
去官网下载压缩包
配置jdk(hadoop运行在java环境上)
Hadoop 2.x基本配置及运行MapReduce案例在本地模式下
在hadoop文件下
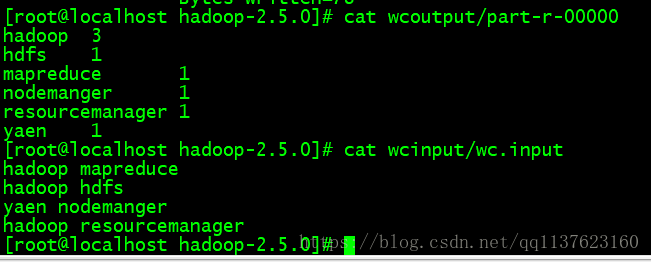
mkdir input cp etc/hadoop/*.xml input/ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar grep input output 'dfs[a-z.]+'cat output/part-r-00000 ##小案例mkdir wcinput cd wcinput/ touch wc.input vi wc.input hadoop mapreduce hadoop hdfs yaen nodemanger hadoop resourcemanager bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar woedcount wcinput wcoutputeduce-examples-2.5.0.jar wordcount wcinput wcoutput12345678910111213141516
配置部署启动HDFS及本地模式运行MapReduce案例(使用HDFS上数据)
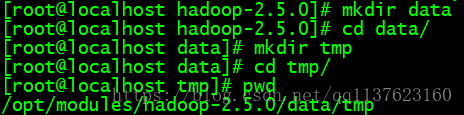
修改主机名:
vi /etc/sysconfig/network vi /etc/hosts /etc/rc.d/init.d/network restart123
