
本文首先介绍了 GraphQL,再通过 MongoDB + graphql + graph-pack 的组合实战应用 GraphQL,详细阐述如何使用 GraphQL 来进行增删改查和数据订阅推送,并附有使用示例,边用边学印象深刻~
如果希望将 GraphQL 应用到前后端分离的生产环境,请期待后续文章。
本文实例代码:Github
0. 什么是 GraphQL
GraphQL 是一种面向数据的 API 查询风格。
传统的 API 拿到的是前后端约定好的数据格式,GraphQL 对 API 中的数据提供了一套易于理解的完整描述,客户端能够准确地获得它需要的数据,没有任何冗余,也让 API 更容易地随着时间推移而演进,还能用于构建强大的开发者工具。
1. 概述
前端的开发随着 SPA 框架全面普及,组件化开发也随之成为大势所趋,各个组件分别管理着各自的状态,组件化给前端仔带来便利的同时也带来了一些烦恼。比如,组件需要负责把异步请求的状态分发给子组件或通知给父组件,这个过程中,由组件间通信带来的结构复杂度、来源不明的数据源、不知从何订阅的数据响应会使得数据流变得杂乱无章,也使得代码可读性变差,以及可维护性的降低,为以后项目的迭代带来极大困难。
试想一下你都开发完了,产品告诉你要大改一番,从接口到组件结构都得改,后端也骂骂咧咧不愿配合让你从好几个 API 里取数据自己组合,这酸爽 😅
在一些产品链复杂的场景,后端需要提供对应 WebApp、WebPC、APP、小程序、快应用等各端 API,此时 API 的粒度大小就显得格外重要,粗粒度会导致移动端不必要的流量损耗,细粒度则会造成函数爆炸 (Function Explosion);在此情景下 Facebook 的工程师于 2015 年开源了 GraphQL 规范,让前端自己描述自己希望的数据形式,服务端则返回前端所描述的数据结构。
简单使用可以参照下面这个图:

比如前端希望返回一个 ID 为 233 的用户的名称和性别,并查找这个用户的前十个雇员的名字和 Email,再找到这个人父亲的电话,和这个父亲的狗的名字(别问我为什么有这么奇怪的查找 🤪),那么我们可以通过 GraphQL 的一次 query 拿到全部信息,无需从好几个异步 API 里面来回找:
query {
user (id : "233") {
name
gender
employee (first: 10) {
name
email
}
father {
telephone
dog {
name
}
}
}
}
返回的数据格式则刚好是前端提供的数据格式,不多不少,是不是心动了 😏
2. 几个重要概念
这里先介绍几个对理解 GraphQL 比较重要的概念,其他类似于指令、联合类型、内联片段等更复杂的用法,参考 GraphQL 官网文档 ~
2.1 操作类型 Operation Type
GraphQL 的操作类型可以是 query、mutation 或 subscription,描述客户端希望进行什么样的操作
- query 查询:获取数据,比如查找,CRUD 中的 R
- mutation 变更:对数据进行变更,比如增加、删除、修改,CRUD 中的 CUD
- substription 订阅:当数据发生更改,进行消息推送
这些操作类型都将在后文实际用到,比如这里进行一个查询操作
query {
user { id }
}
2.2 对象类型和标量类型 Object Type & Scalar Type
如果一个 GraphQL 服务接受到了一个 query,那么这个 query 将从 Root Query 开始查找,找到对象类型(Object Type)时则使用它的解析函数 Resolver 来获取内容,如果返回的是对象类型则继续使用解析函数获取内容,如果返回的是标量类型(Scalar Type)则结束获取,直到找到最后一个标量类型。
- 对象类型:用户在 schema 中定义的
type - 标量类型:GraphQL 中内置有一些标量类型
String、Int、Float、Boolean、ID,用户也可以定义自己的标量类型
比如在 Schema 中声明
type User {
name: String!
