
1. 抓包
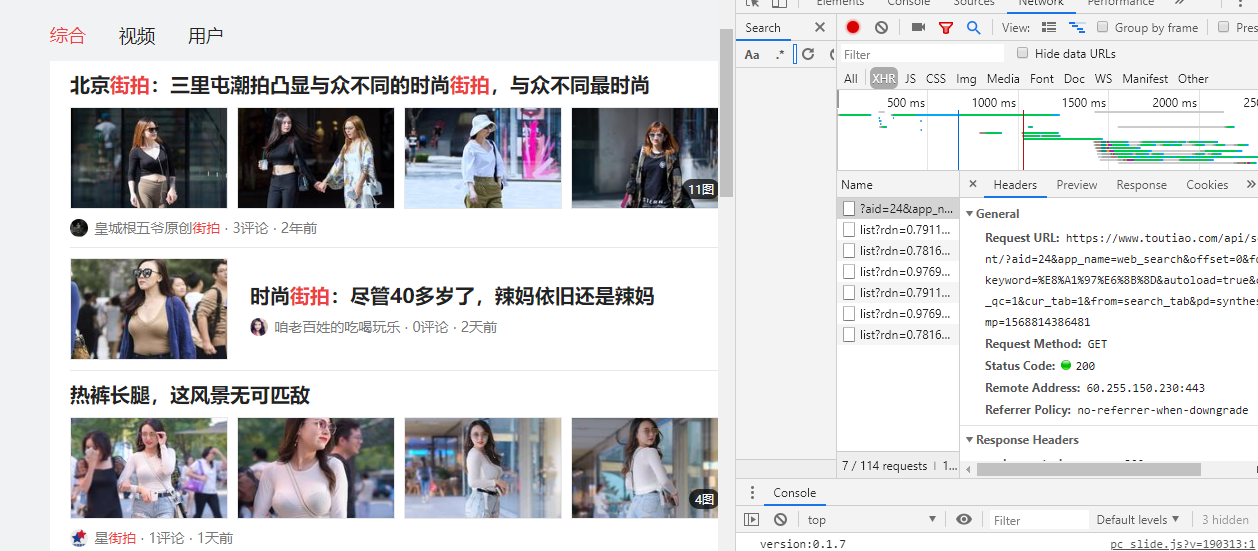
2. 查看参数信息
多看几页即可看见规律,主要改变的项无非是offset,timestamp,这里的stamp是13位的时间戳,再根据keyword改变搜索项,可以改变offset值实现翻页操作,其他的都是固定项
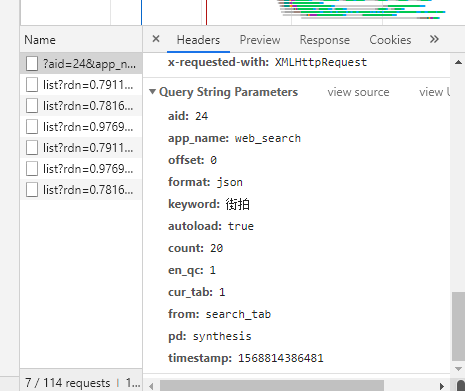
3. 数据解析
返回的数据中可以得到具体的栏目,image_list中是所有的图片链接,我们解析这个栏目,然后根据title下载图片即可
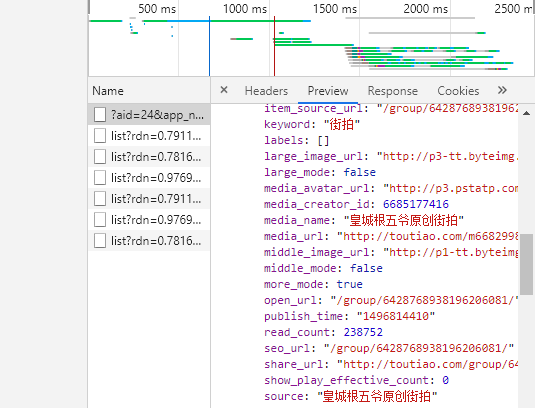
4. 流程分析
构建url发起请求,改变offset的值执行便利操作,对返回的json数据进行解析,根据title名称建立文件夹,如果栏目含有图片,则以title_num的格式下载图片
import requests
import os
import time
headers = {
'authority': 'www.toutiao.com',
'method': 'GET',
'path': '/api/search/content/?aid=24&app_name=web_search&offset=100&format=json&keyword=%E8%A1%97%E6%8B%8D&autoload=true&count=20&en_qc=1&cur_tab=1&from=search_tab&pd=synthesis×tamp=1556892118295',
'scheme': 'https',
'accept': 'application/json, text/javascript',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'content-type': 'application/x-www-form-urlencoded',
'referer': 'https://www.toutiao.com/search/?keyword=%E8%A1%97%E6%8B%8D',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36',
'x-requested-with': 'XMLHttpRequest',
}
def get_html(url):
return requests.get(url, headers=headers).json()
def get_values_in_dict(list):
result = []
for data in list:
result.append(data['url'])
return result
def parse_data(url):
text = get_html(url)
for data in text['data']:
if 'image_list' in data.keys():
title = data['title'].replace('|', '')
img_list = get_values_in_dict(data['image_list'])
else:
continue
if not os.path.exists('街拍/' + title):
os.makedirs('街拍/' + title)
for index, pic in enumerate(img_list):
with open('街拍/{}/{}.jpg'.format(title, index + 1), 'wb') as f:
f.write(requests.get(pic).content)
print("Download {} Successful".format(title))
def get_num(num):
if isinstance(num, int) and num % 20 == 0:
return num
else:
return 0
def main(num):
for i in range(0, get_num(num) + 1, 20):
url = 'https://www.toutiao.com/api/search/content/?aid={}&app_name={}&offset={}&format={}&keyword={}&' \
'autoload={}&count={}&en_qc={}&cur_tab={}&from={}&pd={}×tamp={}'.format(24, 'web_search', i,
'json', '街拍', 'true', 20, 1, 1, 'search_tab', 'synthesis', str(time.time())[:14].replace('.', ''))
parse_data(url)
if __name__ == '__main__':
main(40)
点击查看更多内容
1人点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中




感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