修改/opt/modules/hadoop-2.5.0/etc/hadoop/core-site.xml 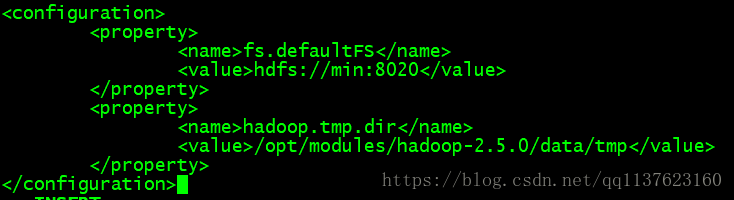
修改/opt/modules/hadoop-2.5.0/etc/hadoop/hdfs-site.xml 
格式化hdfs
bin/hdfs namenode -format1
启动主节点
sbin/hadoop-daemon.sh start namenode1
启动从节点
sbin/hadoop-daemon.sh start datanode1
查看hadoop控制台 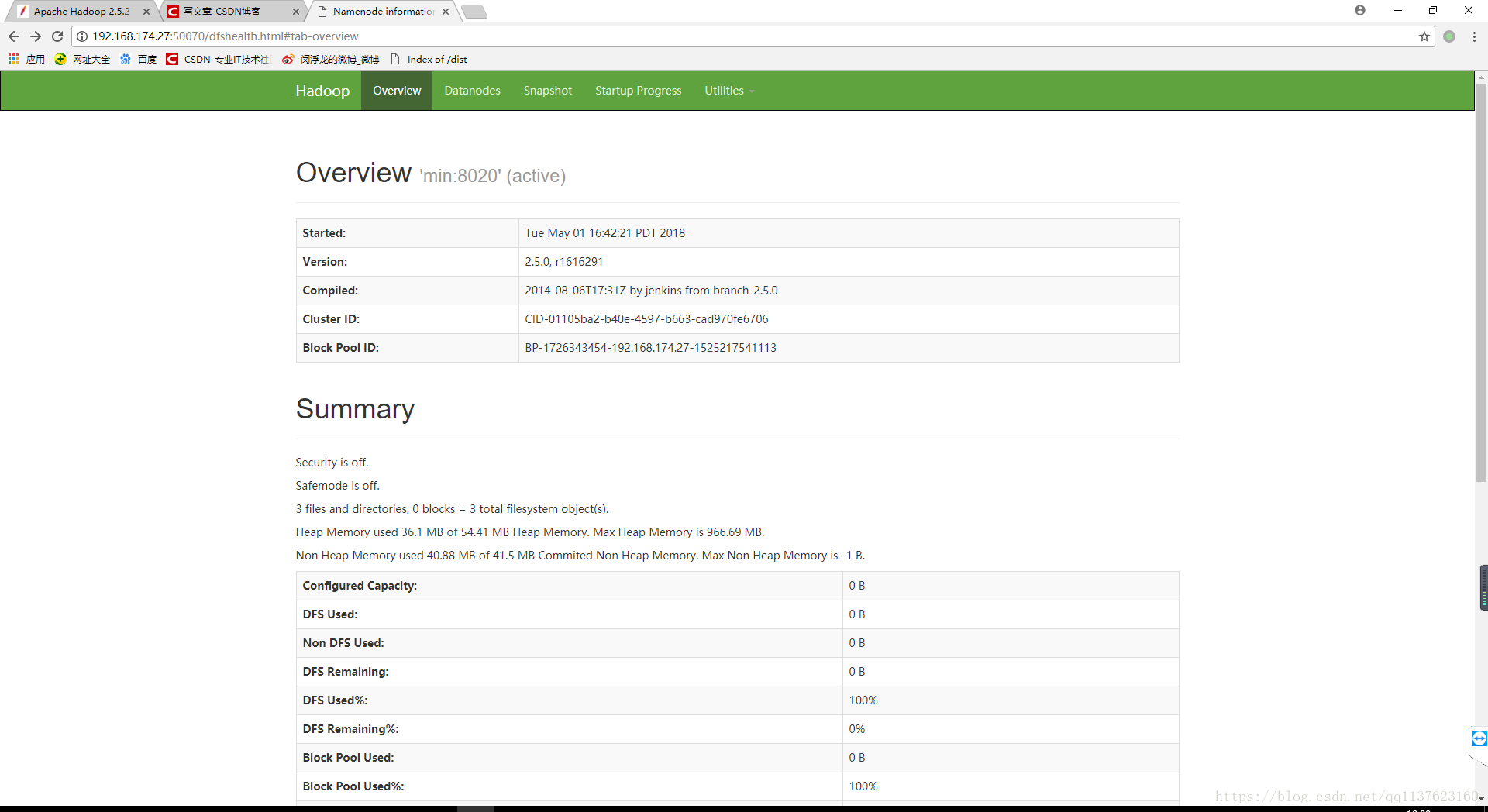
新增hdfs文件
bin/hdfs dfs -mkdir -p /user/beifeng/1
