
最近正好在看这本小说,网上广告属实多了点,而且好多存在断章的情况,所以自己去网上下载下来电脑或者手机上看最实际了
1. 首页
对没错,就是这本都市小说《道德天书》,从首页还是很容易能够获取到章节链接的
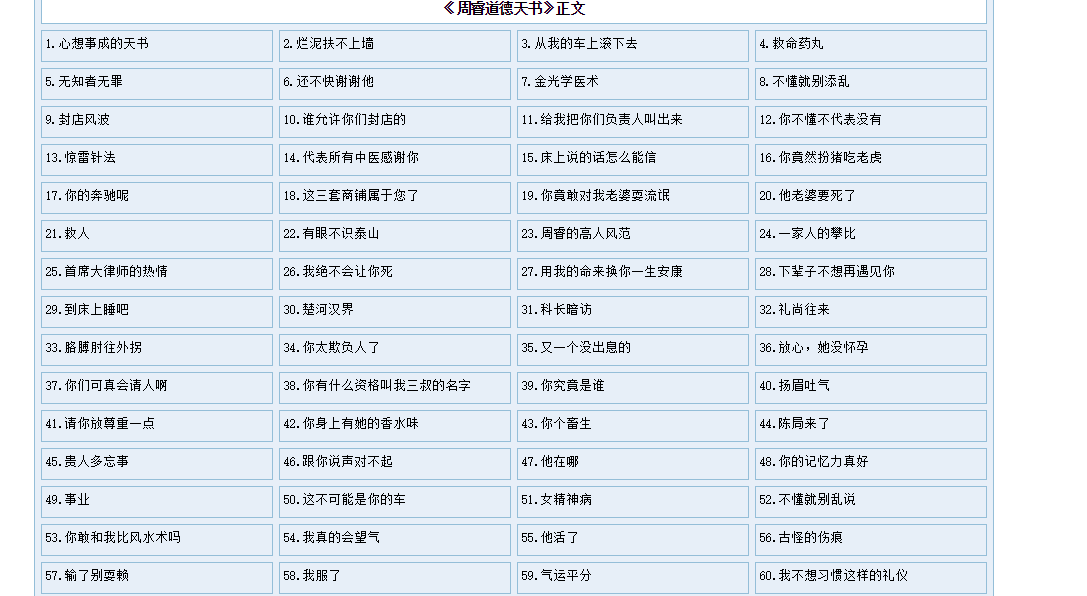
2. 内容页
内容页面有点小陷阱,虽然看着简单,但是实际将页面的内容打印出来是残缺的,他只构建了部分文本内容,实际的内容是需要自己抓包获取,不信的话可以打印页面内容看看,是不完整的
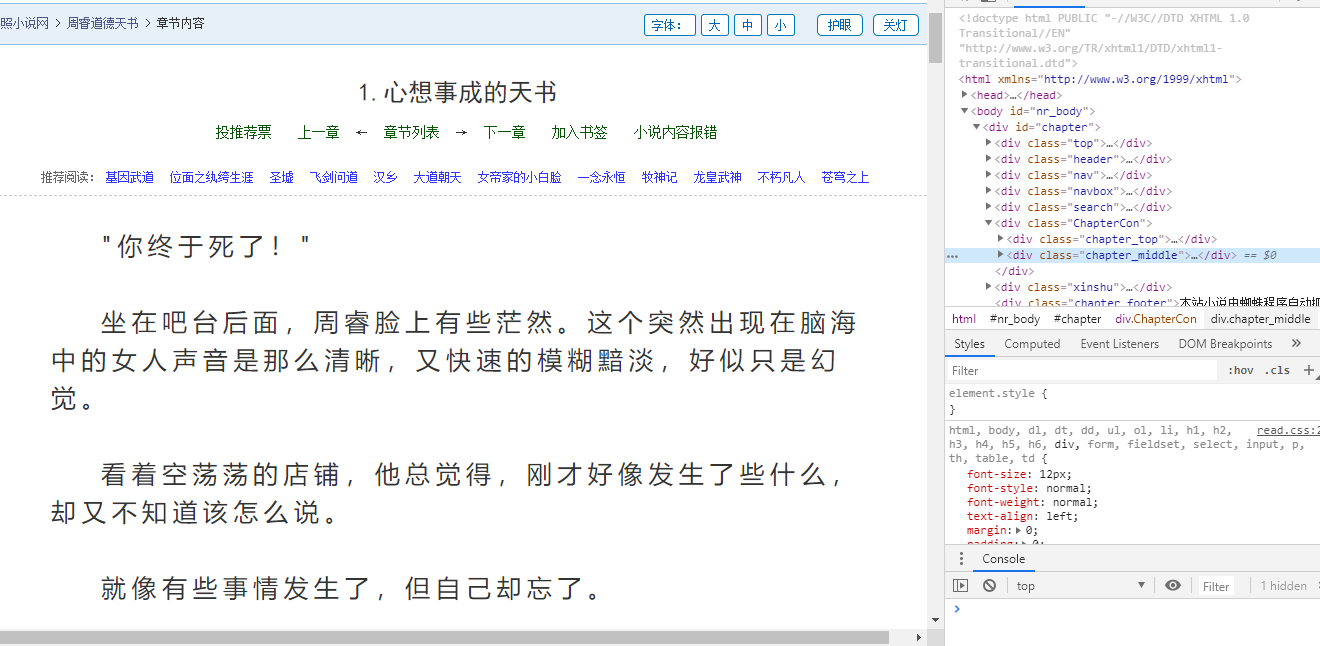
3. 抓包
这里规则还是比较简单的,很容易就找到了对应的数据包
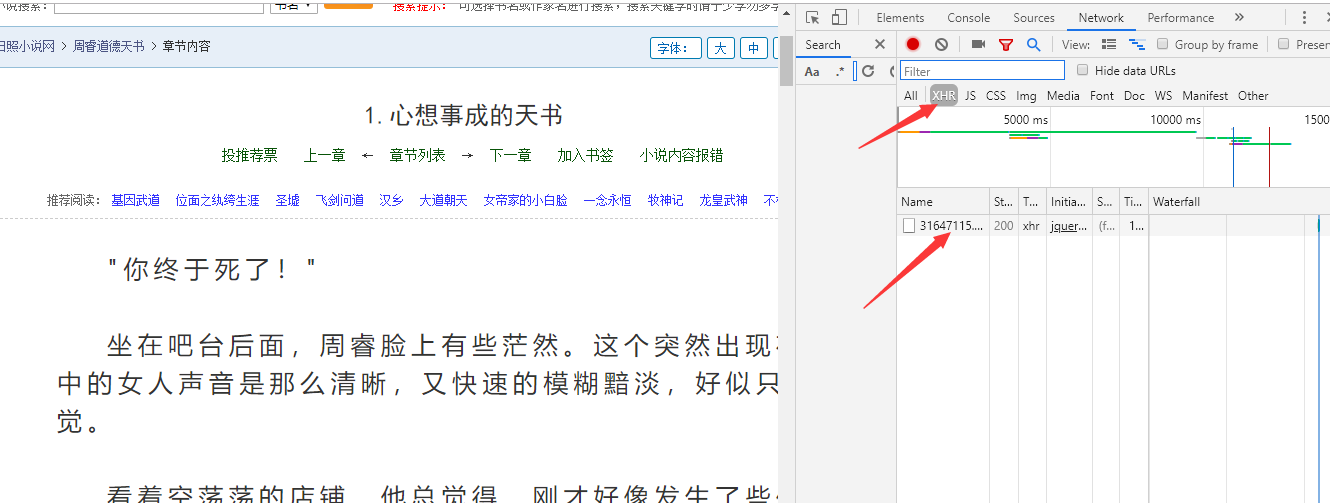
我们选择数据包的
headers进入里面显示的真实链接就可以看到具体的内容了
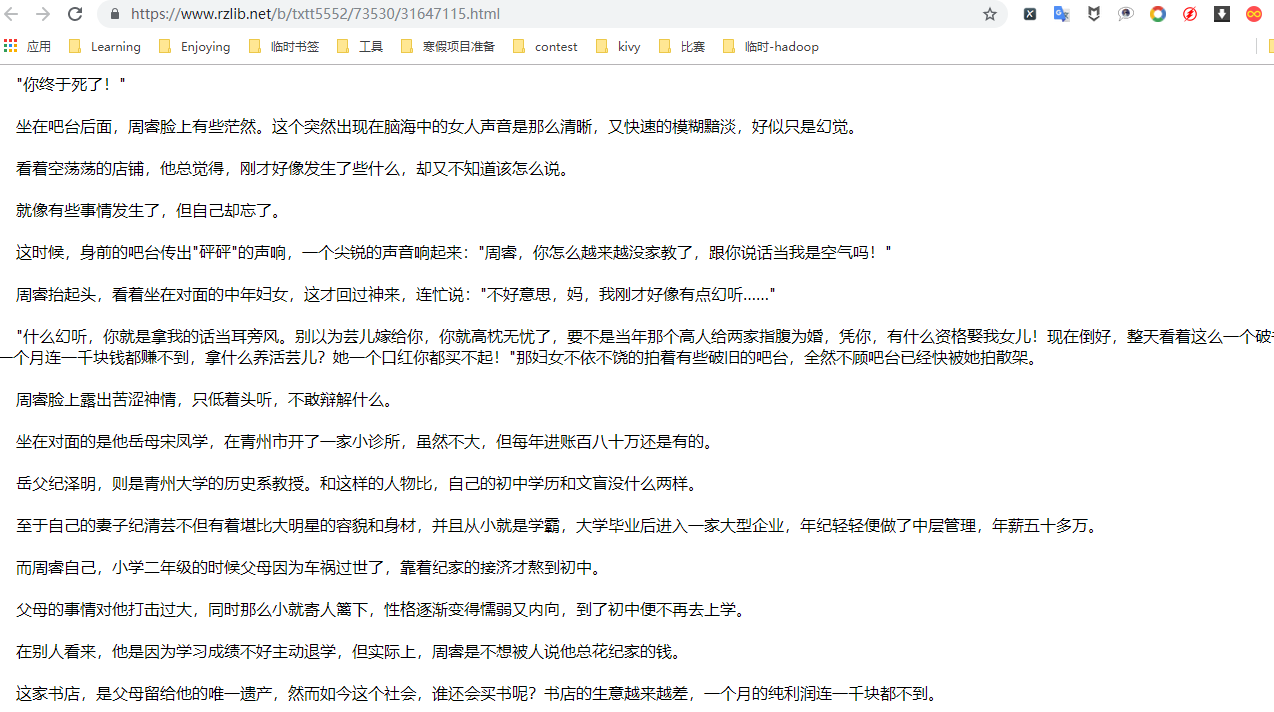
4. 数据获取
所有的数据来源我们都知道了,就着手开始建设了,首先从首页遍历所有章节的页面链接,从每个章节的页面中获取到标题和内容,没错,这里的内容需要去数据包中获取,仔细观察会发现数据包的链接恰巧就是网页主页链接+章节链接的后两项,所以能够很轻易的组合出来,后面的内容无非是获取,写入。
- 这里因为内容中还是存在广告,所以用
replace将它剔除了,其他的就是xpath解析,写入了
#!/usr/bin/env python
# -*- coding:utf-8 -*-
'''
@author: maya
@software: Pycharm
@file: tqdm.py
@time: 2019/8/20 14:08
@desc:
'''
import requests
from lxml import etree
headers = {