age: Int
}
这个 User 对象类型有两个字段,name 字段是一个为 String 的非空标量,age 字段为一个 Int 的可空标量。
2.3 模式 Schema
如果你用过 MongoOSE,那你应该对 Schema 这个概念很熟悉,翻译过来是『模式』。
它定义了字段的类型、数据的结构,描述了接口数据请求的规则,当我们进行一些错误的查询的时候 GraphQL 引擎会负责告诉我们哪里有问题,和详细的错误信息,对开发调试十分友好。
Schema 使用一个简单的强类型模式语法,称为模式描述语言(Schema Definition Language, SDL),我们可以用一个真实的例子来展示一下一个真实的 Schema 文件是怎么用 SDL 编写的:
# src/schema.graphql
# Query 入口
type Query {
hello: String
users: [User]!
user(id: String): [User]!
}
# Mutation 入口
type Mutation {
createUser(id: ID!, name: String!, email: String!, age: Int,gender: Gender): User!
updateUser(id: ID!, name: String, email: String, age: Int, gender: Gender): User!
deleteUser(id: ID!): User
}
# Subscription 入口
type Subscription {
subsUser(id: ID!): User
}
type User implements UserInterface {
id: ID!
name: String!
age: Int
gender: Gender
email: String!
}
# 枚举类型
enum Gender {
MAN
WOMAN
}
# 接口类型
interface UserInterface {
id: ID!
name: String!
age: Int
gender: Gender
}
这个简单的 Schema 文件从 Query、Mutation、Subscription 入口开始定义了各个对象类型或标量类型,这些字段的类型也可能是其他的对象类型或标量类型,组成一个树形的结构,而用户在向服务端发送请求的时候,沿着这个树选择一个或多个分支就可以获取多组信息。
注意:在 Query 查询字段时,是并行执行的,而在 Mutation 变更的时候,是线性执行,一个接着一个,防止同时变更带来的竞态问题,比如说我们在一个请求中发送了两个 Mutation,那么前一个将始终在后一个之前执行。
2.4 解析函数 Resolver
前端请求信息到达后端之后,需要由解析函数 Resolver 来提供数据,比如这样一个 Query:
query {
hello
}
那么同名的解析函数应该是这样的
Query: {
hello (parent, args, context, info) {
return ...
}
}
解析函数接受四个参数,分别为
parent:当前上一个解析函数的返回值args:查询中传入的参数context:提供给所有解析器的上下文信息info:一个保存与当前查询相关的字段特定信息以及 schema 详细信息的值
解析函数的返回值可以是一个具体的值,也可以是 Promise 或 Promise 数组。
一些常用的解决方案如 Apollo 可以帮省略一些简单的解析函数,比如一个字段没有提供对应的解析函数时,会从上层返回对象中读取和返回与这个字段同名的属性。
2.5 请求格式
GraphQL 最常见的是通过 HTTP 来发送请求,那么如何通过 HTTP 来进行 GraphQL 通信呢
举个栗子,如何通过 Get/Post 方式来执行下面的 GraphQL 查询呢
query {
me {
name
}
}
Get 是将请求内容放在 URL 中,Post 是在 content-type: application/json 情况下,将 JSON 格式的内容放在请求体里
# Get 方式
http://myapi/graphql?query={me{name}}
# Post 方式的请求体
{
"query": "...",
"operationName": "...",
"variables": { "myVariable": "someValue", ... }
}
返回的格式一般也是 JSON 体
# 正确返回
{
"data": { ... }
}
# 执行时发生错误
{
"errors": [ ... ]
}
如果执行时发生错误,则 errors 数组里有详细的错误信息,比如错误信息、错误位置、抛错现场的调用堆栈等信息,方便进行定位。
3. 实战
这里使用 MongoDB + graph-pack 进行一下简单的实战,并在实战中一起学习一下,详细代码参见 Github ~
MongoDB 是一个使用的比较多的 NoSQL,可以方便的在社区找到很多现成的解决方案,报错了也容易找到解决方法。
graph-pack 是集成了 Webpack + Express + Prisma + Babel + Apollo-server + Websocket 的支持热更新的零配置 GraphQL 服务环境,这里将其用来演示 GraphQL 的使用。
3.1 环境部署
首先我们把 MongoDB 启起来,这个过程就不赘述了,网上很多教程;
搭一下 graph-pack 的环境
npm i -S graphpack
在 package.json 的 scripts 字段加上:
"scripts": {
"dev": "graphpack",
"build": "graphpack build"
}
创建文件结构:
.
