
一.神经网络初识
1.神经元的二分类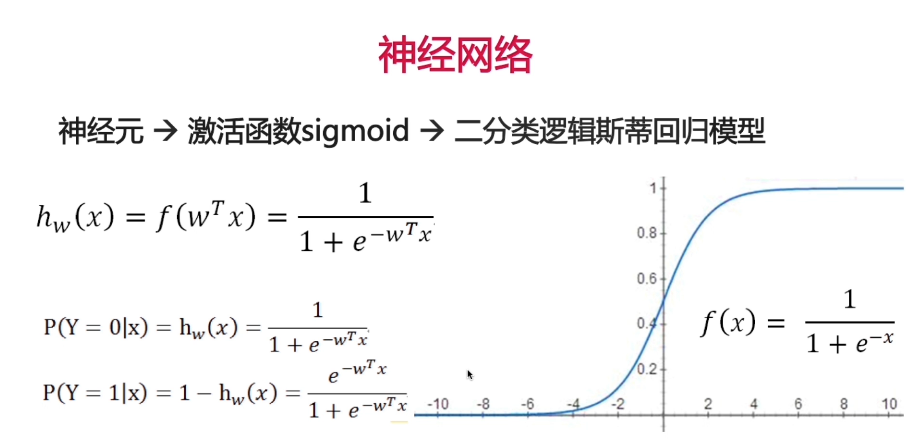
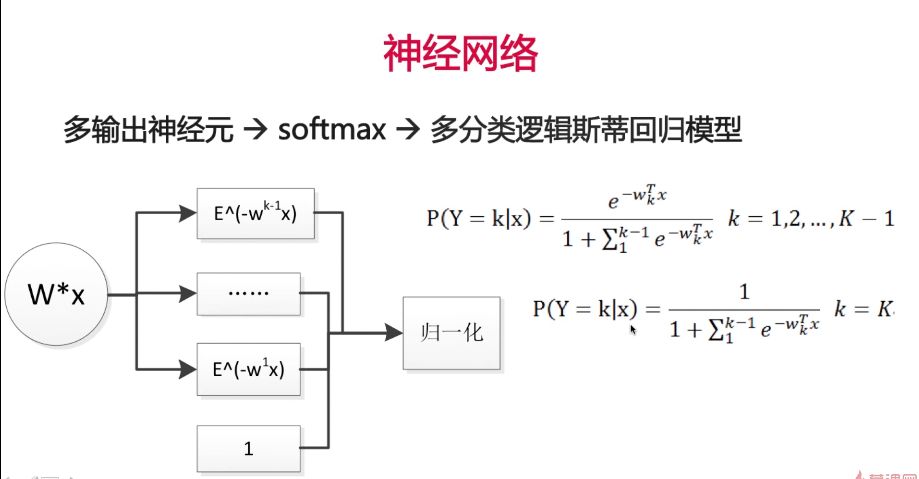
2.神经元的多分类
此时的W不再是一维向量,而是二维矩阵
分为k类

代码实例:
Tensorflow实现多层神经元
数据集:
训练集:data_batch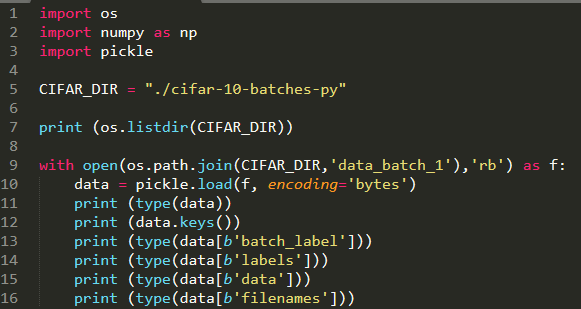
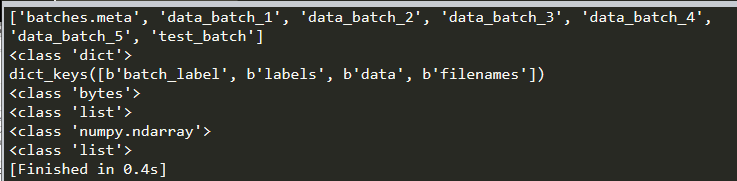
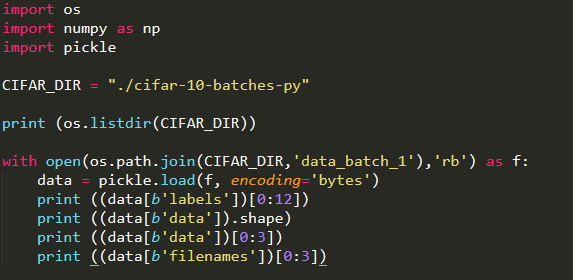

Data的大小 : 10000 X 3072
说明有10000张图片
为什么是3072: 32X32(像素) X 3(通道) = 3072
Labels:一共有10类图片
展开并打印Data数据中的一张图片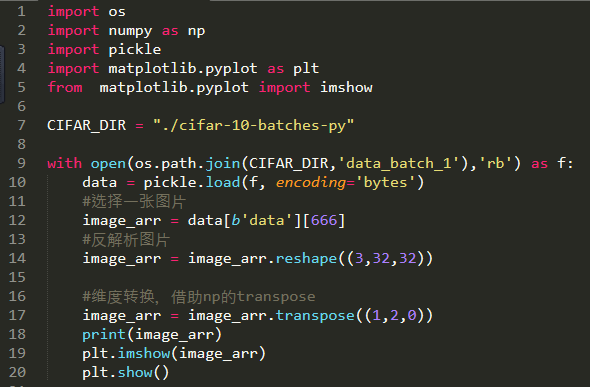
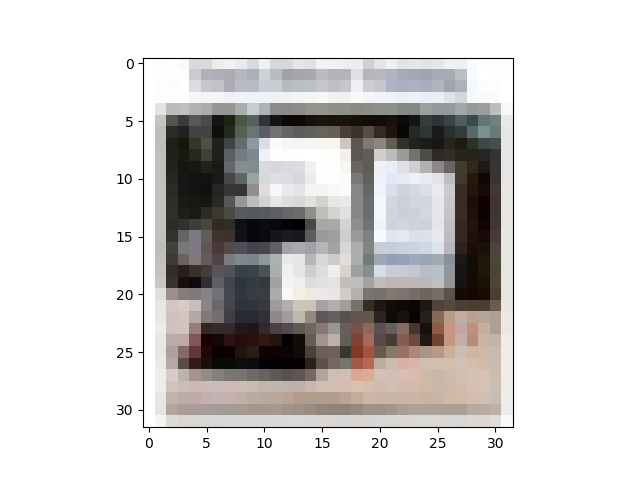
不进行维度转换就会报错:

读数据:
import os
import numpy as np
import tensorflow as tf
import pickle
import matplotlib.pyplot as plt
from matplotlib.pyplot import imshow
CIFAR_DIR = "./cifar-10-batches-py"
#read_data from file
def load_data(filename):
with open(filename,'rb') as f:
data = pickle.load(f, encoding='bytes')
return data[b'data'],data[b'labels']
#数据预处理
class CifarData:
def __init__(self,filenames,need_shuffle):
all_data = []
all_labels = []
for filename in filenames:
data,labels = load_data(filename)
#把数据绑定到一起
for item,label in zip(data,labels):
if label in [0,1]:
all_data.append(item)
all_labels.append(label)
self._data = np.vstack(all_data) #纵向合并
self._labels = np.hstack(all_labels) #横向合并
print (self._data.shape)
print (self._labels.shape)
self._num_examples = self._data.shape[0]
self._need_shuffle = need_shuffle
#_indicator: 数据集起始位置
self._indicator = 0
if self._need_shuffle:
self._shuffle_data()
def _shuffle_data(self):
#打乱
p = np.random.permutation(self._num_examples)
self._data = self._data[p]
self._labels = self._labels[p]
def next_batch(self,batch_size):
#更新起始位置
end_indicator = self._indicator + batch_size
if end_indicator > self._num_examples:
if self._need_shuffle:
self._shuffle_data()
#重置
self._indicator = 0
end_indicator = batch_size
else:
raise Exception("Have no more examples")
#保险起见,再判断一遍
if end_indicator > self._num_examples:
raise Exception("batch size is larger than all examples")
batch_data = self._data[self._indicator : end_indicator]
batch_labels = self._labels[self._indicator : end_indicator]
self._indicator = end_indicator
return batch_data,batch_labels
train_filenames = [os.path.join(CIFAR_DIR,'data_batch_%d' % i) for i in range(1,6)]
test_filenames = [os.path.join(CIFAR_DIR,'test_batch')]
train_data = CifarData(train_filenames,True)
batch_data,batch_labels = train_data.next_batch(10)
print(batch_data)
print(batch_labels)
运行结果: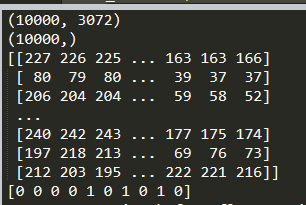
实现神经元——二分类:
import os
import numpy as np
