
人脸对齐(Face Alignment)基本概念及原理
文章名称:One Millisecond Face Alignment with an Ensemble of Regression Trees
https://blog.csdn.net/App_12062011/article/details/78661992
人脸对齐中的几个关键词:
形状(shape):形状就是人脸上的有特征的位置,如下图所示,每张图中所有黄点构成的图形就是该人脸的形状。
特征点(landmark):形状由特征点组成,图中的每一个黄点就是一个特征点。
3.从“树”的概念开始
树的思想在机器学习算法中可谓是鼎鼎大名,非常常用的决策树、二叉树等,以及由树构成的随机森林等算法,都在各种领域被广泛使用,甚至延伸出了诸如“随机蕨”等类树的结构。树不仅多种多样,其应用也绝不仅仅局限于分类,例如本文就将树的思想应用在回归的领域,而非常流行的CART分类回归树也是其中一种,甚至还有采用树的结构来提取特征的方法(3000FPS)。
如果大家理解随机森林,那么对本文的GBDT可能会更好理解一点。简单来说随机森林就是将很多棵决策树联合在一起,其中每一棵树的训练采用的是随机数量的样本和随机的特征,其实也是集成学习的思想的表现之一。
而本文的GBDT,相比与随机森林,其实本质上差别不是很大,主要差别在于:
1)每一棵树之间的关系是串行的,并非是并行的关系,也就是说后一棵树的建立在前一棵树的基础之上。
2)每一棵树的叶子节点上存的是残差,这也是GBDT的特点之一,也只有通过叶子节点上保存的残差,才能使形状不断地回归,从而回归到真实形状。
下面直接介绍这种方法。
4.人脸对齐中的一棵GBDT
假设我要开始构建一棵GBDT,注意,这里的一棵GBDT的概念不是指一棵树,而是指很多棵树,很多棵树构成一个GBDT,所以说GBDT的地位类似与随机森林,都是由树集成构成的。
构建一棵GBDT要实现的目的是:通过这棵树,将人脸的初始形状回归到其真实形状上去(这是测试时的目的,训练时,也就是构建树时我们是知道其真实形状的,那么目的自然就是用GBDT来表示初始形状和真实形状的关系)。
假设我们一共有N幅图像,将它们作为训练样本,我们知道这N幅图像的每一个真实形状。首先我们要获得一个回归的初始形状,假设我们用所有图像的平均形状来作为这个初始形状(初始形状就是回归的起点,之后在测试时无论给出怎样一幅图像,我们都通过这个初始形状来进行预测和回归)。在原论文中,在训练时,作者并非只使用了初始形状,而是随机挑选另一个真实形状来作为某一幅图像的初始形状,这种做法我们先不讨论,首先讨论如何构建一棵GBDT。
现在开始构建GBDT的第一棵树。
有了初始形状,这里就会发现一个问题,假如使用平均形状来作为每一幅图像的初始形状,那么对所有图像来说,初始输入都是相同的,这如何分裂树呢?是的,对所有图像来说,初始形状相同,但我们分裂树时,采用的输入并非是当前形状,而是依据当前形状从该图片中提取出的特征。对于每一幅图像来说,初始形状虽然相同,但每一幅图片都不同,因此提取出的特征也就不同,论文中是使用的像素差作为特征,下一节会详细讲这种特征的提取方式。我们依据特征来进行节点的分裂操作,直至到达树的叶子节点。
当我们把N张图片都输入这第一棵树,自然每一张图片最终都会落入其中的一个叶子节点,比如第1张图片落入了第3个叶子节点,第2张图片落入了第1个叶子节点,第3张图片落入了第三个叶子节点等等。这样,每一个叶子节点中都会有图片落入,当然也可能没有,这无所谓。这时,我们就要计算残差,计算每一个图片的当前形状和真实形状的差值,之后,在同一个叶子节点中的所有图片的差值作平均,就是该叶子节点应当保存的残差。当所有叶子节点都保存了残差后,第一棵树也就构造完毕了。
