
学 Python,从爬女神开始,做网站开始
先来看看最后做成的网站(https://nvshen.luobodazahui.top/#)

支持给心仪的女神点赞加星哦!
啥也不说,今天是来送福利的
女神大会
不是知道有多少人知道“懂球帝”这个 APP(网站),又有多少人关注过它的一个栏目“女神大会”,在这里,没有足球,只有女神哦。
画风是这样的
女神评分,全部是由球迷来决定,是不是很赤鸡,下面就一起来看看球迷眼中女神排名吧。
开工
获取 ID 信息
首先,我们可以通过抓取懂球帝 APP 的网络请求,拿到一个 API,
http://api.dongqiudi.com/search?keywords=type=all&page=
该 API ,我们能够拿到如下信息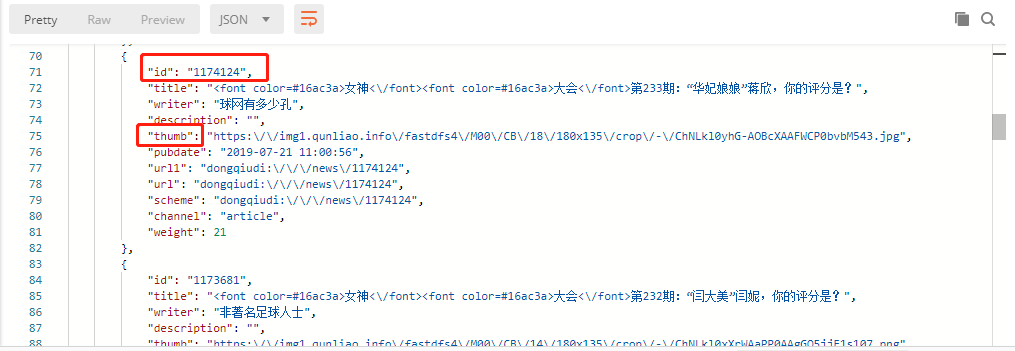
我们主要关注 ID 和 thumb,ID 后面用来拼接女神所在页面的 HTML 地址,thumb 就用来收藏。
于是,我们就可以得到一个简单的解析函数
def get_list(page):
nvshen_id_list = []
nvshen_id_picture = []
for i in range(1, page):
print("获取第" + str(i) + "页数据")
url = 'http://api.dongqiudi.com/search?keywords=%E5%A5%B3%E7%A5%9E%E5%A4%A7%E4%BC%9A&type=all&page=' + str(i)
html = requests.get(url=url).text
news = json.loads(html)['news']
if len(news) == 0:
print("没有更多啦")
break
nvshen_id = [k['id'] for k in news]
nvshen_id_list = nvshen_id_list + nvshen_id
nvshen_id_picture = nvshen_id_picture + [{k['id']: k['thumb']} for k in news]
time.sleep(1)
return nvshen_id_list, nvshen_id_picture
下载 HTML 页面
接下来,通过观察,我们能够得到,每个女神所在的页面地址都是这样的,
https://www.dongqiudi.com/archive/**.html
其中 ** 就是上面拿到的 ID 值,那么获取 HTML 页面的代码也就有了
def download_page(nvshen_id_list):
for i in nvshen_id_list:
print("正在下载ID为" + i + "的HTML网页")
url = 'https://www.dongqiudi.com/archive/%s.html' % i
download = DownloadPage()
html = download.getHtml(url)
download.saveHtml(i, html)
time.sleep(2)
class DownloadPage(object):
def getHtml(self, url):
html = requests.get(url=url).content
return html
def saveHtml(self, file_name, file_content):
with open('html_page/' + file_name + '.html', 'wb') as f:
f.write(file_content)
防止访问限制,每次请求都做了2秒的等待
但是,问题来了
当我直接请求这个页面的时候,竟然是这样的
被(悲)拒(剧)了
没办法,继续斗争。重新分析,发现请求中有携带一个 cookie,哈哈,这个我们已经轻车熟路啦
对 requests 请求增加 cookie,同时再把 headers 里面增加个 User-Agent,再试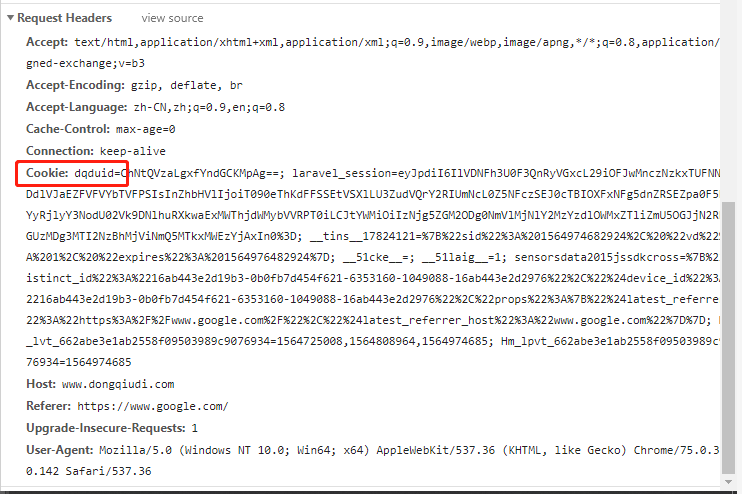
成了!