import tensorflow as tf
import pickle
import matplotlib.pyplot as plt
from matplotlib.pyplot import imshow
CIFAR_DIR = "./cifar-10-batches-py"
#read_data from file
def load_data(filename):
with open(filename,'rb') as f:
data = pickle.load(f, encoding='bytes')
return data[b'data'],data[b'labels']
#数据预处理
class CifarData:
def __init__(self,filenames,need_shuffle):
all_data = []
all_labels = []
for filename in filenames:
data,labels = load_data(filename)
#把数据绑定到一起
for item,label in zip(data,labels):
if label in [0,1]:
all_data.append(item)
all_labels.append(label)
self._data = np.vstack(all_data) #纵向合并
#特征值缩放到0,1之间
self._data = self._data / 127.5 - 1
self._labels = np.hstack(all_labels) #横向合并
print (self._data.shape)
print (self._labels.shape)
self._num_examples = self._data.shape[0]
self._need_shuffle = need_shuffle
#_indicator: 数据集起始位置
self._indicator = 0
if self._need_shuffle:
self._shuffle_data()
def _shuffle_data(self):
#打乱
p = np.random.permutation(self._num_examples)
self._data = self._data[p]
self._labels = self._labels[p]
def next_batch(self,batch_size):
#更新起始位置
end_indicator = self._indicator + batch_size
if end_indicator > self._num_examples:
if self._need_shuffle:
self._shuffle_data()
#重置
self._indicator = 0
end_indicator = batch_size
else:
raise Exception("Have no more examples")
#保险起见,再判断一遍
if end_indicator > self._num_examples:
raise Exception("batch size is larger than all examples")
batch_data = self._data[self._indicator : end_indicator]
batch_labels = self._labels[self._indicator : end_indicator]
self._indicator = end_indicator
return batch_data,batch_labels
train_filenames = [os.path.join(CIFAR_DIR,'data_batch_%d' % i) for i in range(1,6)]
test_filenames = [os.path.join(CIFAR_DIR,'test_batch')]
train_data = CifarData(train_filenames,True)
batch_data,batch_labels = train_data.next_batch(10)
#搭建tensorflow计算图
x = tf.placeholder(tf.float32,[None,3072])
y = tf.placeholder(tf.int64,[None])
#权重
w = tf.get_variable('w',[x.get_shape()[-1],1], initializer = tf.random_normal_initializer(0,1))
b = tf.get_variable('b',[1],initializer = tf.constant_initializer(0.0))
# [None , 3072] * [3072 , 1] = [None,1]
y_ = tf.matmul(x,w) + b
#用sigmoid 把y_转换成概率
#p_y_1,y_ : [None,1]
p_y_1 = tf.nn.sigmoid(y_)
#y: [None] --> [None,1]
y_reshaped = tf.reshape(y,(-1,1))
#y:int64 --> float32
y_reshaped_float = tf.cast(y_reshaped,tf.float32)
#tf对数据类型敏感,不转换会出问题
loss = tf.reduce_mean(tf.square(y_reshaped_float - p_y_1))
predict = p_y_1 > 0.5