├── src
│ ├── db // 数据库操作相关
│ │ ├── connect.js // 数据库操作封装
│ │ ├── index.js // DAO 层
│ │ └── setting.js // 配置
│ ├── resolvers // resolvers
│ │ └── index.js
│ └── schema.graphql // schema
└── package.json
这里的 schema.graphql 是 2.3 节的示例代码,其他实现参见 Github,主要关注 src/db 、src/resolvers、src/schema.graphql 这三个地方
src/db:数据库操作层,包括 DAO 层和 Service 层(如果对分层不太了解可以看一下最后一章)src/resolvers:Resolver 解析函数层,给 GraphQL 的 Query、Mutation、Subscription 请求提供 resolver 解析函数src/schema.graphql:Schema 层
然后 npm run dev ,浏览器打开 http://localhost:4000/ 就可以使用 GraphQL Playground 开始调试了,左边是请求信息栏,左下是请求参数栏和请求头设置栏,右边是返回参数栏,详细用法可以参考 Prisma 文档
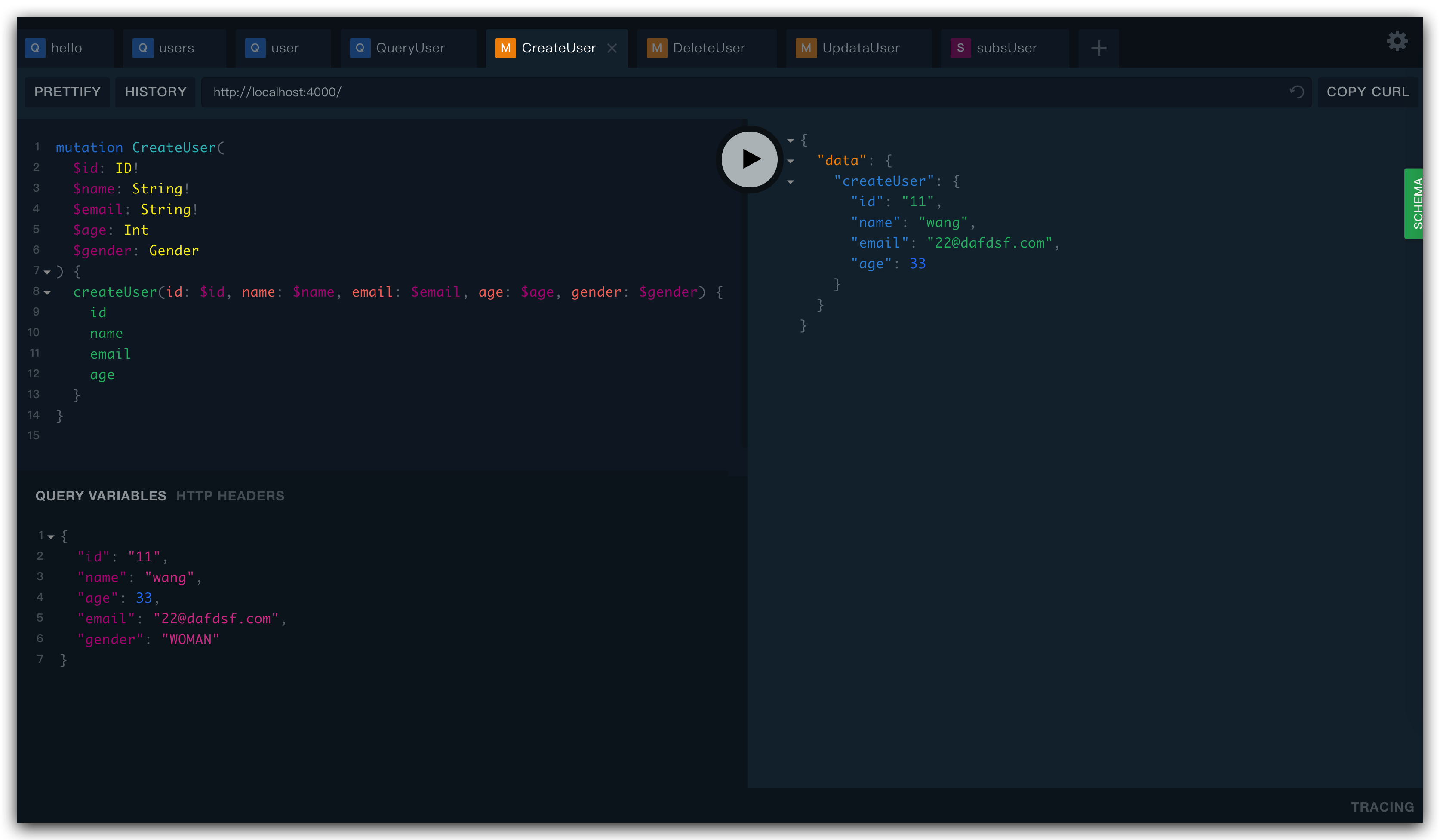
3.2 Query
首先我们来试试 hello world,我们在 schema.graphql 中写上 Query 的一个入口 hello,它接受 String 类型的返回值
# src/schema.graphql
# Query 入口
type Query {
hello: String
}
在 src/resolvers/index.js 中补充对应的 Resolver,这个 Resolver 比较简单,直接返回的 String
// src/resolvers/index.js
export default {
Query: {
hello: () => 'Hello world!'
}
}
我们在 Playground 中进行 Query
# 请求
query {
hello
}
# 返回值
{
"data": {
"hello": "Hello world!"
}
}
Hello world 总是如此愉快,下面我们来进行稍微复杂一点的查询
