
一、几个np的常用函数
①np.sum:相比于简单的相加,sum可以实现矩阵相加。应用于两个list需要相加,可以用for循环逐个相加,亦可以sum
②np.dot/np.multiply:前者是真正意义上的矩阵乘法,后面的只是相应的位置相乘,从而得到一个结果
③np.float_,将正数转换成float,很多结果需要小数形式表示
二、交叉熵
首先看一个图,这个图通过对四个点进行计算,得到其判断的结果及相应的概率
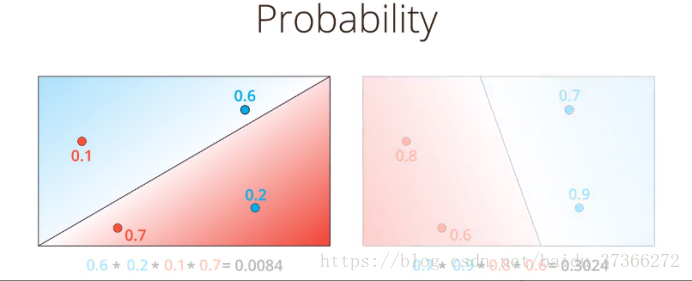
有两个判定结果,那么我们怎么判断哪个2结果更好呢?
我们引入交叉熵的概念,交叉熵越小,表示结果越好
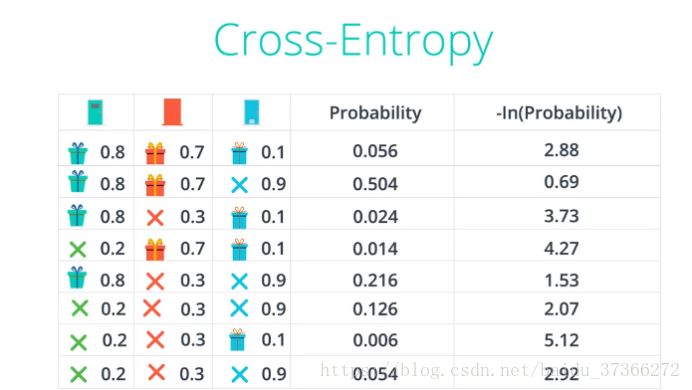
如图所示,我们通过分类得到三个颜色对应有礼物的概率分别为0.8,0.7,0.1
那么现实中哪种情况更有可能呢?
最右面一列,利用公式计算
为什么用 ln() 函数 :约定俗称 + 计算出的数值合理,得到一个最小的,即可以判断我们最可能的情况

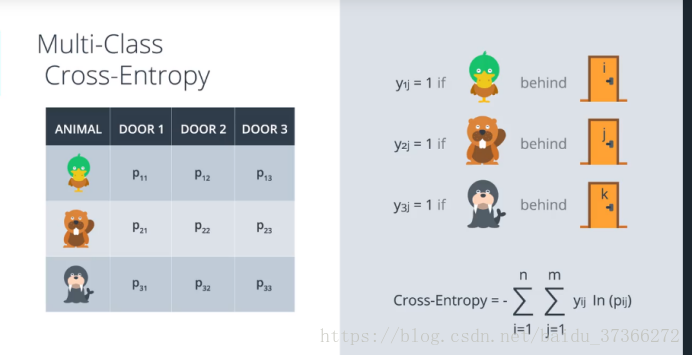
那么这是有或者没有,两种情况,那么对于三种情况呢?例如我们在图像识别,可能是鸭子,企鹅,大象
我们引入一个单热点编码,得到一个类似的二维矩阵,可以想象上面的是这个方程的 m = 2时候的形式
三、误差函数

我们先来看一段代码
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def output_formula(features, weights, bias):
return sigmoid(np.dot(features, weights) + bias)
def error_formula(y, output):
return - y*np.log(output) - (1 - y) * np.log(1-output)
def update_weights(x, y, weights, bias, learnrate):
output = output_formula(x, weights, bias)
d_error = -(y - output)
weights -= learnrate * d_error * x #//////////////
bias -= learnrate * d_error #############
return weights, bias
做标注的两行进行了权值更新,即x - 学习率*x*(y-output) //当然后面的 y-output不一定是这样,对于不同的损失函数也不同
共同学习,写下你的评论
评论加载中...
作者其他优质文章



