients(loss, tvars), hps.clip_lstm_grads)
optimizer = tf.train.AdamOptimizer(hps.learning_rate)
train_op = optimizer.apply_gradients(
zip(grads, tvars), global_step = global_step)
return ((inputs, outputs, keep_prob),
(loss, accuracy),
(train_op, global_step))
点击查看更多内容
为 TA 点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中




感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