在构造第二棵树之前,我们要把每张图片的当前形状做一个更新,也就是要将当前形状更新成:当前形状+残差。对应到第一棵树,即是初始形状加上残差,这样每一张图片的当前形状就从初始形状变成了初始形状加残差,距离真实形状又更近了一步。
之后再用同样的方法构建第二棵树,依据特征进行节点分裂,直到叶子节点。在叶子节点中计算每一张图片当前形状和真实形状的差,然后取平均,将这个平均值保存在该叶子节点中,作为残差。之后更新每一张图片的当前形状,即将叶子节点中保存的残差加上其当前形状,作为新的当前形状,然后就可以建立第三棵树了。
直至建立的树足够多,可以最后的当前形状表示真实形状,那么这一个GBDT也就建立完成了。
还有一个问题没有解决,那就是GBDT中的每一棵树是怎样分裂的,下面详细叙述分裂的方法。
5.树的接点分裂和像素差特征
对于一棵GBDT(很多棵子树构成)而言,我们要建立一个特征池,这个特征池里是我们随机挑选的一些点的坐标,然后对于每一幅图像,这些点都对应着不同的像素值,因此,在树的节点分裂时,我们首先会在这合格特征池中随机挑选两个点,然后计算每一张图片在这两个点处的像素值,然后计算每一张图片的这两个点处的像素值的像素差,之后随机产生一个分裂阈值,根据这个阈值进行判断,如果一幅图像的像素差小于这个阈值,就往左分裂,否则往右分裂,将所有图片都这样判断一次,就将所有图片分成了两部分,一部分在左,一部分在右。我们重复上面这个过程若干次,看看哪一次分裂的好(判断是否分裂的好的依据是方差,如果分在左边的样本的方差小,这说明它们是一类,分的就好),就把这个分裂的好的选择保存下来,即保存下这两个点的坐标值和分裂阈值。这样一个节点的分裂就完成了。然后每一个节点的分裂都按照这个步骤进行,直到分裂到叶子节点。
6.作者的实验结果
原论文作者一共建立了10棵GBDT,每一个GBDT中包含500棵树,10棵GBDT的意思就是,每一棵GBDT都是相互独立的,一共有10个相互独立的特征池。作者的每一个特征池中有400个点,在同一棵GBDT中,每次节点分裂,都从这400个点中挑选出20对点并随机产生20个阈值,然后进行分裂,看看哪一对点分裂的结果方差最小,就将其作为分裂的依据。
Face Alignment at 3000 FPS via Regressing Local Binary Features
https://blog.csdn.net/zhou894509/article/details/54629130
LBF(Local binary feature),基于局部二值特征的人脸特征点递给我,该算法的核心工作主要有两部分,总体上采用了随机森林和全局线性回归相结合的方法,相对于使用卷积神经的深度学习方法,LBF采用的算法是传统的机器学习方法。
LBF采用了一种局部二值特征,该特征是对12年的Face Alignment by Shape Regression(ESR)算法提到的形状索引特征的改进,从全局的索引特征升级为局部的二值索引特征,采用如下的公式表达:
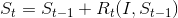
公式(1)是隐式形状中比较常见的公式,包含了很多的信息,首先认识这几个名词,在人脸特征点定位中,关键点的集合成为形状,形状包含了关键点的位置信息,而这个位置信息一般上可用两种形式表示,第一种是关键店的位置相对于整张人脸图像,第二种是关键点的位置相对于人脸框(将人脸的位置图像用人脸框标记)第一种形状称为绝对形状,他的取值一般介于0到image.size;第二种是相对形状,他的取值范围一般介于0到1。这两种形状的位置可以通过人脸框进行转换。公式(1)中的St就表示绝对形状,Rt表示形状变化量,一般采用回归器进行输出,也可以记作是回归器,I表示人脸图像,Rt需要根据图像和形状的位置信息,预测出一个形状变化,并将它加到当前形状组成一个新的形状,t表示级联回归的层数,一般我们需要通过多层级联来预测形状。