#>0.5 : True,<0.5: False
correct_prediction = tf.equal(tf.cast(predict,tf.int64),y_reshaped)
#求平均
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float64))
#梯度下降
with tf.name_scope("train_op"):
train_op = tf.train.AdamOptimizer(1e-3).minimize(loss)
init = tf.global_variables_initializer()
batch_size = 20
train_steps = 10000
test_steps = 100
with tf.Session() as sess:
sess.run(init)
for i in range(train_steps):
batch_data,batch_labels = train_data.next_batch(batch_size)
loss_val,accu_val, _ = sess.run([loss,accuracy,train_op] , feed_dict = {x:batch_data , y:batch_labels})
if i % 200 == 0:
print ('[Train] Step: %d, loss: %4.5f, acc: %4.5f' % (i, loss_val,accu_val))
if i % 1000 == 0:
test_data = CifarData(test_filenames,False)
all_test_acc_val = []
for j in range(test_steps):
test_batch_data,test_batch_labels = test_data.next_batch(batch_size)
test_acc_val = sess.run(
[accuracy], feed_dict = {x:test_batch_data, y:test_batch_labels}
)
all_test_acc_val.append(test_acc_val)
test_acc = np.mean(all_test_acc_val)
print ('[Test] Step: %d, acc: %4.5f' % (i,test_acc))
运行结果 :
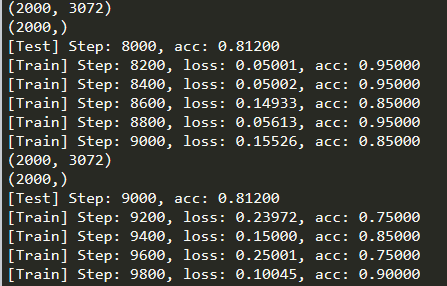
实现神经元——多分类:
import os
import numpy as np
import tensorflow as tf
import pickle
import matplotlib.pyplot as plt
from matplotlib.pyplot import imshow
CIFAR_DIR = "./cifar-10-batches-py"
#read_data from file
def load_data(filename):
with open(filename,'rb') as f:
data = pickle.load(f, encoding='bytes')
return data[b'data'],data[b'labels']
#数据预处理
class CifarData:
def __init__(self,filenames,need_shuffle):
all_data = []
all_labels = []
for filename in filenames:
data,labels = load_data(filename)
#把数据绑定到一起
all_data.append(data)
all_labels.append(labels)
self._data = np.vstack(all_data) #纵向合并
#特征值缩放到0,1之间
self._data = self._data / 127.5 - 1
self._labels = np.hstack(all_labels) #横向合并
print (self._data.shape)
print (self._labels.shape)
self._num_examples = self._data.shape[0]
self._need_shuffle = need_shuffle
#_indicator: 数据集起始位置
self._indicator = 0
if self._need_shuffle:
self._shuffle_data()
def _shuffle_data(self):
#打乱
p = np.random.permutation(self._num_examples)
self._data = self._data[p]
self._labels = self._labels[p]
def next_batch(self,batch_size):
#更新起始位置
end_indicator = self._indicator + batch_size
if end_indicator > self._num_examples:
if self._need_shuffle:
self._shuffle_data()
#重置
self._indicator = 0
end_indicator = batch_size
else:
raise Exception("Have no more examples")
#保险起见,再判断一遍