查询hdfs文件
bin/hdfs dfs -ls -R /1
hdfs上传文件
bin/hdfs dfs -put wcinput/wc.input /user/beifeng/mapreduce/wordcount/input/1
运行MapReduce程序
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar woedcount /user/beifeng/mapreduce/wordcount/input/ /user/beifeng/mapreduce/wordcount/output1
查看运行结果
bin/hdfs dfs -cat /user/beifeng/mapreduce/wordcount/output/part*1
配置部署启动YARN及在YARN上运行MapReduce程序
配置yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>min</value> </property></configuration>12345678910111213
配置slaves
vi etc/hadoop/slaves min123
启动:
sbin/yarn-daemon.sh start resourcemanager sbin/yarn-daemon.sh start nodemanager12
访问: 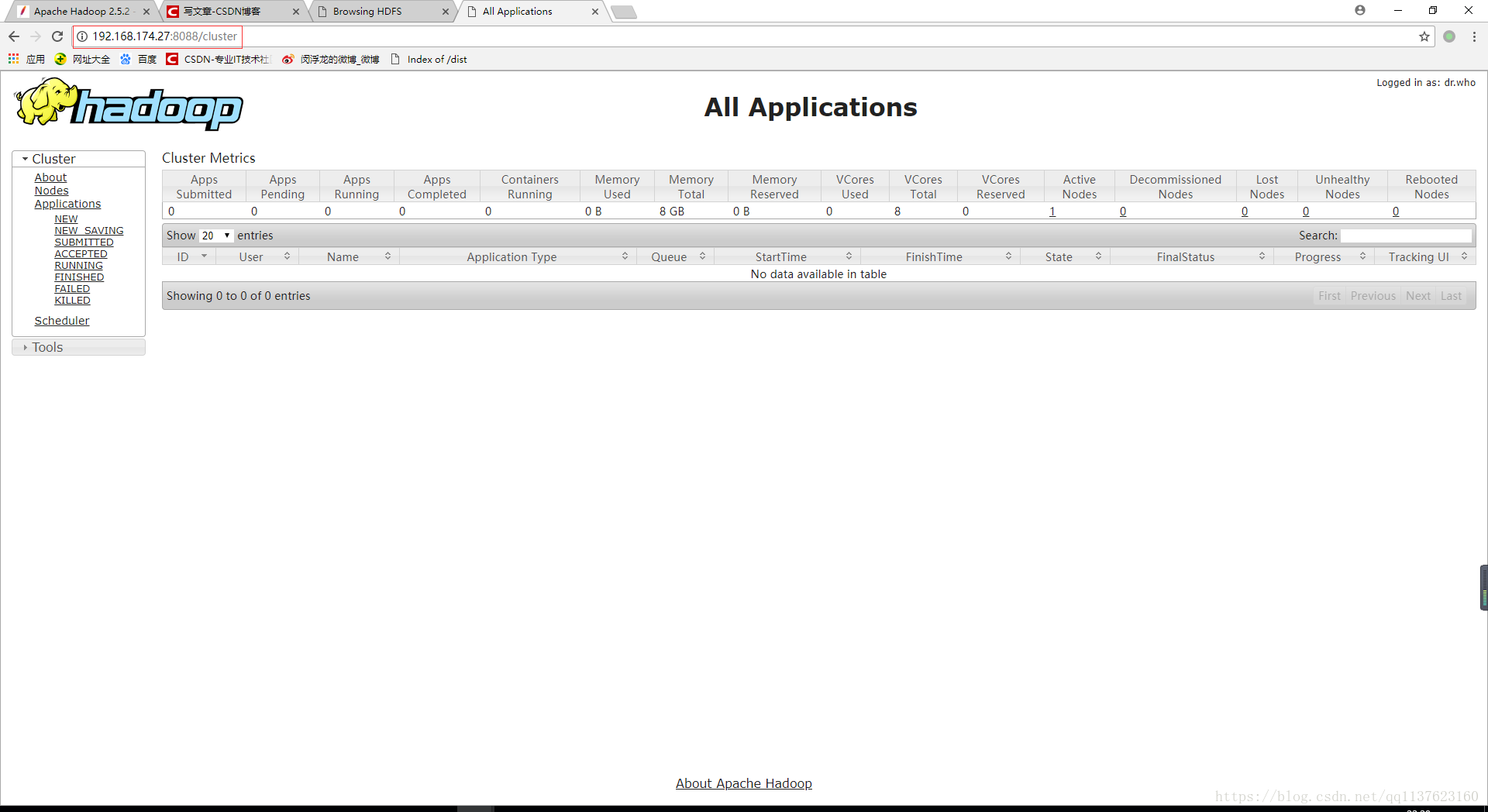
配置mapred-env.sh