Rt介绍:
在LBF算法中,使用了较为复杂的回归子预测形状,每一个预测单元使用随机树,并且使用随机森林来预测形状变化。其次,LBF算法并没有采用随机树叶子节点的形状作为预测输出,而是将随机森林的输出组成一种特征(这里也就是LBF),并用LBF来做预测,除了采用随机森林的结构做预测,LBF还针对每个关键点给出一个随机森林来做预测,并将所有关键点对应的随机森林输出的局部特征相互联系起来,称作为局部二值特征,然后利用这个局部二值特征做全局回归,来预测形状变化量。
图1描述了回归器Rt的训练和预测过程。其中 表示在第t次级联回归中,第l个特征点所对应的随机森林,所有的关键点的随机森林一起组成了
表示在第t次级联回归中,第l个特征点所对应的随机森林,所有的关键点的随机森林一起组成了 ,它的输出为LBF特征。然后利用LBF特征来训练全局线性回归或者预测形状变化量。
,它的输出为LBF特征。然后利用LBF特征来训练全局线性回归或者预测形状变化量。
图2描述了回归器Rt生成局部二值特征LBF的过程,图的下半部分描述了单个关键点上随机森林输出了一个局部二值特征,然后把所有随机森林的输出前后连接起来组成一个非常大单又十分稀疏的LBF特征。第一颗树遍历后来到了最左边的叶子节点所以记为[1,0,0,0],对于第一课树访问到的叶子节点记为1,其他的记为0,然后一个landmark拥有一个forest即是多颗树,那么把所有的结果串联起来就是=[1,0,0,0,0,1,0,0,0,0,1,0.....],其中这个特征只有01组成,且大部分是0,特征非常的稀疏。真正的局部 二值特征就是将所有的landmark的特征串联起来,即是

形状索引特征(shape-indexed)
每一个关键点对应一个随机森林,而随机森林是有多个想回独立的随机树组成。论文中的随机树采用的特征是shape-indexed特征,ESR(CVPR‘12)和RCPR(ICCV'13)也是采用了类似的特征,这个特征主要是描述人脸区域中两个点的像素差值。关于两个像素点的选取,三个方法都使用了不同的策略。
ESR方法采用的是在两个关键点附近随机出两个点,做这两个点之间的差值作为形状索引特征。
RCPR方法采用的选取两个关键点的中点,外加一个随机偏置来生成特征点,用两个这样的特征点的差值作为形状索引特征。
在LBF算法中,由于随机森林是针对单个关键点的,所有随机树种使用到的特征点不会关联到其他关键点,只有在当前关键点的附近区域随机产生两个特征点,做像素差值来作为形状索引特征。图5是每个特征点的局部区域面积变化,索引面积从大到小逐渐变小,目的是为了获得更加准确的局部索引特征。
随机树的训练
每个随机树的训练需要用到形状索引特征,在训练随机树时,我们的输入是X={I,S},而预测回归的目标是Y= ΔS。在实际的训练随机树时,树中的每个节点的训练过程都是一样的。我们在训练某个节点时,从事先随机生成的Shape-indexed特征集合F中选取一个(也可以临时随机生成一个特征集合,或者是整棵随机树使用一个特征集合或整个随机森林使用一个特征结合,此时假设这棵随机树使用一个特征集合),选取的特征能够将所有样本点X映射成一个实数集合,我们在随机一个阈值将样本点分配到左右子树中,而分配的目的是希望左右子树的样本点的Y具有相同的模式。论文实现中,特征选取可以采用如下的方式进行。