if end_indicator > self._num_examples:
raise Exception("batch size is larger than all examples")
batch_data = self._data[self._indicator : end_indicator]
batch_labels = self._labels[self._indicator : end_indicator]
self._indicator = end_indicator
return batch_data,batch_labels
train_filenames = [os.path.join(CIFAR_DIR,'data_batch_%d' % i) for i in range(1,6)]
test_filenames = [os.path.join(CIFAR_DIR,'test_batch')]
train_data = CifarData(train_filenames,True)
batch_data,batch_labels = train_data.next_batch(10)
#搭建tensorflow计算图
x = tf.placeholder(tf.float32,[None,3072])
y = tf.placeholder(tf.int64,[None])
#权重
w = tf.get_variable('w',[x.get_shape()[-1],10], initializer = tf.random_normal_initializer(0,1))
b = tf.get_variable('b',[10],initializer = tf.constant_initializer(0.0))
# [None , 3072] * [3072 , 10] = [None,10]
y_ = tf.matmul(x,w) + b
#softmax而不是sigmoid表示概率
#softmax = tf.exp(logits) / tf.reduce_sum(tf.exp(logits) ,axis)
"""
#Method1,使用平方差损失函数
p_y_1 = tf.nn.softmax(y_)
#结合softmax的特点,为了计算损失函数,要对y进行one-hot编码
y_one_hot = tf.one_hot(y,10,dtype = tf.float32)
loss = tf.reduce_mean(tf.square(y_one_hot - p_y_1))
"""
#Method2,使用交叉熵损失函数
loss = tf.losses.sparse_softmax_cross_entropy(labels = y,logits = y_)
#该函数完成三个步骤
#1.y_ -> softmax
#2.y -> one_hot
#3.y*logy_
#求最大值
predict = tf.argmax(y_,1)
correct_prediction = tf.equal(predict,y)
#求平均
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float64))
#梯度下降
with tf.name_scope("train_op"):
train_op = tf.train.AdamOptimizer(1e-3).minimize(loss)
init = tf.global_variables_initializer()
batch_size = 20
train_steps = 10000
test_steps = 100
with tf.Session() as sess:
sess.run(init)
for i in range(train_steps):
batch_data,batch_labels = train_data.next_batch(batch_size)
loss_val,accu_val, _ = sess.run([loss,accuracy,train_op] , feed_dict = {x:batch_data , y:batch_labels})
if i % 200 == 0:
print ('[Train] Step: %d, loss: %4.5f, acc: %4.5f' % (i, loss_val,accu_val))
if i % 1000 == 0:
test_data = CifarData(test_filenames,False)
all_test_acc_val = []
for j in range(test_steps):
test_batch_data,test_batch_labels = test_data.next_batch(batch_size)
test_acc_val = sess.run(
[accuracy], feed_dict = {x:test_batch_data, y:test_batch_labels}
)
all_test_acc_val.append(test_acc_val)
test_acc = np.mean(all_test_acc_val)
print ('[Test] Step: %d, acc: %4.5f' % (i,test_acc))
运行结果: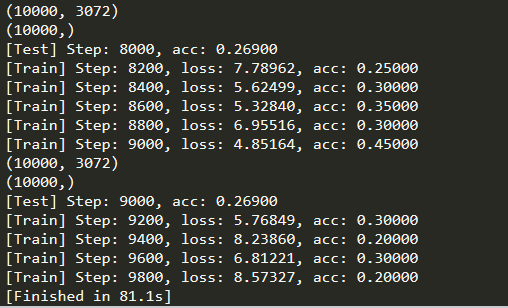
一个神经元,求梯度,求一次偏导
多层神经元,相当于复合函数,求偏导时,用的是多元微分学中的链式法则
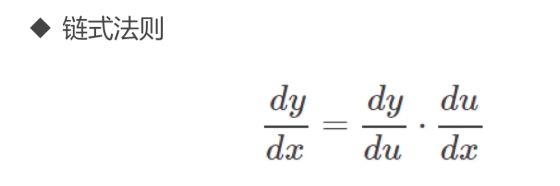