vi etc/hadoop/mapred-env.sh ##修改jdk配置路径export JAVA_HOME=/usr/java/jdk1.8.0_11123
历史任务服务器启动
sbin/mr-jobhistory-daemon.sh start historyserver1
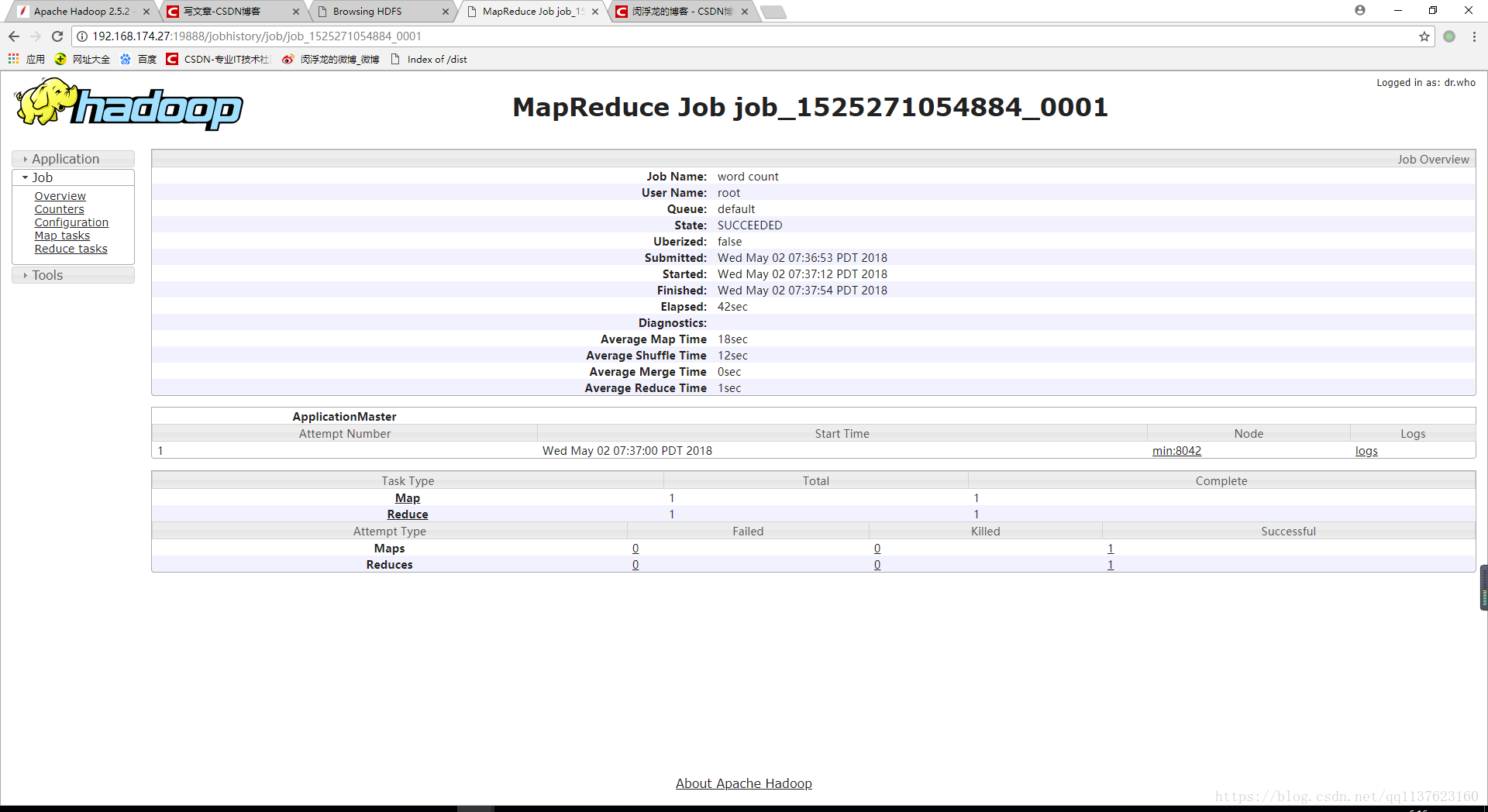
YARN的日志聚集功能配置使用
日志聚集功能配置 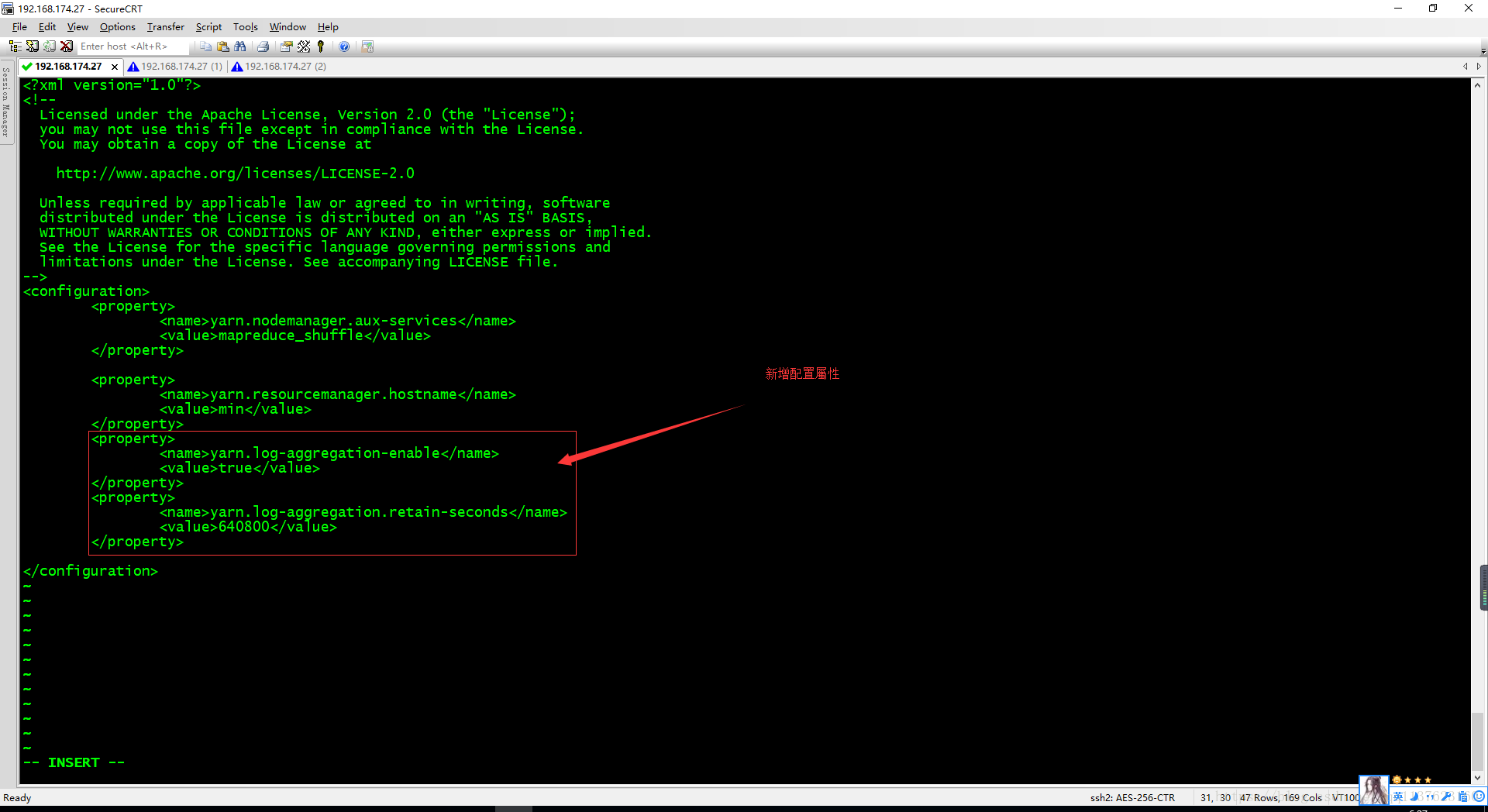
停止resourcemanager
sbin/yarn-daemon.sh stop resourcemanager1
停止noderesourcemanager
sbin/yarn-daemon.sh stop nodemanager1
停止历史任务服务器