上式中f表示选取到的特征函数(即利用随机到的特征点计算Shape-indexed特征), Δ表示随机生成的阈值,S用来刻画样本点之间的相似度或者样本集合的熵(论文中,采用的是方差)。针对每一个几点,训练数据(X,Y)被分成两部分,(X1,Y1)和(X2,Y2),我们期望左右字数的样本数据具有相同的模式,论文中采用了方差刻画,所以选择特征函数f时,我们希望方差减小最大。
随机树的每个节点都采用这种方法训练,而每一颗随机树是相对独立训练的,训练过程是一样的,这样单个关键点的随机森林就训练完毕了。
随机森林的构造和训练过程下面在做介绍,这里先谈些如何试下随机森林的加速训练。随机森林中的每棵树都是相互独立的,而每个关键点对应的随机森林也是相互独立的,这样,就可以并行训练随机树。考虑到并行计算的编码问题,并不需要多线程并发的方式来实现并行计算,这里使用OpenMp实现并行计算,OpenMP会将我们的代码通过自定义的语法将其并行化,底层用的是系统级线程的实现方式,现在的编译器已经都内置了对OpenMP的支持,但是它简单易学,使用非常方便。OpenMP用于共享内存并行系统的多处理器程序设计的一套指导性的编译处理方案,可能在线程切换方面比直接使用系统线程库来的高效,但是对于编码而言却是非常简单,几条语句就可以将原本串行的代码变成并行,修改代码的代价也是相对较低。
关于形状的初始值S0
在上面的形状变化量ΔS的求解中,没有说明是绝对形状增量还是相对形状的增量。在实际情况中,本文需要的是相对形状的增量,因为绝对形状的位置是相对于整个图像的,我们无法对数据的绝对形变做约束。在提取局部二值特征时,需要绝对形状下的图像的像素信息,而在预测得到的则是相对形状增量,这两者通过人脸框做想回之间的转化。
所有形状变化量ΔS均是相对于当前形状而言,通过级联的方式叠加到一起,而初始化形状S0与模型预测无关,但是这个S0在模型预测过程中起到关键性的作用。我们假设预测样本理论上的真实形状为Sg,那么初始形状S0和真实形状Sg两者之间的差异直接影响预测结果的准确性,LBF算法采用在训练样本中随机选择其他形状的真实值作为训练的初始值,初始值选取的方法和ESR的方法一样,测试形状的初始值采用训练形状的平均值。
一般来说,S0是相对形状通过人脸框转变为绝对形状对应到当前的人脸中,那么人脸框的尺度对S0与Sg之间的差异也起到了决定性的作用,所以一般都需要使用相同的人脸检测方法来标记训练图像和预测图像上的人脸框,保证两者的人脸框尺度,从而提高S0的准确性。但是算法本身仍然受到S0很大的影响。包括ESR和RCPR方法同样受制于S0。相比较而言,深度学习方法则没有太大的影响,一般可以先通过网络预测得到S0,这时S0和Sg之间的误差能够做到非常小,进而再在S0的基础上做细微的修正,提高回归的精度,深度卷积神经网络预测关键点就是采用了这个思路。虽然深度学习方法能够摆脱S0的限制,但是仍然受制于人脸框的尺度,而且尺度对模型的预测影响比其他传统方法也好不到哪去,而且,深度学习方法运算时间开销远大于传统的方法。
构建随机森林
随机森林有很多tree组成,相比于单棵tree能够防止模型的过拟合,随机森林能够用到回归和分类。那么如何建立随机森林,主要是如何选择分裂节点,下面以如何构建回归树为例。
(1)首先确定一个特征点landmark I,随机产生在I附近的500个像素差的位置,然后对训练中的所有图像抽取这500个特征。
(2)确定要构建I的是第几棵树(其它树一样,只是训练数据不一样)
(3)从根节点开始,构建随机树var=训练图像第I个特征点的方差
var_red = infinity,fea = -1,left_child=NULL,right=NULL
for each fature f:
