
一.用字典映射代替switch-case语句
字典中的key,对应于switch-case语句中的case,可避免用if-else
switch-case结构:
switch (day):
case 0:
dayName = “Sunday”;
break;
case 1:
dayName = “Monday”;
break;
case 2:
dayName = “Tuesday”;
break;
…
default :
dayName = “Unknown”;
break;
字典实现:
day = 0
switcher = {
0:'Sunday',
1:'Monday',
2:'Tuesday'
}
day_name = switcher[day]
print(day_name)
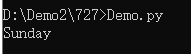
模仿switch-case处理default情况,用字典的get方法
day = 6
switcher = {
0:'Sunday',
1:'Monday',
2:'Tuesday'
}
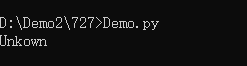
day_name = switcher.get(day,'Unkown')
#后面的'Unkown'是返回值
print(day_name)
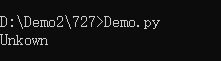
字典中,Key对应的value不仅可以用字符串,还可以用函数,比如lambda表达式
模仿switch-case处理default情况,用字典的get方法
day = 0
def get_sunday():
return 'Sunday'
def get_monday():
return 'Monday'
def get_tuesday():
return 'Tuesday'
switcher = {
0:get_sunday,
1:get_monday,
2:get_tuesday
}
day_name = switcher.get(day,'Unkown')()
#因为返回的是函数,所以get()后面还要再加一个()
print(day_name)
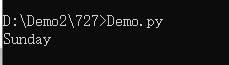
玩一下递归,嘿嘿
day = 0
def get_sunday():
print ('Sunday')
return get_sunday
def get_monday():
return get_monday
def get_tuesday():
return get_tuesday
switcher = {
0:get_sunday(),
1:get_monday(),
2:get_tuesday()
}
day_name = switcher.get(day,'Unkown')()
print(day_name)
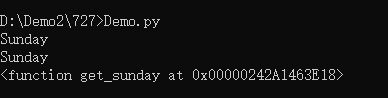
day = 0
def get_sunday():
return get_sunday
def get_monday():
return get_monday
def get_tuesday():
return get_tuesday
switcher = {
0:get_sunday(),
1:get_monday(),
2:get_tuesday()
}
day_name = switcher.get(day,'Unkown')()
print(day_name)