查询入口 users 查找所有用户列表,返回一个不可空但长度可以为 0 的数组,数组中如果有元素,则必须为 User 类型;另一个查询入口 user 接受一个字符串,查找 ID 为这个字符串的用户,并返回一个 User 类型的可空字段
# src/schema.graphql
# Query 入口
type Query {
user(id: String): User
users: [User]!
}
type User {
id: ID!
name: String!
age: Int
email: String!
}
增加对应的 Resolver
// src/resolvers/index.js
import Db from '../db'
export default {
Query: {
user: (parent, { id }) => Db.user({ id }),
users: (parent, args) => Db.users({})
}
}
这里的两个方法 Db.user、Db.users 分别是查找对应数据的函数,返回的是 Promise,如果这个 Promise 被 resolve,那么传给 resolve 的数据将被作为结果返回。
然后进行一次查询就可以查找我们所希望的所有信息
# 请求
query {
user(id: "2") {
id
name
email
age
}
users {
id
name
}
}
# 返回值
{
"data": {
"user": {
"id": "2",
"name": "李四",
"email": "mmmmm@qq.com",
"age": 18
},
"users": [{
"id": "1",
"name": "张三"
},{
"id": "2",
"name": "李四"
}]
}
}
注意这里,返回的数组只希望拿到 id、name 这两个字段,因此 GraphQL 并没有返回多余的数据,怎么样,是不是很贴心呢
3.3 Mutation
知道如何查询数据,还得了解增加、删除、修改,毕竟这是 CRUD 工程师必备的几板斧,不过这里只介绍比较复杂的修改,另外两个方法可以看一下 Github 上。
# src/schema.graphql
# Mutation 入口
type Mutation {
updateUser(id: ID!, name: String, email: String, age: Int): User!