'cookie': 'Hm_lvt_33b927fed41089db72f5d741701b24f2=1566285504; SL_GWPT_Show_Hide_tmp=1; SL_wptGlobTipTmp=1; Hm_lpvt_33b927fed41089db72f5d741701b24f2=1566285551',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36',
'upgrade-insecure-request': '1',
'referer': 'https://www.rzlib.net/b/73/73530/',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3'
}
def get_html(url):
return requests.get(url, headers=headers)\
.text.replace('如果您觉得《周睿道德天书》还不错的话,请粘贴以下网址分享给你的QQ、'
'微信或微博好友,谢谢支持!', '').replace('( 本书网址:https://www.'
'rzlib.net/b/73/73530/ )', '')
def get_data(url):
html = etree.HTML(get_html(url))
title = html.xpath('//h1/text()')[0].replace('.', '_')
content_url = get_url(url)
content_html = etree.HTML(get_html(content_url)).xpath('//body//text()')
content = ["".join(data.split()) for data in content_html]
return title, content
def get_url(url):
return "https://www.rzlib.net/b/txtt5552/" + url.split('/')[-2] + "/" + url.split('/')[-1]
def write_data(url):
title, content = get_data(url)
with open('books/' + title + '.txt', 'w', encoding='utf-8') as f:
f.write(title.replace('_', '. ') + '\n')
for data in content:
if data != "":
f.write(' ' + data + '\n')
with open('books/books.txt', 'a', encoding='utf-8') as p:
p.write(title.replace('_', '. ') + '\n')
for data in content:
if data != "":
p.write(' ' + data + '\n')
p.write('\n')
def get_total(index_utl):
html = etree.HTML(get_html(index_utl))
urls = html.xpath('//div[@class="ListChapter"][2]/ul/li/a/@href')
for url in urls:
write_data("https://www.rzlib.net" + url)
print("第{}章已完成写入".format(urls.index(url) + 1))
if __name__ == '__main__':
get_total("https://www.rzlib.net/b/73/73530/")
- 代码参考Github
点击查看更多内容
1人点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中




感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