threshold(阈值)= random choose from all images's feature f //比如现在所有图的f值可能是2,2,2,4,5,3(假设5张图),那么随机选择threshold可能是3
Tem_left_child = images with f<threshold//左子节点为所有f小于threshold的图片
Tem_right_child = images with f>= threshold //右子节点为所有f小鱼threshold的图片
Tmp_var_red =
var-|left_child|/root|*var_tmp_left_child-|right_child|/|root|*var_tmp_right_child//var_tmp_left_child是左子节点landmark I 的方差
if(Tmp_var_red>var_red){
var_red = tp_var_red
fea = f
left_child = tmp_left_child
right_child = tmp_right_child
}
End for
实际上,var是固定的不用算,|left_child|是当前left_child所包含的图片数量,|root|是root包含的图片数,实际上计算的时候,可以省去,因为是固定的,fea就是最后选择的feature。
(4)对于子节点left_child和right_child做的步骤是和步骤(3)一样的操作,直到达到树的最大深度,或者对于某一个根节点根据maxmum variance reduction找到的feature是恰好一个child包含了所有的图,而另一个child没有图(事实上不太可能出现),所以训练的时候基本上能够找到最大深度。
(5)landmark上的其它树也一样如上,对其它landmark和对I的操作一样。
全局线性回归训练
在LBF算法中,我们可以在随机树的叶子节点上存储预测的形变,测试时可以将随机森林中每棵随机树的预测输出做平均或者加权平均,然而LBF算法并没有这么做,它将随机树的输出表示成一个二值特征,将所有随机树的二值特征前后组合串联起来构成一个二值LBF特征。然后利用这个特征做了一次全局线性回归,将形状变化量作为预测目标,训练一个线性回归器进行预测。

上面的公式中,ΔS是形变目标,φ表示二值特征,W是线性回归的参数,λ是模型的参数,防止在训练过程中出现过拟合,预测采用下面的公式

在LBF算法中,多级级联回归的方法的每一级都可以采用上述的方法拆分成两部分,首先利用随机森林提取局部二值特征,然后再利用局部二值特征做全局线性回归预测形状增加量ΔS。
对每一个特征点的ΔS坐标进行回归,输入就是图片的局部二值特征矩阵,所有ΔS坐标组成的向量作为回归的目标,最后得到权重向量W,然后有了新的图片抽取的局部二值特征,乘以W就可以得到预测的ΔS值,最后加到上一个级联回归的S上,得到新的形状S。上面的公式是将所有特征点的W集合到一起了,求得到一个整体的W。
训练完随机森林后,我们能够得到训练数据的LBF特征,根据这个LBF特征在加上相对形状增量这个预测目标,我们便可以训练全局线性回归模型了。由于大量的训练数据,再加上LBF特征的高度稀疏,论文中提到了使用双坐标下降的方法来训练高度稀疏的线性模型,还好发明这个算法的人专门写了一套求解线性模型的库,并开源在githup上,项目名称是liblinear。这个库采用了C++编写,也提供了对许多语言的绑定,根据相关文档准备好相应的数据,直接调用就可求解到模型参数,使用起来很方便。
注:人脸特征点定位的坐标变换:
在特征点定位中,需要对landmarks进行similarity transformation,该方法主要消除面内旋转对于级联回归配准方法造成的干扰,坐标变换是如何消除干扰呢?