sbin//mr-jobhistory-daemon.sh stop historyserver1
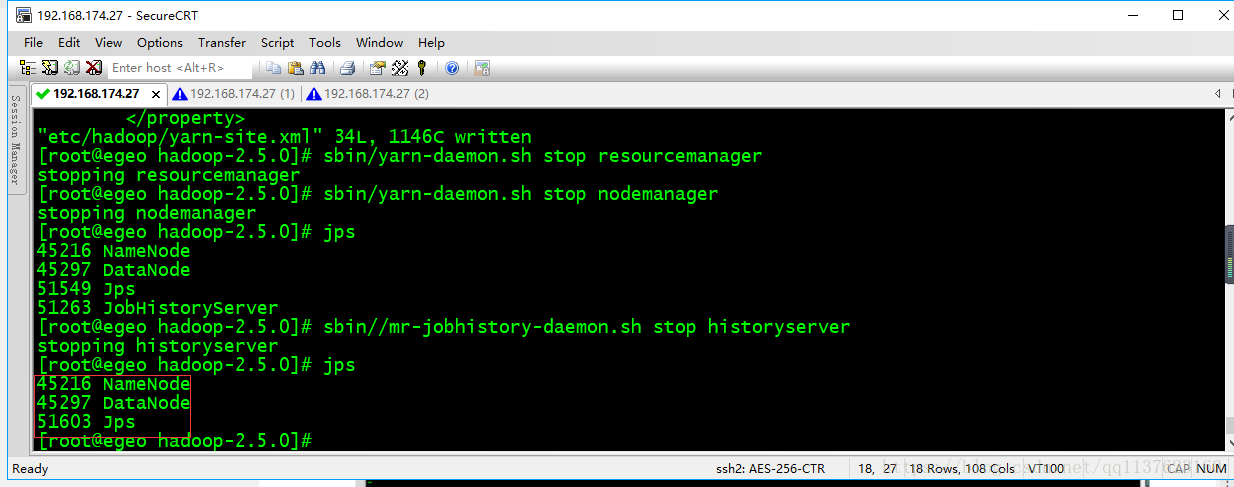
启动resourcemanager、resourcemanager、历史任务服务器 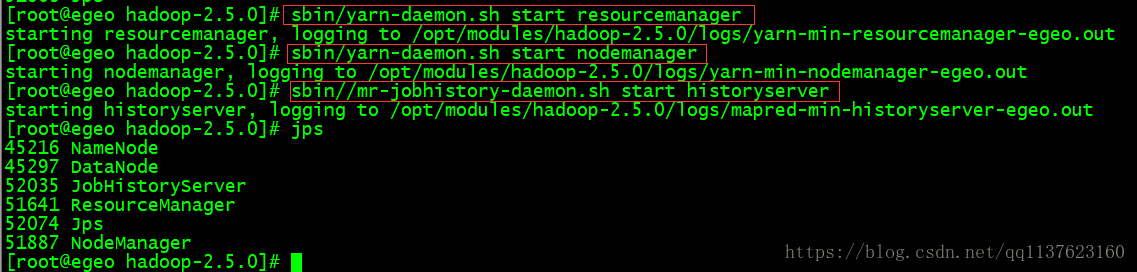
查看log日志 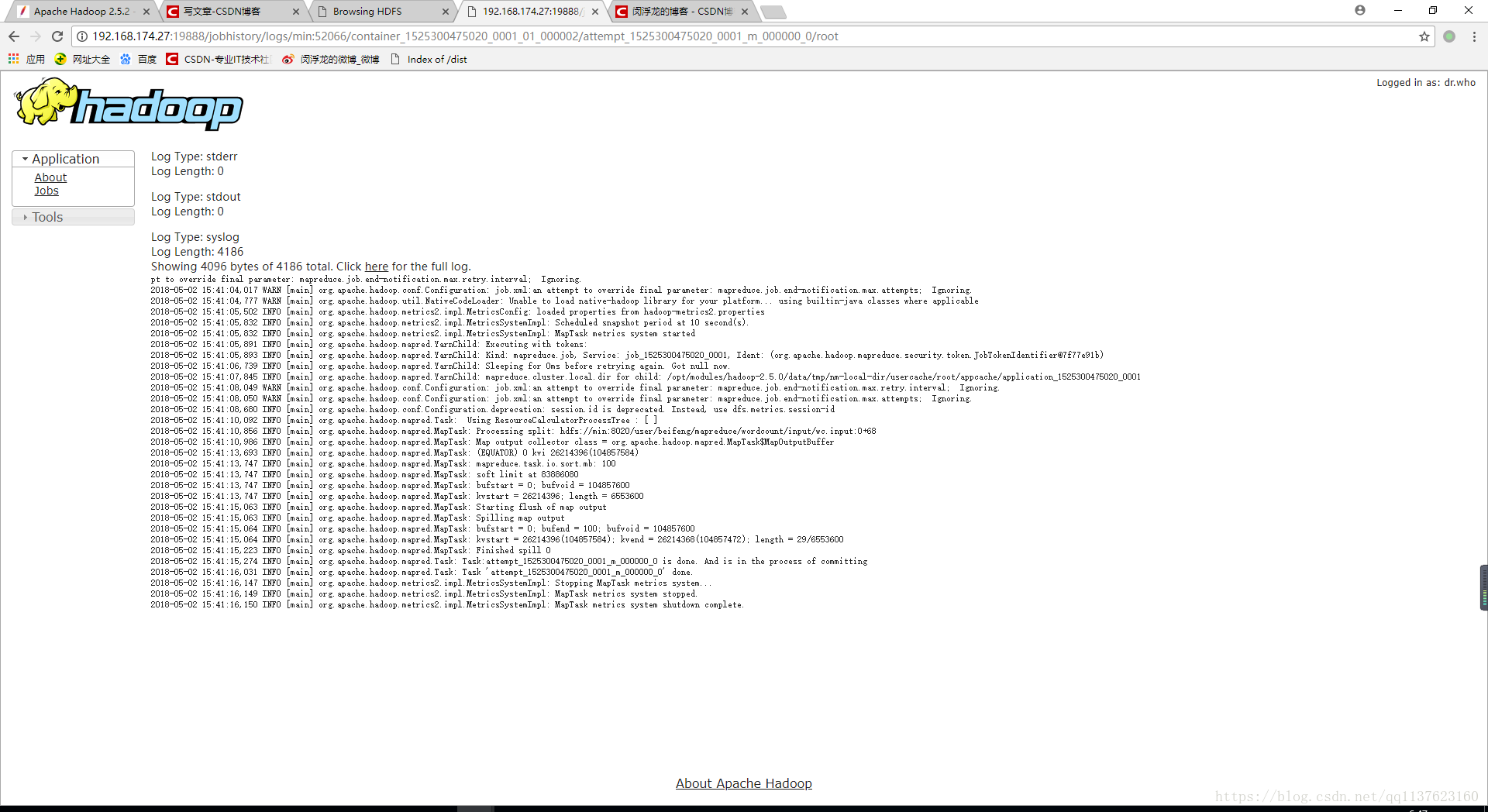
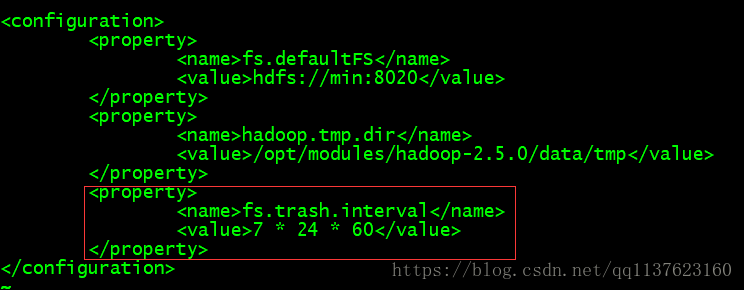
配置HDFS垃圾回收
vi etc/hadoop/core-site.xml 1

Hadoop 2.x组件启动的三种方式及配置SSH无密码登录
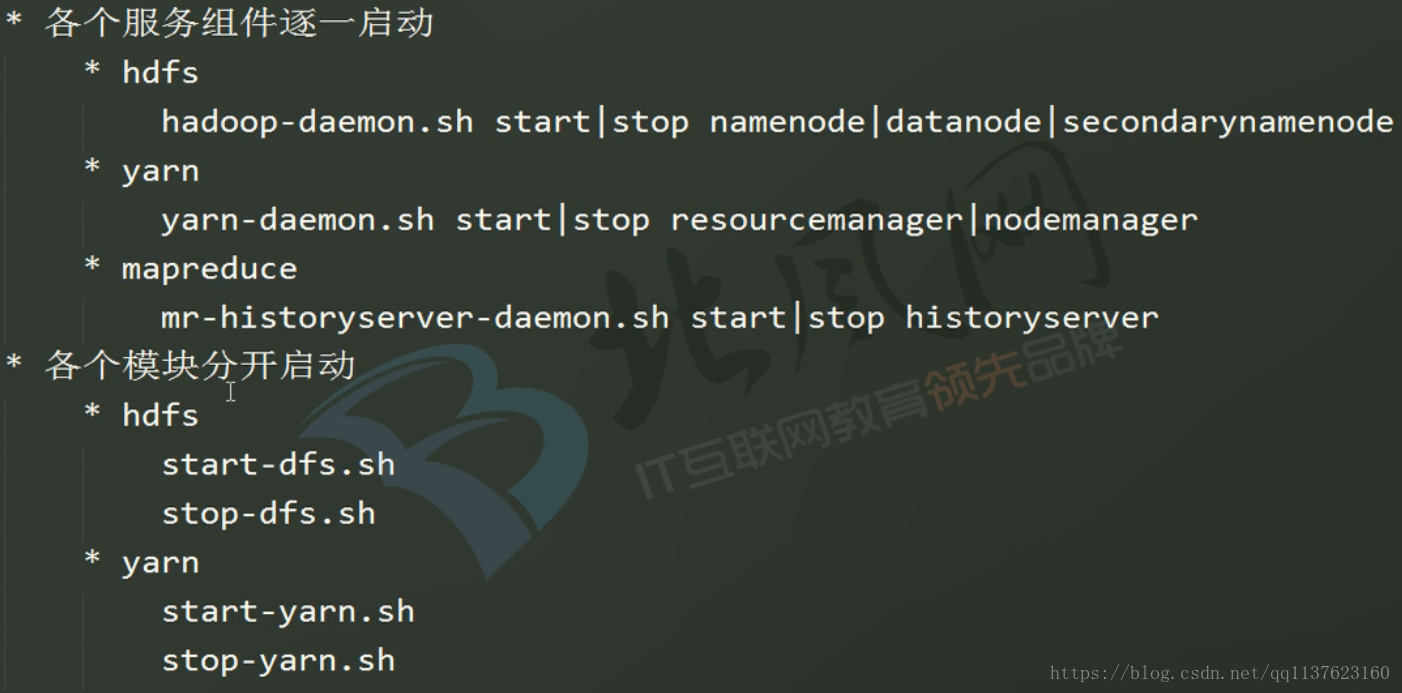