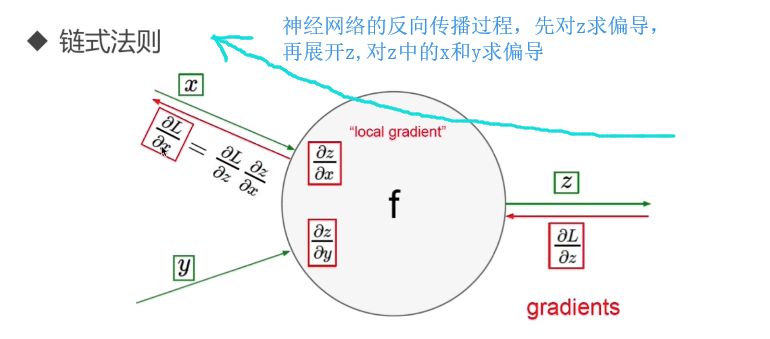
反向传播存在的问题:
优化方法:
优化后还存在振荡和局部最优解问题:
解决办法: 和一般梯度下降对比

好处:
二,卷积神经网络
普通神经网络遇到的问题: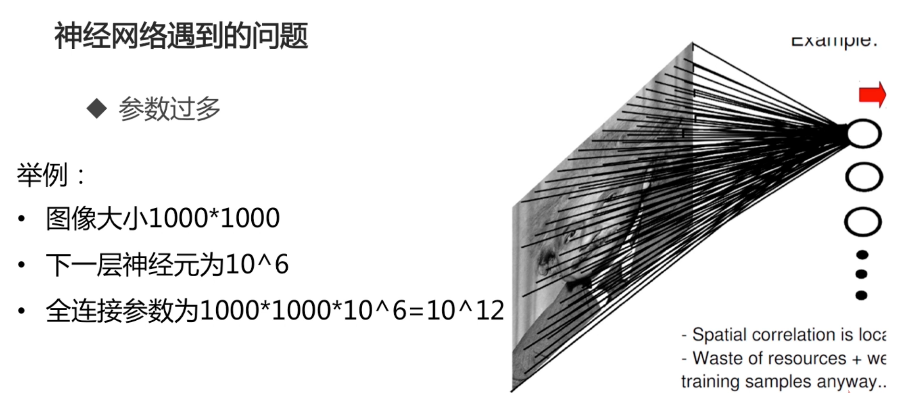
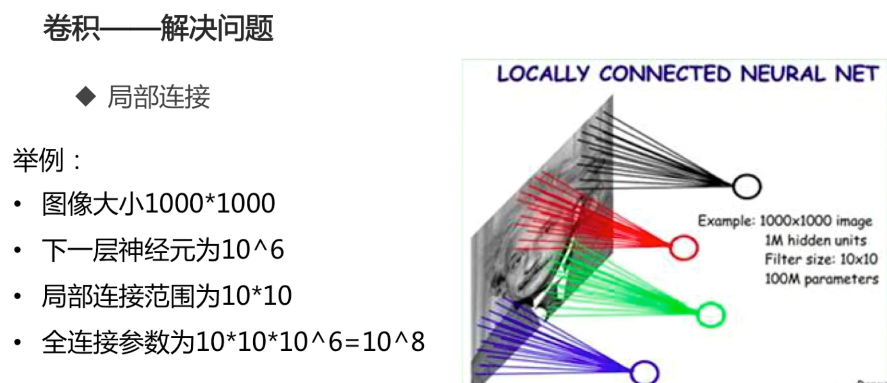
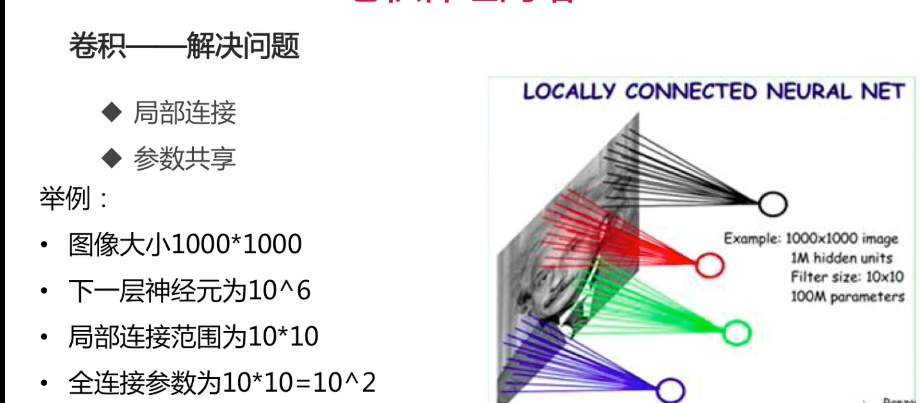
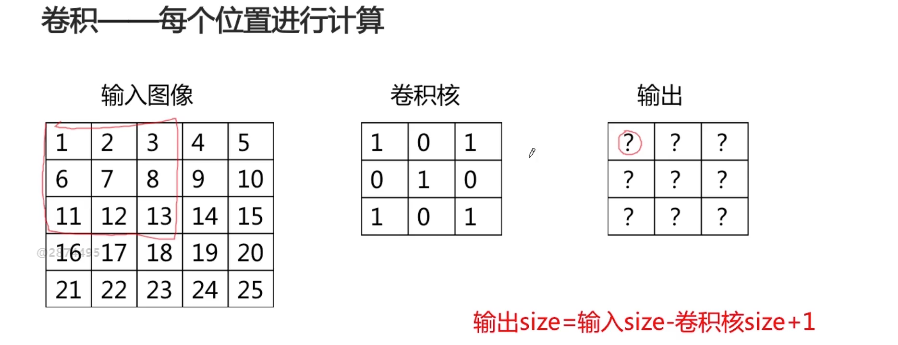
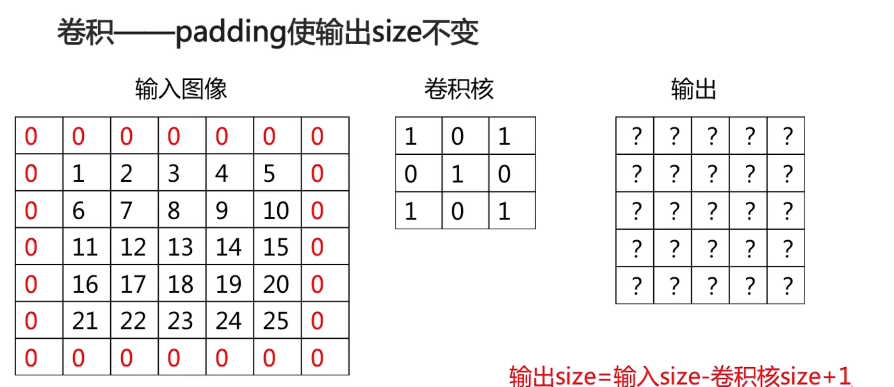
卷积的计算过程:
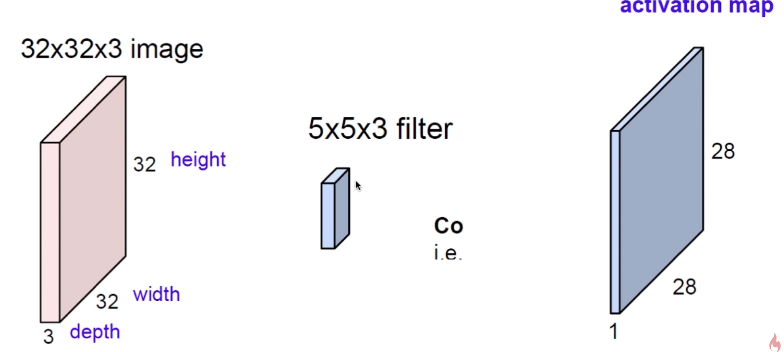
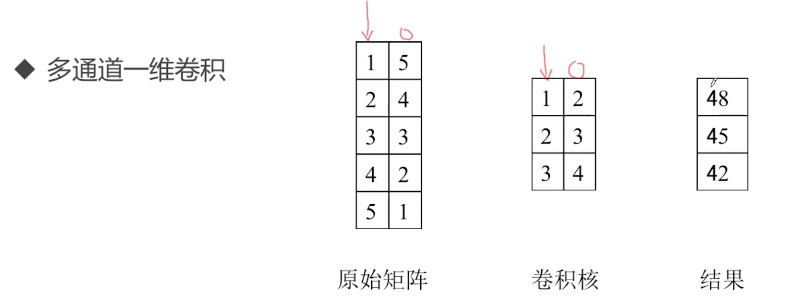
之前的卷积都是单通道一个卷积核的,下面看看多通道多卷积核的卷积运算:
三通道一个卷积核:相当于三层卷积核
三通道六个卷积核:卷积核与卷积核之间,不共享数据
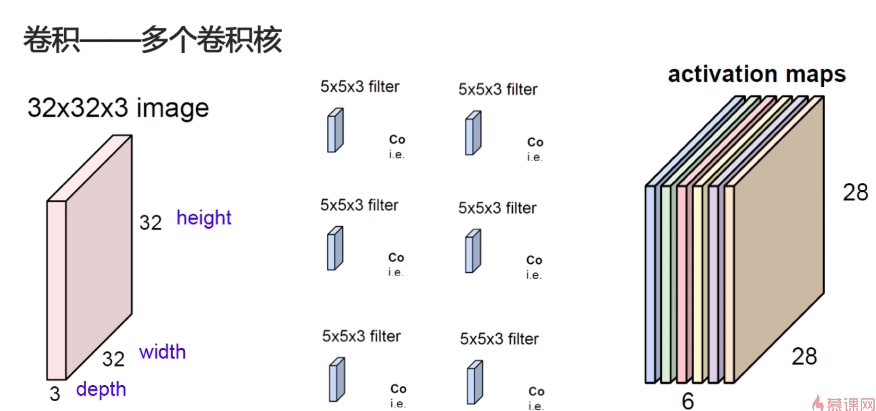
一个卷积核对应图像的一种特征
做一个计算题:

尺寸计算:
参数数目计算:
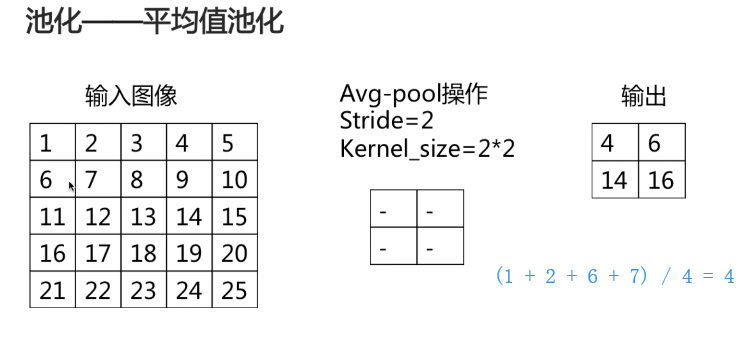
两种池化方式: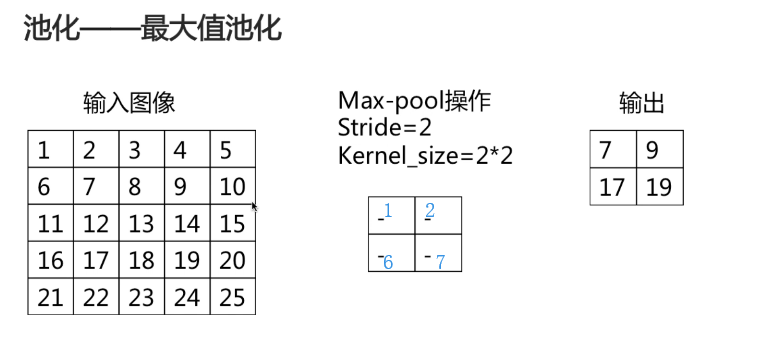
完整代码:
import os
import numpy as np
import tensorflow as tf
import pickle
import matplotlib.pyplot as plt
from matplotlib.pyplot import imshow
CIFAR_DIR = "./cifar-10-batches-py"
#read_data from file
def load_data(filename):
with open(filename,'rb') as f:
data = pickle.load(f, encoding='bytes')
return data[b'data'],data[b'labels']
#数据预处理
class CifarData:
def __init__(self,filenames,need_shuffle):
all_data = []
all_labels = []
for filename in filenames:
data,labels = load_data(filename)
#把数据绑定到一起
all_data.append(data)
all_labels.append(labels)
self._data = np.vstack(all_data) #纵向合并
#特征值缩放到0,1之间
self._data = self._data / 127.5 - 1
self._labels = np.hstack(all_labels) #横向合并
print (self._data.shape)
print (self._labels.shape)
self._num_examples = self._data.shape[0]
self._need_shuffle = need_shuffle
#_indicator: 数据集起始位置
self._indicator = 0
if self._need_shuffle:
self._shuffle_data()
def _shuffle_data(self):
#打乱
p = np.random.permutation(self._num_examples)
self._data = self._data[p]
self._labels = self._labels[p]
def next_batch(self,batch_size):
#更新起始位置
end_indicator = self._indicator + batch_size
if end_indicator > self._num_examples:
if self._need_shuffle:
self._shuffle_data()
#重置
self._indicator = 0
end_indicator = batch_size
else:
raise Exception("Have no more examples")
#保险起见,再判断一遍
if end_indicator > self._num_examples:
raise Exception("batch size is larger than all examples")
batch_data = self._data[self._indicator : end_indicator]
batch_labels = self._labels[self._indicator : end_indicator]
self._indicator = end_indicator
return batch_data,batch_labels
train_filenames = [os.path.join(CIFAR_DIR,'data_batch_%d' % i) for i in range(1,6)]
test_filenames = [os.path.join(CIFAR_DIR,'test_batch')]
train_data = CifarData(train_filenames,True)