解析本地 HTML
最后,就是解析下载到本地的 HTML 页面了,页面的规则就是,本期女神介绍页面,会公布上期女神的综合得分,而我们的主要任务就是获取各个女神的得分
def deal_loaclfile(nvshen_id_picture):
files = os.listdir('html_page/')
nvshen_list = []
special_page = []
for f in files:
if f[-4:] == 'html' and not f.startswith('~'):
htmlfile = open('html_page/' + f, 'r', encoding='utf-8').read()
content = BeautifulSoup(htmlfile, 'html.parser')
try:
tmp_list = []
nvshen_name = content.find(text=re.compile("上一期女神"))
if nvshen_name is None:
continue
nvshen_name_new = re.findall(r"女神(.+?),", nvshen_name)
nvshen_count = re.findall(r"超过(.+?)人", nvshen_name)
tmp_list.append(''.join(nvshen_name_new))
tmp_list.append(''.join(nvshen_count))
tmp_list.append(f[:-4])
tmp_score = content.find_all('span', attrs={'style': "color:#ff0000"})
tmp_score = list(filter(None, [k.string for k in tmp_score]))
if '.' in tmp_score[0]:
if len(tmp_score[0]) > 3:
tmp_list.append(''.join(list(filter(str.isdigit, tmp_score[0].strip()))))
nvshen_list = nvshen_list + get_picture(content, tmp_list, nvshen_id_picture)
else:
tmp_list.append(tmp_score[0])
nvshen_list = nvshen_list + get_picture(content, tmp_list, nvshen_id_picture)
elif len(tmp_score) > 1:
if '.' in tmp_score[1]:
if len(tmp_score[1]) > 3:
tmp_list.append(''.join(list(filter(str.isdigit, tmp_score[1].strip()))))
nvshen_list = nvshen_list + get_picture(content, tmp_list, nvshen_id_picture)
else:
tmp_list.append(tmp_score[1])
nvshen_list = nvshen_list + get_picture(content, tmp_list, nvshen_id_picture)
else:
special_page.append(f)
print("拿不到score的HTML:", f)
else:
special_page.append(f)
print("拿不到score的HTML:", f)
except:
print("解析出错的HTML:", f)
raise
return nvshen_list, special_page
def get_picture(c, t_list, n_id_p):
print("进入get_picture函数:")