一般地,级联形状回归模型的基本形式如下,

 表示第t个stage的残差,W是线性回归矩阵,
表示第t个stage的残差,W是线性回归矩阵, 表示特征提取算法。在模型的训练中,我们需要根据残差和特征提取算法,利用最小二乘或其他回归算法,优化回归矩阵,为了减小回归误差,一个基本原则是,相似的特征对应相似的残差,无论是模型的训练还是在测试中,都要遵循这个原则。
表示特征提取算法。在模型的训练中,我们需要根据残差和特征提取算法,利用最小二乘或其他回归算法,优化回归矩阵,为了减小回归误差,一个基本原则是,相似的特征对应相似的残差,无论是模型的训练还是在测试中,都要遵循这个原则。
在给定当前stage的形状 和
和 之后,使用提取对应的特征,SIFT,hog或者LBP特征,由于图7左右两图的形状和相对人脸的位置是一样的,因此,提取的特征,在某种程度上,也是相似的(SIFT相似度较高,hog和lbp相对弱),但是和却有着明显的差异。
之后,使用提取对应的特征,SIFT,hog或者LBP特征,由于图7左右两图的形状和相对人脸的位置是一样的,因此,提取的特征,在某种程度上,也是相似的(SIFT相似度较高,hog和lbp相对弱),但是和却有着明显的差异。

 (9)
(9)
有公式(9)进一步得到和之间关系
(10)
由旋转R,缩放c得到。
同时在定义一个处于图像坐标中的平均形状,如图7左上角所示,再对形状、和,去中心化(以边框中心化)后表示为,和,求的如下变换,
(11)
有公式(9)得到,根据公式(11)得到,代入公式(10),得到。
(12)
根据公式(12),得到c1,,R1和c2,R2后,可以分别对和进行坐标变换,使得变换后的残差,在数值上基本相等,便满足了人脸特征点定位的而基本准则,相似的特征对应相似的残差。
在级联回归训练过程中的每个stage,都需要对变换的参数进行估计,并应用于当前stage的残差分量上,对其进行坐标系变换。在测试过程中,同样的需要对坐标进行变换。具体地,使用前一个stage所估计的shape与平均shape求得的公式(4)对应的变换参数,然后对线性回归计算出的残差进行反变换并叠加到前一个stage所估计的人脸关键点位置上,得到当前stage新的人脸关键点位置。
随机森林的原理简要介绍:
随机森林,指的是用多颗树对样本进行训练并预测的一种分类器,该分类器最早由Leo Breiman和Adele Cutler提出,并被注册了商标。简单的说,随机森林是有多颗CART(classification and regression tree)构成的。对于每棵树,它们使用的巡逻机是从总的训练集中有放回采样出来的,这意味着,总的训练集中的有些样本可能多次出现在一棵树的训练中,也可能从未出现在一棵树的训练集中。在训练每棵树的节点时,使用的特征是从所有特征中按照一定比例随机的无放回的抽取的,根据大牛们建议,假设总的特征数量为M,这个比例可以是sqrt(M),1/2*sqrt(M)或者是2*sqrt(M)。
因此,随机森林的训练过程总结如下:
(1)给定训练集S,测试集T,特征维数F,确定参数:使用到的CART的数量t,每棵树的深度t,每个节点使用到的特征数量f,终止条件:节点上最少样本数s,节点上最少的信息增益m
对于第i棵树,i=1-t
(2)从S中有放回的抽取大小和S一样的训练集s(i),作为根节点的样本,从根节点开始训练。
(3)如果当前节点上达到终止条件,则设置当前节点为叶子节点,如果是分类问题,则叶子节点的预测输出为当前节点样本集合中数量最多的那一类c(j),概率p为c(j)占当前样本集的比例:如果是回归问题,预测输出为当前节点没有达到终止条件,则从F维特征中无放回的随机选取f维特征。利用f维特征,寻找分类效果最好的一维特征k及其阈值th,当前节点上样本第k维特征小于th的样本被划分到左节点,其余被划分到右节点,继续训练其他节点
(4)重复(2)和(3)知道所有节点都被训练过了或者被标记为叶子节点
(5)重复(2)(3)(4)直到所有CAST都被训练过
随机森林的预测过程如下:
对于第i棵树,i=1-t
(1)从当前树的根节点开始,根据当前节点的阈值th,判断是进入左节点(<th)还是进入右节点(>=th),直到到达某个叶子节点,并输出预测值。
(2)重复执行(1)直到所有t棵树都输出了预测值。如果是分类问题,则输出为所有树中预测概率和最大的那一类,即对每个c(j)的概率p进行累计;如果是回归问题,则输出为所有书的输出的平均值。