不建议用下面这种 
配置SSH无密码登录
cd cd .ssh ssh-keygen -t rsa ssh-copy-id min1234

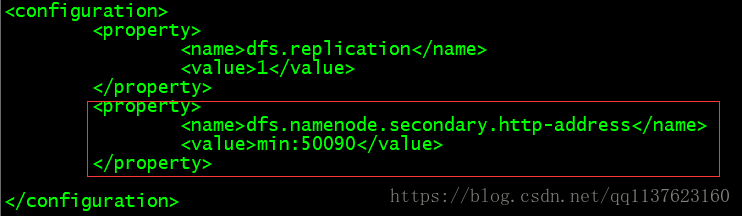
配置namenode第二个节点
vi etc/hadoop/hdfs-site.xml1
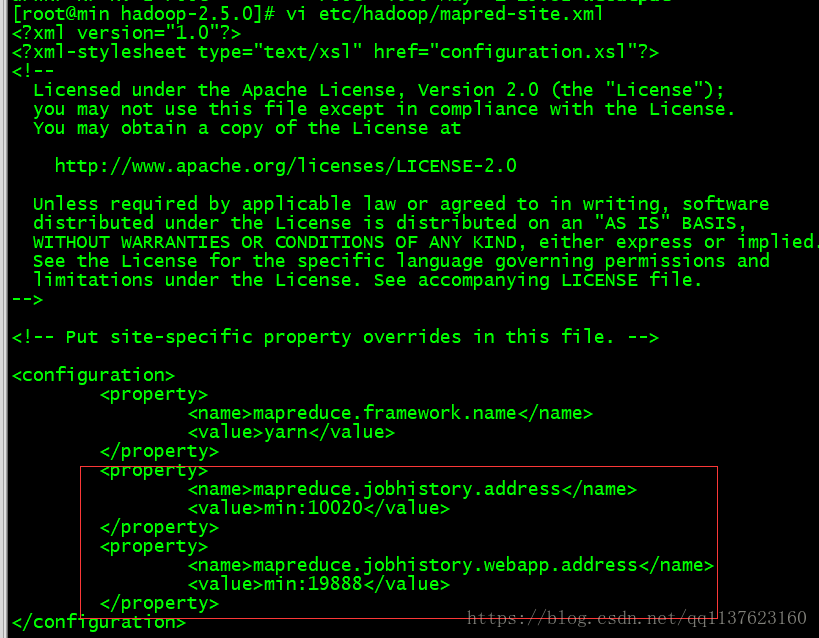
配置历史服务器
vi etc/hadoop/mapred-site.xml1
点击查看更多内容
为 TA 点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中




感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