batch_data,batch_labels = train_data.next_batch(10)
#搭建tensorflow计算图
x = tf.placeholder(tf.float32,[None,3072])
y = tf.placeholder(tf.int64,[None])
#由于要输入三通道的图像,对x进行维度转换
x_image = tf.reshape(x,[-1,3,32,32])
x_image = tf.transpose(x_image,perm = [0,2,3,1])
#CNN
conv1 = tf.layers.conv2d(x_image,
32, #卷积核通道数
(3,3), #卷积核大小
padding = 'same', #same表示输出的神经元大小不变
activation = tf.nn.relu,
name = 'conv1'
)
pooling1 = tf.layers.max_pooling2d(conv1,
(2,2),#核的大小
(2,2),#步长
name = 'pool1'
)
conv2 = tf.layers.conv2d(pooling1,
32, #卷积核通道数
(3,3), #卷积核大小
padding = 'same', #same表示输出的神经元大小不变
activation = tf.nn.relu,
name = 'conv2'
)
pooling2 = tf.layers.max_pooling2d(conv2,
(2,2),#核的大小
(2,2),#步长
name = 'pool2'
)
conv3 = tf.layers.conv2d(pooling2,
32, #卷积核通道数
(3,3), #卷积核大小
padding = 'same', #same表示输出的神经元大小不变
activation = tf.nn.relu,
name = 'conv3'
)
pooling3 = tf.layers.max_pooling2d(conv3,
(2,2),#核的大小
(2,2),#步长
name = 'pool3'
)
#展开
#[None,4*4*32]
flatten = tf.layers.flatten(pooling3)
#全连接层:变成一维
y_ = tf.layers.dense(flatten,10)
#Method2,使用交叉熵损失函数
loss = tf.losses.sparse_softmax_cross_entropy(labels = y,logits = y_)
#求最大值
predict = tf.argmax(y_,1)
correct_prediction = tf.equal(predict,y)
#求平均
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float64))
#梯度下降
with tf.name_scope("train_op"):
train_op = tf.train.AdamOptimizer(1e-3).minimize(loss)
init = tf.global_variables_initializer()
batch_size = 20
train_steps = 10000
test_steps = 100
with tf.Session() as sess:
sess.run(init)
for i in range(train_steps):
batch_data,batch_labels = train_data.next_batch(batch_size)
loss_val,accu_val, _ = sess.run([loss,accuracy,train_op] , feed_dict = {x:batch_data , y:batch_labels})
if i % 200 == 0:
print ('[Train] Step: %d, loss: %4.5f, acc: %4.5f' % (i, loss_val,accu_val))
if i % 1000 == 0:
test_data = CifarData(test_filenames,False)
all_test_acc_val = []
for j in range(test_steps):
test_batch_data,test_batch_labels = test_data.next_batch(batch_size)
test_acc_val = sess.run(
[accuracy], feed_dict = {x:test_batch_data, y:test_batch_labels}
)
all_test_acc_val.append(test_acc_val)
test_acc = np.mean(all_test_acc_val)
print ('[Test] Step: %d, acc: %4.5f' % (i,test_acc))
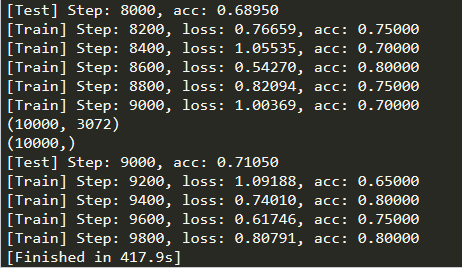
三,循环神经网络
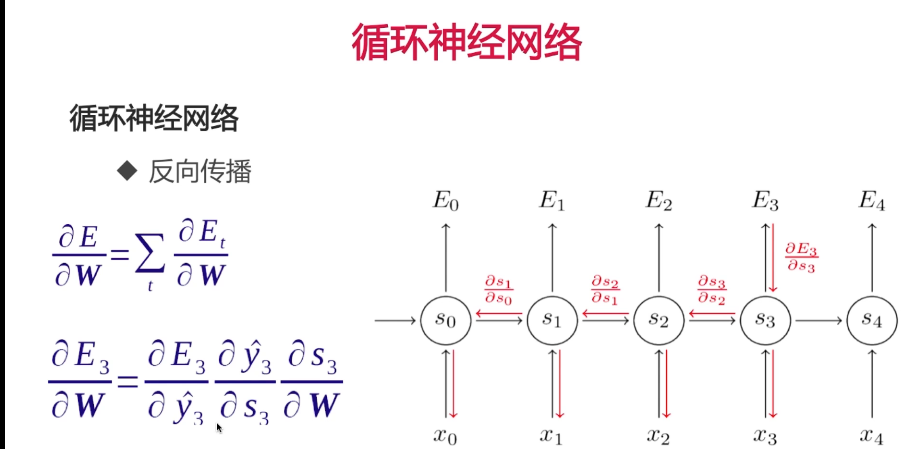
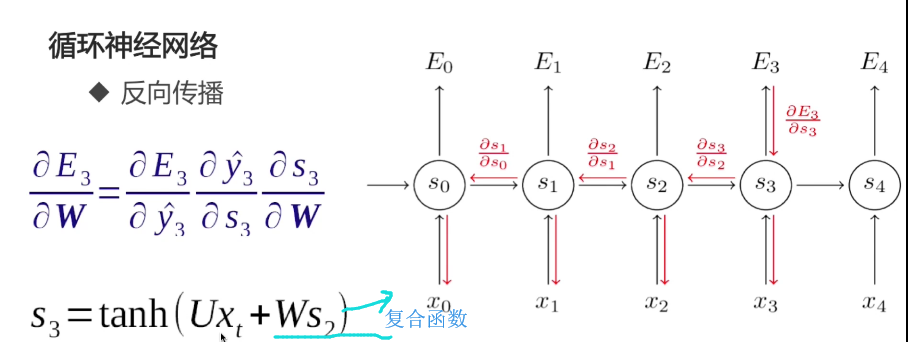
复合函数展开: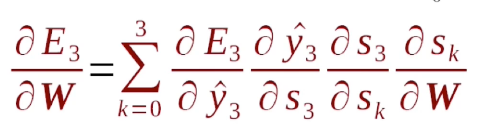
反向传播存在的问题:
分块儿的梯度计算方式: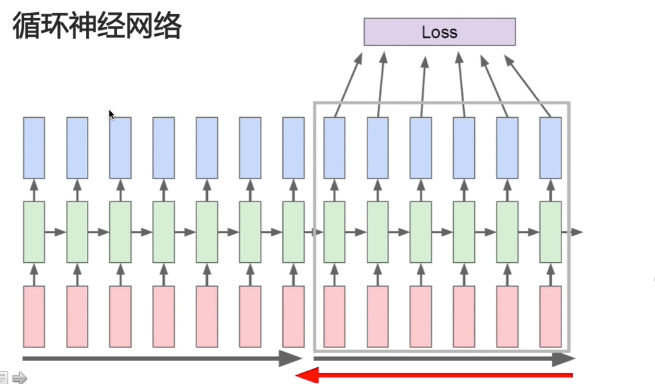
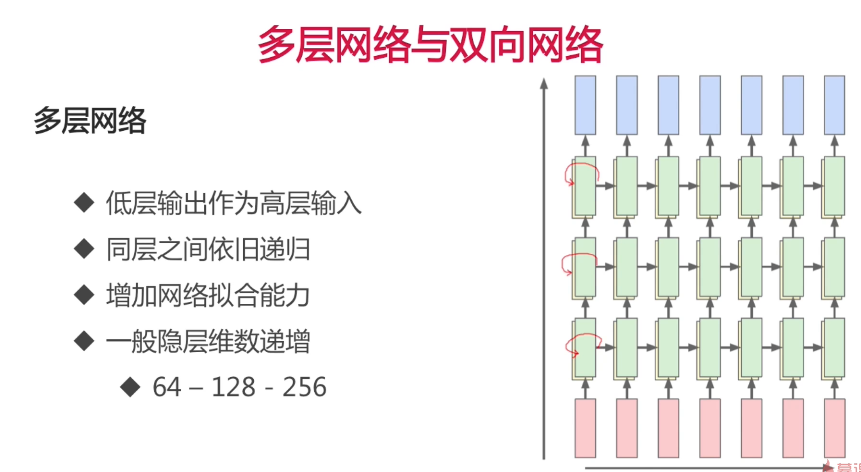
玩点刺激的,多层神经网络,别头晕!!
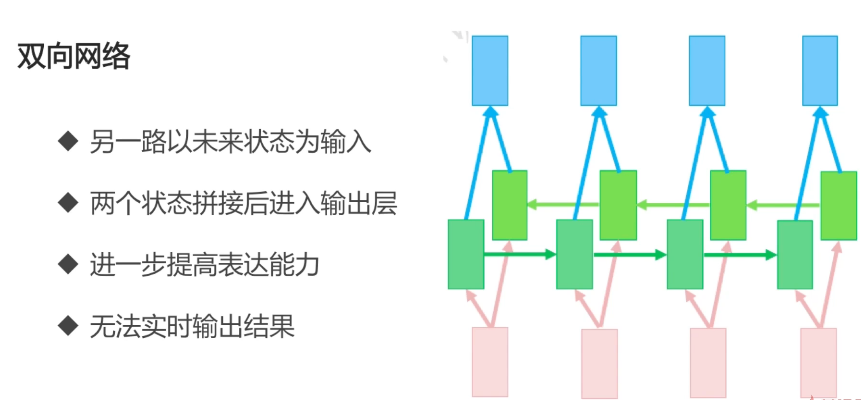
当前很时髦的技术,LSTM:
单元解析:
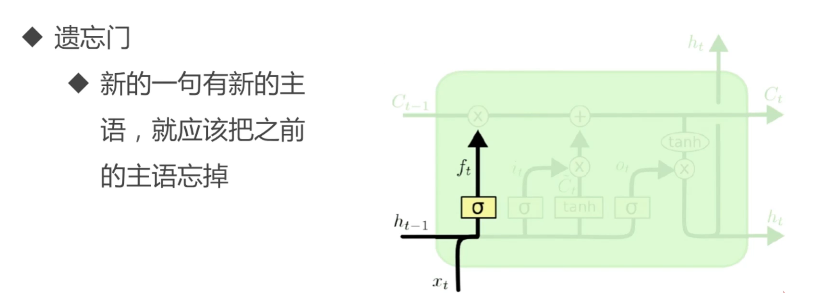
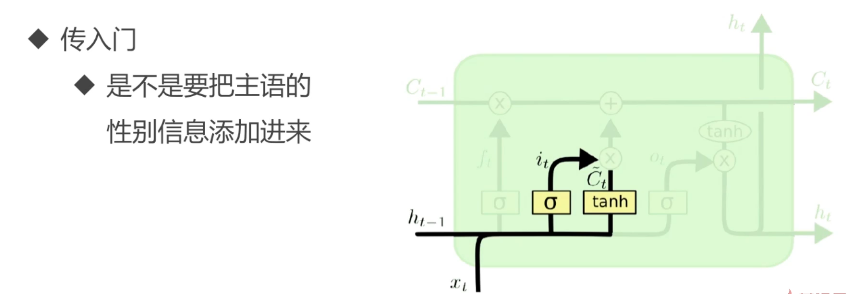
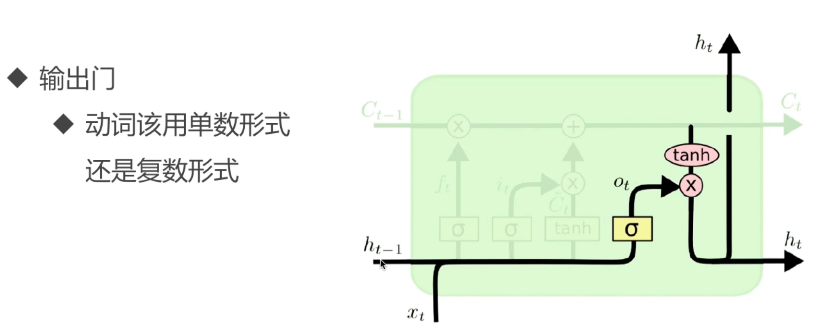
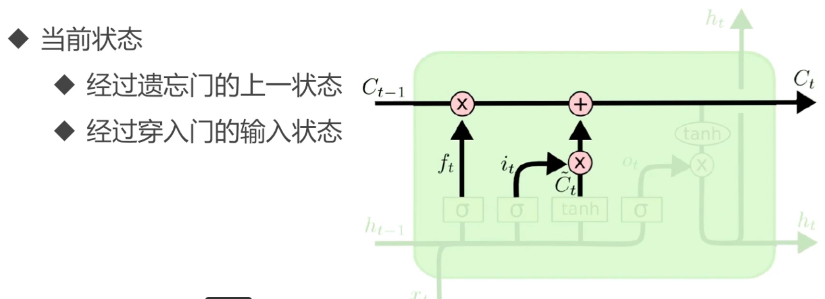
从“主语”,到描述“主语”的信息,再到“主语”后面的“动词”,完整的描述流程。
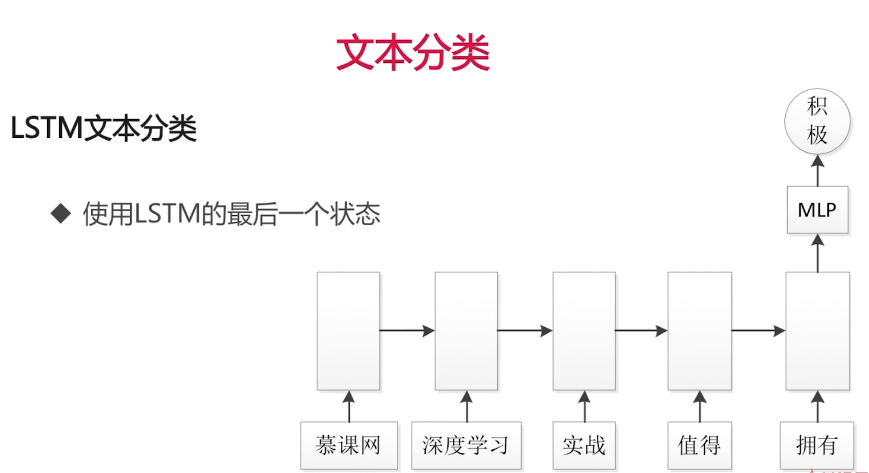
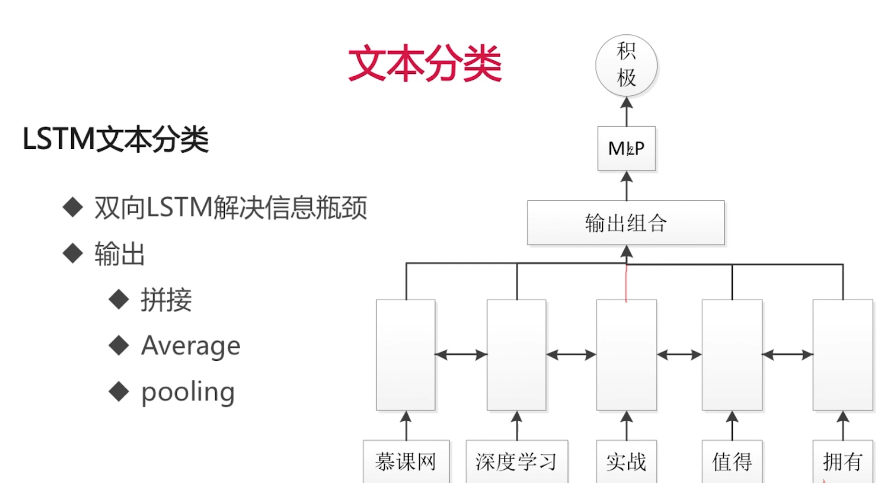
基于LSTM的文本分类模型:
从词语到句子的HAN算法:
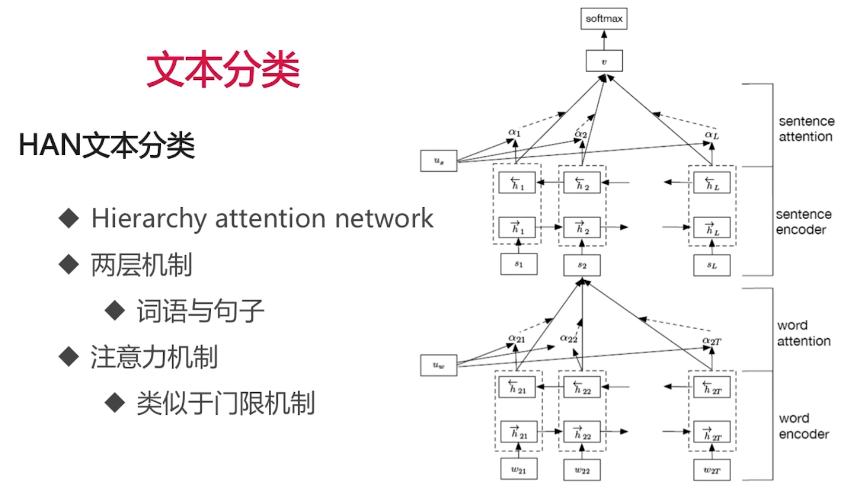