注:对于分类问题(将某个样本划分到某一类),也就是离散变量问题,CAST使用的是Gini值作为判断标准,定义为Gini=1-∑(p(i)*p(i)),其中p(i)为当前节点上数据集中第i类样本的比例。例如:分为2类,当前节点上有100个样本,属于第一类的样本有70个,属于第二类的样本有30个,则Gini=1-0.7*0.7-0.3*0.3=0.42,可以看出,类别分布越平均Giniz值越大,类别分布越不均匀,Gini值越小。在寻找最佳分类特征和阈值时,评判标准是:
argmax(Gini - GiniLeft - Giniright)
寻找最佳的特征f和阈值th,使得当前节点的Gini值减去左子节点额Gini和右子节点的Gini值最大。
对于回归问题,直接使用
argmax(Var - VarLeft - VarRight)
作为评判标准,即当前节点训练集的方差Var减去左子节点的方差VarLeft和右子节点的方差VarRight值最大。
LBF算法数据预处理的一些技巧:
LBF算法数据处理时,需要使用人脸检测找到人脸的位置,人脸框的尺度对S0有影响,需要在寻找和测试过程中使用相同的人脸检查器来标识人脸框,尝试用的是OpenCV或者libfacedetection算法。在训练过程中,可能出现爆内存的状况,大致是将全部图像载入到内存后做了一些处理。导致内存飙升而崩溃。其实考虑图像,并不需要整幅图像作为训练数据,只需要重新计算关键点位置即可,因为数据集中的图片都是高清无码大图,人脸只占有内存的一块,这种方法能够减少非常多的内存消耗。
数据扩大时在现有数据集不足的情况下,通过变换已有的数据来增加数据集的大小,可谓是一种既经济又环保的方法。根据不同的数据和模型,可以采用不同的交换手段,如果目标具有对称不变性,那么水平翻转图像是中不错的手段,常见的还有旋转图像来增加数据集。针对人脸关键点定位,显然左右翻转人脸不会影响人脸的结构,包括轻微旋转人脸也同样能够增加训练数据集。在训练过程中,需要给每个训练样本一个初始形状,这个初始形状可以从样本中随机选取,通过选取多个初始形状,同样可以达到增加数据集的效果。
LBF算法的基本参数设置:
>>params.local_features_num_ //每个特征点局部特征采样点数量
>>params.landmarks_num_per_face_ //人脸形状的数量
>>params.regressor_stages_//层次级联回归的次数
>>params.tree_depth_//决策树的深度
>>params.trees_num_per_forest_//每个随机森林的树木数量
>>params.initial_guess_//训练时,每个形状的初始采样点数量
>>params.overlap_//训练样本的重叠率
>>params.loca_radius_by_stage//特征点采样的局部半径,因为级联回归是从粗到细的,所以半径是依次从大到小渐变的,需要根据经验不断的调整。以上8个组参数是LBF算法的主要参数,其中params.trees_num_per_forest_对训练模型影响特别大,树的数量较多时,模型会翻倍的增长,而且运行速度翻倍的减少。params.regressor_stages_级联回归的次数,一般是5-7次,基本上能够达到收敛,params.tree_depth_树的深度一般设置为5-7,深度过深容易造成过拟合,而且也会影响算法的运行速度,深度也不能太浅,否则不容易收敛。
后记:
为了实现可靠的特征点检测,需要对拟合函数估计的特征点位置进行置信度评估,并据此判断是否成功检测到特征点。为此,首先在人脸图像的特定区域随机选择k个采样点,并随机选择每个点的尺度和方向。然后根据拟合函数R对所有采样点进行姿态偏差估计,得到k个目标特征点的候选位置。最后对候选位置的分布情况进行分析。可以预见如果目标特征点在人脸图像中可见,则K个估计位置应该分布在真实特征点的周围,并且分布比较集中。而当特征点不可见时,估计的位置则可能呈现一种较为分散的情况。于是候选位置的分布情况可以作为评估置信度的指标,同时通过对多次评估的位置进行融合,可以进一步提高估计位置的精度。
基于上述假设,采用mean-shift算法对k个估计位置的分布中心进行评估,设估计的中心位置为xc‘取与xc距离最近的M个特征点计算方差为δc。给定一个阈值Θt,如果小于Θt,则认为特征点被检测到,并且特征点的位置设定为xc。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