}
type User {
id: ID!
name: String!
age: Int
email: String!
}
同理,Mutation 也需要 Resolver 来处理请求
// src/resolvers/index.js
import Db from '../db'
export default {
Mutation: {
updateUser: (parent, { id, name, email, age }) => Db.user({ id })
.then(existUser => {
if (!existUser)
throw new Error('没有这个id的人')
return existUser
})
.then(() => Db.updateUser({ id, name, email, age }))
}
}
Mutation 入口 updateUser 拿到参数之后首先进行一次用户查询,如果没找到则抛错,这个错将作为 error 信息返回给用户,Db.updateUser 这个函数返回的也是 Promise,不过是将改变之后的信息返回
# 请求
mutation UpdataUser ($id: ID!, $name: String!, $email: String!, $age: Int) {
updateUser(id: $id, name: $name, email: $email, age: $age) {
id
name
age
}
}
# 参数
{"id": "2", "name": "王五", "email": "xxxx@qq.com", "age": 19}
# 返回值
{
"data": {
"updateUser": {
"id": "2",
"name": "王五",
"age": 19
}
}
}
这样完成了对数据的更改,且拿到了更改后的数据,并给定希望的字段。
3.4 Subscription
GraphQL 还有一个有意思的地方就是它可以进行数据订阅,当前端发起订阅请求之后,如果后端发现数据改变,可以给前端推送实时信息,我们用一下看看。
照例,在 Schema 中定义 Subscription 的入口
# src/schema.graphql
# Subscription 入口
type Subscription {
subsUser(id: ID!): User
}
type User {
id: ID!
name: String!
age: Int
email: String!
}
补充上它的 Resolver
// src/resolvers/index.js
import Db from '../db'
const { PubSub, withFilter } = require('apollo-server')
const pubsub = new PubSub()
const USER_UPDATE_CHANNEL = 'USER_UPDATE'
export default {
Mutation: {
updateUser: (parent, { id, name, email, age }) => Db.user({ id })
.then(existUser => {
if (!existUser)
throw new Error('没有这个id的人')
return existUser
})
.then(() => Db.updateUser({ id, name, email, age }))
.then(user => {
pubsub.publish(USER_UPDATE_CHANNEL, { subsUser: user })
return user
})
},
Subscription: {
subsUser: {
subscribe: withFilter(
(parent, { id }) => pubsub.asyncIterator(USER_UPDATE_CHANNEL),
(payload, variables) => payload.subsUser.id === variables.id