nvshen_l = []
tmp_prev_id = c.find_all('a', attrs={"target": "_self"})
for j in tmp_prev_id:
if '期' in j.string:
href_list = j['href'].split('/')
tmp_id = re.findall(r"\d+\.?\d*", href_list[-1])
if len(tmp_id) == 1:
prev_nvshen_id = tmp_id[0]
t_list.append(prev_nvshen_id)
for n in n_id_p:
for k, v in n.items():
if k == prev_nvshen_id:
t_list.append(v)
print("t_list", t_list)
nvshen_l.append(t_list)
print("get_picture函数结束")
return nvshen_l
保存数据
对于我们最后解析出来的数据,我们直接保存到 csv 文件中,如果数据量比较大的话,还可以考虑保存到 mongodb 中。
def save_to_file(nvshen_list, filename):
with open(filename + '.csv', 'w', encoding='utf-8') as output:
output.write('name,count,score,weight_score,page_id,picture\n')
for row in nvshen_list:
try:
weight = int(''.join(list(filter(str.isdigit, row[1])))) / 1000
weight_2 = float(row[2]) + float('%.2f' % weight)
weight_score = float('%.2f' % weight_2)
rowcsv = '{},{},{},{},{},{}'.format(row[0], row[1], row[3], weight_score, row[4], row[5])
output.write(rowcsv)
output.write('\n')
except:
raise
对于女神的得分,又根据打分的人数,做了个加权分数
保存图片
def save_pic(url, nick_name):
resp = requests.get(url)
if not os.path.exists('picture'):
os.mkdir('picture')
if resp.status_code == 200:
with open('picture' + f'/{nick_name}.jpg', 'wb') as f:
f.write(resp.content)
直接从拿到的 thumb 地址中下载图片,并保存到本地。
做一些图
首先我们先做一个柱状图,看看排名前10和倒数前10的情况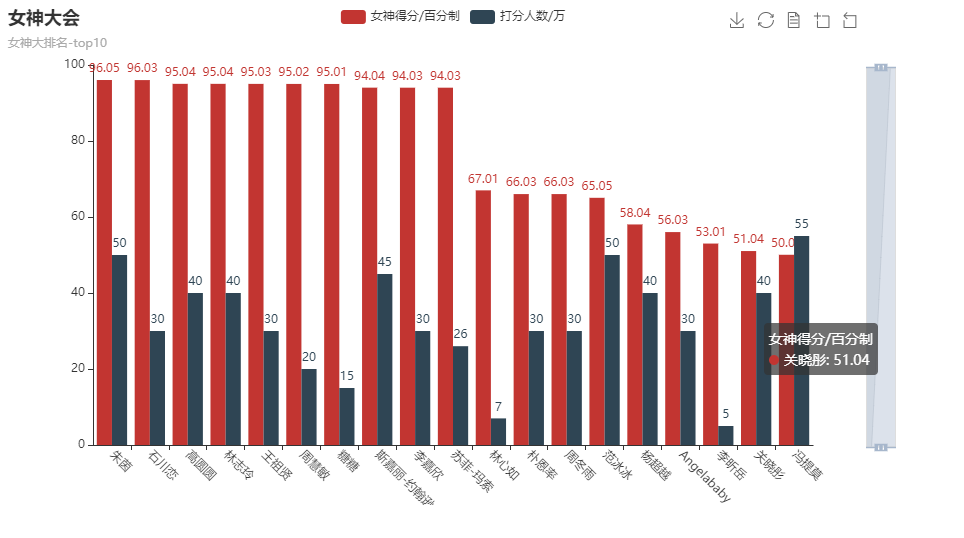
看一看到,朱茵、石川恋和高圆圆位列三甲,而得分高达95+的女神也有7位之多。那么排名后10位的呢,自行看吧,有没有人感到有点扎心呢,哈哈哈。同时,也能够从打分的人数来看出,人气高的女神,普遍得分也不低哦。
不过,该排名目前只代表球迷心目中的榜单,不知道程序猿心中的榜单会是怎样的呢,等你来打分哦!
词云
图片墙
百度 API 评分
百度有免费的人脸检测 API,只要输入图片,就能够得到对应的人脸得分,还是非常方便的,感兴趣的小伙伴可以去官网看看哦。
我这里直接给出了我通过百度 API 得出的女神新得分,一起来看看吧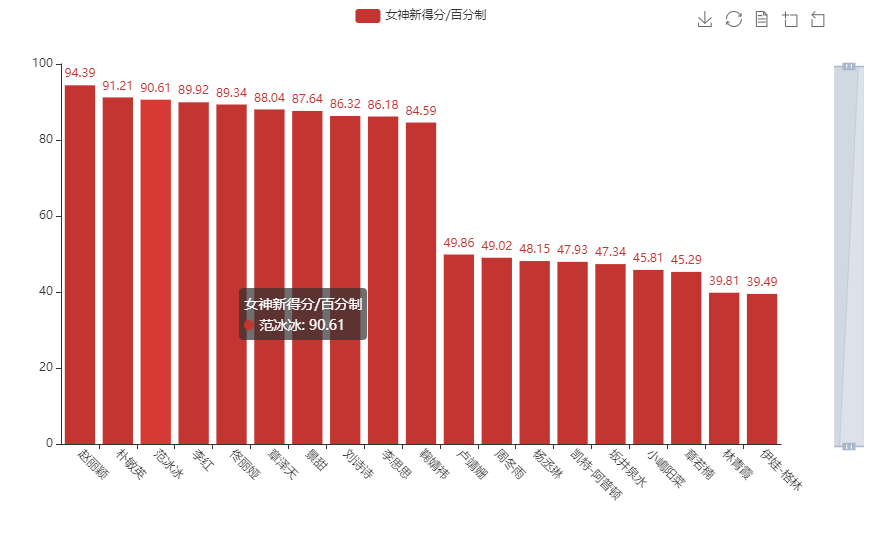
哈哈哈哈,AI 的评分,对于图片的依赖太高,纯属娱乐。
制作网站
网站的制作,直接使用 flask 来快速搭建,美美哒!