词语经过类似:wx + b 的加权,形成句子的编码 ,然后句子经过类似:wx + b 的加权,形成最后的结果。
基于CNN的文本分类模型: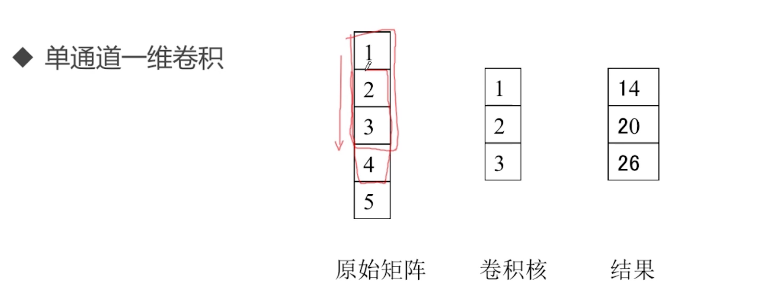
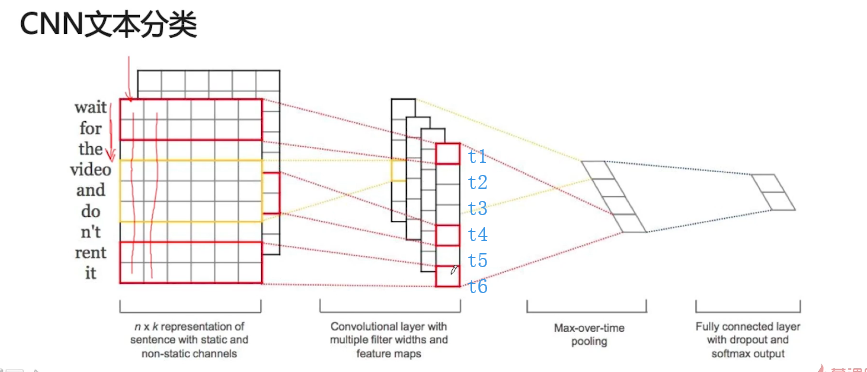
每个词用6维的向量表示
RNN和CNN在文本处理上的异同点:
RNN+CNN融合使用 :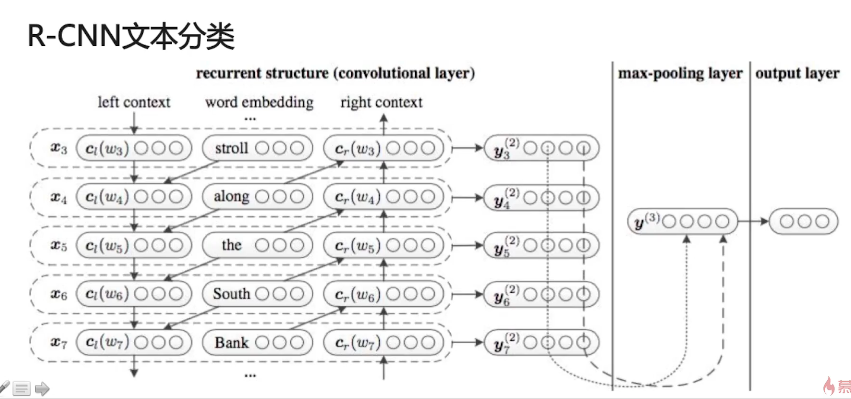
处理流程:在RNN中嵌入卷积运算

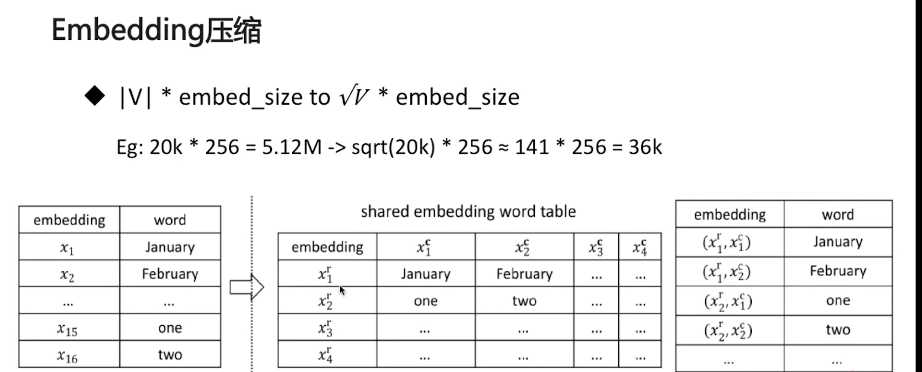
词向量压缩:为了减少参数,防止过拟合
参考教程:
一位大佬的课程,很推荐
https://coding.imooc.com/lesson/259.html#mid=16497
第50篇博客了,从学习算法到现在一直是搬运工,咬咬牙坚持下去,希望以后能有自己的输出,感谢慕课网这个平台。😎
共同学习,写下你的评论
评论加载中...
作者其他优质文章



