
我们从这个网站上获取想要的内容,不用考虑太多的板块,直接按照字母检索即可
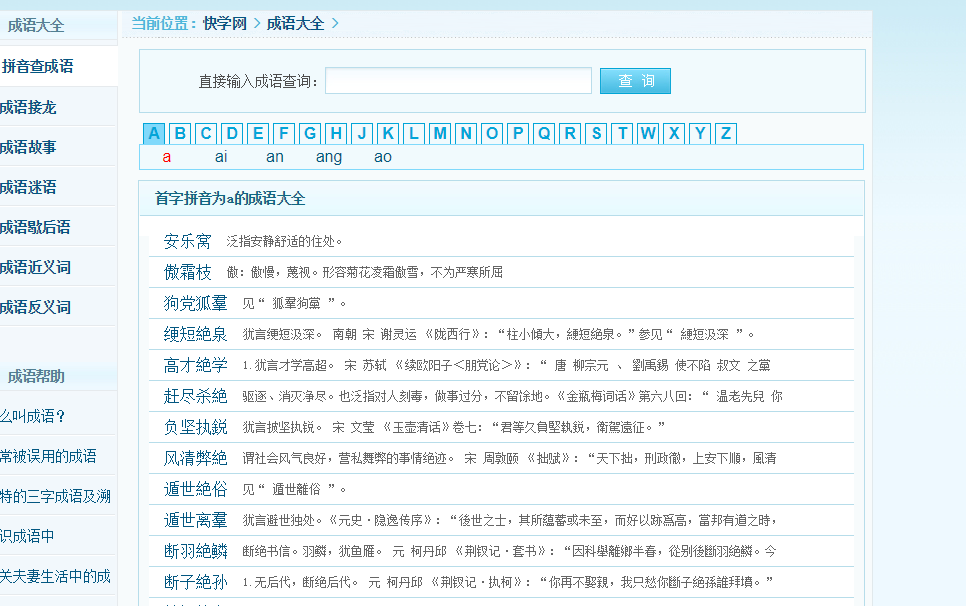
进去每个字母的页面中获取数据以及循环页数,值得注意的是页面中有相当多的重复项,记得进行去重操作
1. 页面获取
常规套路,因为这里需要用到
xpath,所以直接返回html字符串,这里因为数据中有大量中文繁体字的原因,选择字符编码为gbk
def get_html(url):
r = requests.get(url, headers=headers)
r.encoding = 'gbk'
return r.text
2. 当前页数据获取
页面中的成语以及释义都是保存在列表中的,直接对列表遍历获取即可(仅当前页),值得注意的是需要对重复项清洗,这里使用匿名函数
lambda z: dict([(x, y) for y, x in z.items()]),对字典的键值执行两次翻转
def get_curr(url):
html = etree.HTML(get_html(url))
lis = html.xpath('//li[@class="licontent"]')
context = {}
for li in lis:
if li.xpath('./span[@class="hz"]/a/text()') and li.xpath('./span[@class="js"]/text()'):
idiom = li.xpath('./span[@class="hz"]/a/text()')[0]
interpretation = li.xpath('./span[@class="js"]/text()')[0]
context[idiom] = interpretation
func = lambda z: dict([(x, y) for y, x in z.items()])
idiom_dict = func(func(context))
return idiom_dict
3. 页数循环
页面底部有页数的标签,包括总页数、当前页、末页、下一页等,但是如果总页面仅1页的就没有任何显示,到达项目尾页时就没有任何页数标签显示了(怪不怪?),我们这里就获取到总页数和当前的字母索引即可,这里的
write_data和
def run(url, context):
html = etree.HTML(get_html(url))
if html.xpath('//a[contains(text(), "末页")]/@href'):
text = html.xpath('//a[contains(text(), "末页")]/@href')[0]
letter = re.search('\w', text).group(0) or url.split('/')[-1][0]
total = re.search('\d+', text).group(0) or 1
else:
letter = url.split('/')[-1][0]
total = 1
for num in range(1, int(total) + 1):
page_context = get_curr('http://chengyu.kxue.com/pinyin/' + letter + '_' + str(num) + '.html')
context.update(page_context)
print("完成{}的添加,共{}".format(letter + '_' + str(num), total))
#write_data('grandSon/' + url.split('/')[-1][0] + '.json', context)
#print("完成{}的写入".format(url.split('/')[-1][0]))
return context
4. 数据写入
直接转成
json写入文件,可以调整一下格式
def write_data(file, context):
with open(file, 'w', encoding='utf-8') as f:
f.write(json.dumps(context, indent=2, ensure_ascii=False))
5. 遍历所有字母
去网页主页遍历所有字母的链接,然后对每个链接调用以上方法即可
url = "http://chengyu.kxue.com/"
html = etree.HTML(get_html(url))
file = 'idiom.json'
context = {}
urls = html.xpath('//div[@class="content letter"]/li/a/@href')
for url in urls:
context.update(run("http://chengyu.kxue.com" + url, {}))
write_data(file, context)
- 代码参考Github
点击查看更多内容
1人点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中




感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