定义数据
首先我们先定义下数据,主要也就三张表
drop table if exists nvshen;
create table nvshen (
id integer primary key autoincrement,
name string not null,
nvshen_id string not null
);
drop table if exists picture;
create table picture (
id integer primary key autoincrement,
nvshen_id string not null,
pic_url string not null
);
drop table if exists score;
create table score (
id integer primary key autoincrement,
nvshen_id string not null,
score string not null,
userip string not null
);
分别存储女神 ID,女神图片 ID 和广大朋友的打分数据
数据库操作
我这里使用的是 sqlite3 数据库
先定义数据库的连接等操作
def connect_db():
"""Connects to the specific database."""
rv = sqlite3.connect(app.config['SQLALCHEMY_DATABASE_URI'])
rv.row_factory = sqlite3.Row
return rv
def get_db():
"""Opens a new database connection if there is none yet for the
current application context.
"""
if not hasattr(g, 'sqlite_db'):
g.sqlite_db = connect_db()
return g.sqlite_db
@app.teardown_appcontext
def close_db(error):
"""Closes the database again at the end of the request."""
if hasattr(g, 'sqlite_db'):
g.sqlite_db.close()
然后开始定义数据库初始化信息
def init_db():
with app.app_context():
db = get_db()
with app.open_resource('schema.sql', mode='r') as f:
db.cursor().executescript(f.read())
db.commit()
# @app.route('/init')
def init():
init_db()
return "OK"
# @app.route('/insert')
def insert():
db = get_db()
nvshen_list = deal_data()
print(nvshen_list)
for nvshen in nvshen_list:
db.execute('insert into nvshen (name, nvshen_id) values (?, ?)', [nvshen[0], nvshen[1]])
db.commit()
return "OK"
# @app.route('/insert_pic')
def insert_pic():
db = get_db()
cur = db.execute('select name, nvshen_id from nvshen order by id desc')
nvshen = [dict(name=row[0], nvshen_id=row[1]) for row in cur.fetchall()]
nopic = app.config['NO_PIC']
for n in nvshen:
url_list = deal_html(str(n['nvshen_id']) + ".html", nopic)
# print(url_list)
for url in url_list:
db.execute('insert into picture (nvshen_id, pic_url) values (?, ?)', [n['nvshen_id'], url])
db.commit()
return "OK"
这样,当我们启动 flask 进程后,在浏览器中输入对应的地址,我们准备好的数据就存储到数据库了。
逻辑操作
首先定义两个视图函数
@app.route('/', methods=['GET', 'POST'])
def index():
db = get_db()
cur = db.execute('select name, nvshen_id from nvshen order by id desc')
nvshen = [dict(name=row[0], nvshen_id=row[1]) for row in cur.fetchall()]
data = []
socre = 1
for n in nvshen:
tmp_data = []
pic = db.execute('select pic_url from picture where nvshen_id = (?)', [n['nvshen_id']])
pic_list = [row[0] for row in pic.fetchall()]
pic_url = random.choice(pic_list)
tmp_data.append(n['name'])
tmp_data.append(pic_url)
tmp_data.append(n['nvshen_id'])
data.append(tmp_data)
return render_template('index.html', data=data, score=socre)
@app.route('/nvshen/<id>/', methods=['GET', 'POST'])
def nvshen(id):
db = get_db()
user_ip = request.remote_addr
user_score = db.execute('select score from score where nvshen_id = (?) and userip = (?)', [id, user_ip]).fetchone()
pic = db.execute('select pic_url from picture where nvshen_id = (?)', [id])
pic_list = [row[0] for row in pic.fetchall()]
pic_url = random.choice(pic_list)
if user_score is None:
score = 0
else:
score = user_score[0]
return render_template('nvshen.html', nvshenid=id, main_url=pic_url, pic_list=pic_list, user_score=score)
index 函数,就是首页喽,随机展示每个女神的一张照片;nvshen 函数是每个女神的个人页面,会展示她们的所有照片,同时还有打分功能。
然后定义一个用于接收打分数据的 API
@app.route('/api/score/', methods=['POST'])
def set_score():
db = get_db()