上面的结构不能处理Default情况,优化一下
day = 6
def get_sunday():
return 'Sunday'
def get_monday():
return 'Monday'
def get_tuesday():
return 'Tuesday'
#处理default情况
def get_default():
return 'Unkown'
switcher = {
0:get_sunday,
1:get_monday,
2:get_tuesday
}
day_name = switcher.get(day,get_default)()
#因为返回的是函数,所以get()后面还要再加一个()
print(day_name)
二.列表推导式,除了map和for循环以外的第三种遍历方法
例如:求一个列表的平方
a = [1,2,3,4,5,6,7,8]
b = [ii for i in a]
增加一个条件判断,只对大于5的数进行平方
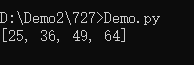
a = [1,2,3,4,5,6,7,8]
b = [ii for i in a if i >= 5]
print(b)
Set,字典也可以用这种方式
a = {1,2,3,4,5,6,7,8}
b = {i*i for i in a if i >= 5}
print(b)
字典的列表推导式
students = {
'Tim':18,
'Quene':20,
'Allen':15
}
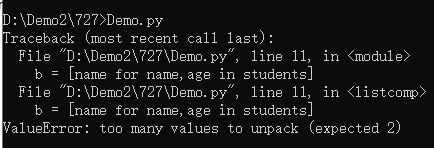
#name对应key,age对应value
#for 前面放name,只返回name
b = [name for name,age in students]
print(b)
students = {
'Tim':18,
'Quene':20,
'Allen':15
}
#name对应key,age对应value
#for 前面放name,只返回name
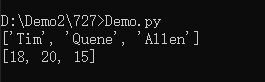
b = [name for name,age in students.items()]
print(b)
b = [age for name,age in students.items()]
print(b)
students = {
'Tim':18,
'Quene':20,
'Allen':15
}
#name对应key,age对应value
#for 前面放name,只返回name
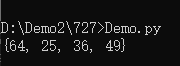
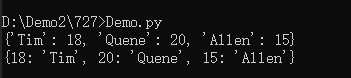
b = {name:age for name,age in students.items()}
print(b)
b = {age:name for name,age in students.items()}
print(b)
三.可迭代对象&迭代器
可迭代对象:可以被for in循环遍历的数据结构都是可迭代对象,比如元组,列表,集合。
迭代器:是一个对象,class
设计一个迭代器:
自定义class,作为迭代器,用来for-in遍历
要求:
1.实现内置函数__iter__()
2.实现内置函数__next__()
例如
class BookCollection:
def __init__(self):
pass
def __iter__(self):
pass
def __next__(self):
pass
运行一个Demo试试
class BookCollection:
def __init__(self):
self.data = ['《童年》','《在人间》','《我的大学》']
pass
def __iter__(self):
pass
def __next__(self):
pass
books = BookCollection()
for book in books:
print(book)
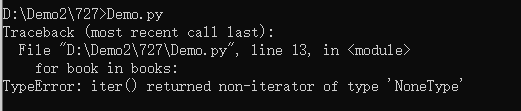
普通的class没法用for-in遍历
for-int遍历的实质:每运行一次,就调用一次next()方法
优化后:
class BookCollection:
def __init__(self):
self.data = ['《童年》','《在人间》','《我的大学》']
#记录遍历的序号
self.sequence = 0
pass
def __iter__(self):
return self
def __next__(self):
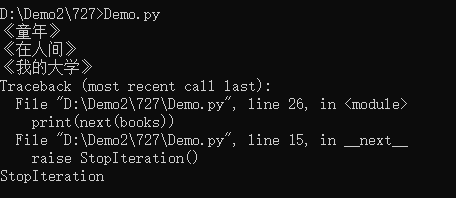
if self.sequence >= len(self.data):
#遍历超出范围时,返回一个异常
raise StopIteration()
r = self.data[self.sequence]
self.sequence += 1
return r
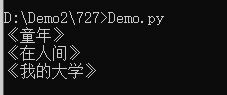
books = BookCollection()
for book in books:
print(book)
class BookCollection:
def __init__(self):
self.data = ['《童年》','《在人间》','《我的大学》']
#记录遍历的序号
self.sequence = 0
pass
def __iter__(self):
return self
def __next__(self):
if self.sequence >= len(self.data):
#遍历超出范围时,返回一个异常
raise StopIteration()
r = self.data[self.sequence]
self.sequence += 1
return r
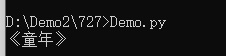
books = BookCollection()
#不用for-in,用next方法
print(next(books))
class BookCollection:
def __init__(self):
self.data = ['《童年》','《在人间》','《我的大学》']
#记录遍历的序号
self.sequence = 0
pass
def __iter__(self):
return self
def __next__(self):
if self.sequence >= len(self.data):
#遍历超出范围时,返回一个异常
raise StopIteration()
r = self.data[self.sequence]
self.sequence += 1
return r
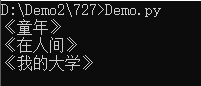
books = BookCollection()
#不用for-in,用next方法
print(next(books))
print(next(books))
print(next(books))
class BookCollection:
def __init__(self):
self.data = ['《童年》','《在人间》','《我的大学》']
#记录遍历的序号
self.sequence = 0
pass
def __iter__(self):
return self
def __next__(self):
if self.sequence >= len(self.data):
#遍历超出范围时,返回一个异常
raise StopIteration()
r = self.data[self.sequence]
self.sequence += 1
return r
books = BookCollection()
#不用for-in,用next方法
print(next(books))
print(next(books))
print(next(books))
print(next(books))
迭代器具有一次性,只能被遍历一次 :
class BookCollection:
def __init__(self):
self.data = ['《童年》','《在人间》','《我的大学》']
#记录遍历的序号
self.sequence = 0
pass
def __iter__(self):
return self
def __next__(self):
if self.sequence >= len(self.data):
#遍历超出范围时,返回一个异常
raise StopIteration()
r = self.data[self.sequence]
self.sequence += 1
return r
books = BookCollection()
print("第一次遍历")
for book in books:
print (book)
print("第二次遍历")
for book in books:
print (book)

要完成两次遍历,需要实例化两个迭代器:
class BookCollection:
def __init__(self):
self.data = ['《童年》','《在人间》','《我的大学》']
#记录遍历的序号
self.sequence = 0
pass
def __iter__(self):
return self
def __next__(self):
if self.sequence >= len(self.data):
#遍历超出范围时,返回一个异常
raise StopIteration()
r = self.data[self.sequence]
self.sequence += 1
return r
books1 = BookCollection()
books2 = BookCollection()
print("第一次遍历")
for book in books1:
print (book)
print("第二次遍历")
for book in books2:
print (book)

四.生成器
迭代器是关于对象的,生成器是关于函数的,让计算机存储Python列表会很占用内存,此时可以用生成器代替列表的一些功能。
先对比下面两段代码的结果:
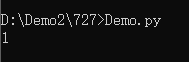
def gen(max):
n = 0
while n <= max:
n += 1
return n
print(gen(10000))
def gen(max):
n = 0
while n <= max:
n += 1
yield n
print(gen(10000))

生成器的使用方式:
1.使用next():
Demo:
def gen(max):
n = 0
while n <= max:
n += 1
yield n
g = gen(10000)
print(next(g))
print(next(g))
print(next(g))
2.使用for-in循环遍历:
def gen(max):
n = 0
while n <= max:
n += 1
yield n
g = gen(10000)
for i in g:
print(i)

用for-in制造生成器:
n = (i for i in range(0,10001))
print(n)

共同学习,写下你的评论
评论加载中...
作者其他优质文章