),
resolve: (payload, variables) => {
console.log(' 接收到数据: ', payload)
}
}
}
}
这里的 pubsub 是 apollo-server 里负责订阅和发布的类,它在接受订阅时提供一个异步迭代器,在后端觉得需要发布订阅的时候向前端发布 payload。withFilter 的作用是过滤掉不需要的订阅消息,详细用法参照订阅过滤器。
首先我们发布一个订阅请求
# 请求
subscription subsUser($id: ID!) {
subsUser(id: $id) {
id
name
age
email
}
}
# 参数
{ "id": "2" }
我们用刚刚的数据更新操作来进行一次数据的更改,然后我们将获取到并打印出 pubsub.publish 发布的 payload,这样就完成了数据订阅。
在 graph-pack 中数据推送是基于 websocket 来实现的,可以在通信的时候打开 Chrome DevTools 看一下。
4. 总结
目前前后端的结构大概如下图。后端通过 DAO 层与数据库连接实现数据持久化,服务于处理业务逻辑的 Service 层,Controller 层接受 API 请求调用 Service 层处理并返回;前端通过浏览器 URL 进行路由命中获取目标视图状态,而页面视图是由组件嵌套组成,每个组件维护着各自的组件级状态,一些稍微复杂的应用还会使用集中式状态管理的工具,比如 Vuex、Redux、Mobx 等。前后端只通过 API 来交流,这也是现在前后端分离开发的基础。
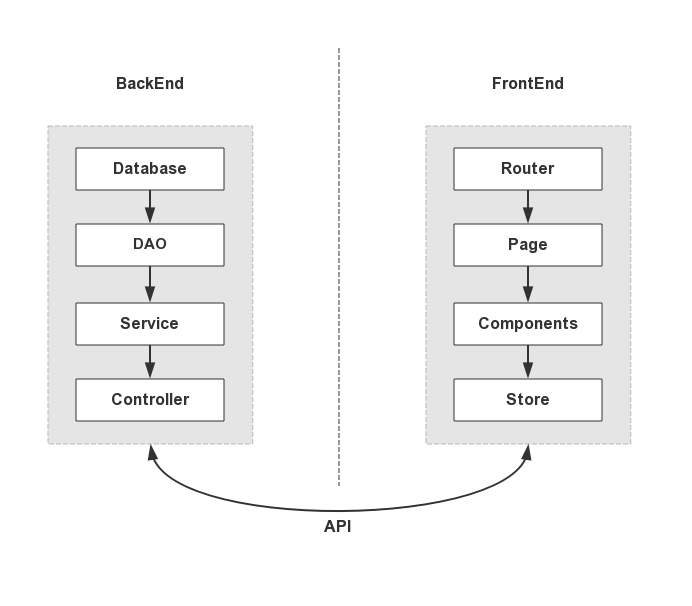
如果使用 GraphQL,那么后端将不再产出 API,而是将 Controller 层维护为 Resolver,和前端约定一套 Schema,这个 Schema 将用来生成接口文档,前端直接通过 Schema 或生成的接口文档来进行自己期望的请求。
经过几年一线开发者的填坑,已经有一些不错的工具链可以使用于开发与生产,很多语言也提供了对 GraphQL 的支持,比如 JavaScript/Nodejs、Java、PHP、Ruby、Python、Go、C# 等。
一些比较有名的公司比如 Twitter、IBM、Coursera、Airbnb、Facebook、Github、携程等,内部或外部 API 从 RESTful 转为了 GraphQL 风格,特别是 Github,它的 v4 版外部 API 只使用 GraphQL。据一位在 Twitter 工作的大佬说硅谷不少一线二线的公司都在想办法转到 GraphQL 上,但是同时也说了 GraphQL 还需要时间发展,因为将它使用到生产环境需要前后端大量的重构,这无疑需要高层的推动和决心。
正如尤雨溪所说,为什么 GraphQL 两三年前没有广泛使用起来呢,可能有下面两个原因:
- GraphQL 的 field resolve 如果按照 naive 的方式来写,每一个 field 都对数据库直接跑一个 query,会产生大量冗余 query,虽然网络层面的请求数被优化了,但数据库查询可能会成为性能瓶颈,这里面有很大的优化空间,但并不是那么容易做。FB 本身没有这个问题,因为他们内部数据库这一层也是抽象掉的,写 GraphQL 接口的人不需要顾虑 query 优化的问题。
- GraphQL 的利好主要是在于前端的开发效率,但落地却需要服务端的全力配合。如果是小公司或者整个公司都是全栈,那可能可以做,但在很多前后端分工比较明确的团队里,要推动 GraphQL 还是会遇到各种协作上的阻力。
大约可以概括为性能瓶颈和团队分工的原因,希望随着社区的发展,基础设施的完善,会渐渐有完善的解决方案提出,让广大前后端开发者们可以早日用上此利器。
网上的帖子大多深浅不一,甚至有些前后矛盾,在下的文章都是学习过程中的总结,如果发现错误,欢迎留言指出~
参考:
欢迎大家关注我的专栏 《JavaScript 设计模式精讲》
共同学习,写下你的评论
评论加载中...
作者其他优质文章