data = request.get_data().decode('utf-8')
data_dict = json.loads(data)
setScore_ip = request.remote_addr
nvshenid = data_dict['nvshenid']
score = data_dict['score']
checkpoint = db.execute('select id from score where nvshen_id = (?) and userip = (?)', [nvshenid, setScore_ip]).fetchone()
if checkpoint is None:
db.execute('insert into score (nvshen_id, score, userip) values (?, ?, ?)', [nvshenid, score, setScore_ip])
else:
db.execute('update score set score = (?) where id = (?)', [score, checkpoint[0]])
db.commit()
return jsonify({"msg": "OK", "code": 200})
从前端 Ajax 中获取到数据,然后保存到数据库中。
前端代码
前端就是两个 html 就搞定了,一个首页,一个女神个人页面
这里因为代码较长,就不贴完整的代码了
先来看看 index.html 的关键代码
<section id="gallery-wrapper">
{% for p in data %}
<article class="white-panel">
<img src="{{ p[1] }}" class="thumb">
<h1><a href="{{ url_for('nvshen', id=p[2]) }}" title="去投票" target="_blank">{{ p[0] }}</a>
</h1>
<p>
<div id="starBg" class="stars-bg">
{% if score == 1 %}
<a href="#" class="star-active" style="width: 20%"></a>
{% elif score == 2 %}
<a href="#" class="star-active" style="width: 40%"></a>
{% elif score == 3 %}
<a href="#" class="star-active" style="width: 60%"></a>
{% elif score == 4 %}
<a href="#" class="star-active" style="width: 80%"></a>
{% elif score == 5 %}
<a href="#" class="star-active" style="width: 100%"></a>
{% else %}
<a href="#" class="star-active" style="width: 0%"></a>
{% endif %}
</div>
</p>
</article>
{% endfor %}
</section>
这里是展示女神图片的部分代码
再来看看 nvshen.html 部分代码
<section style="width: 100%">
<img src="{{ main_url }}" width="40%" height="20%">
<div id="starBg" class="star_bg">
{% if user_score == 1%}}
<input type="radio" id="starScore1" class="score score_1" value="1" name="score" onclick="score()" checked>
<a href="#starScore1" class="star star_1" title="一般"><label for="starScore1">一般</label></a>
<input type="radio" id="starScore2" class="score score_2" value="2" name="score" onclick="score()">
<a href="#starScore2" class="star star_2" title="还行"><label for="starScore2">还行</label></a>
<input type="radio" id="starScore3" class="score score_3" value="3" name="score" onclick="score()">
<a href="#starScore3" class="star star_3" title="普通"><label for="starScore3">普通</label></a>
<input type="radio" id="starScore4" class="score score_4" value="4" name="score" onclick="score()">
<a href="#starScore4" class="star star_4" title="很好"><label for="starScore4">很好</label></a>
<input type="radio" id="starScore5" class="score score_5" value="5" name="score" onclick="score()">
<a href="#5" class="star star_5" title="完美"><label for="starScore5">完美</label></a>
function score() {
var checkValue = $('input:radio[name="score"]:checked').val();
var nvshen_id = {{ nvshenid }};
var formData = new FormData();
formData.append("nvshenid", nvshen_id);
formData.append("score", checkValue);
var data = {"nvshenid": nvshen_id, "score": checkValue};
console.log(data);
console.log(document.domain);
$.ajax({
method: "POST",
url: "https://"+ document.domain + ":" + location.port + "/api/score/",
timeout: 10000,
data: JSON.stringify(data),
async: false,
dataType: "json",
contentType:false,
processData:false,
success: function (res) {
return;
},
error: function (e) {
console.log(e);
alert(e.msg);
}
});
};
至此,整个项目就算完成了,快来体验下吧
女神大放送
最后献上代码
GitHub 地址:
https://github.com/zhouwei713/data_analysis/tree/master/nvshendahui
共同学习,写下你的评论
评论加载中...
作者其他优质文章



