
如果第二次看到我的文章,欢迎关注我~
这篇是「分布式系统理论」系列的第22篇,也是最后一篇。我们来聊聊分布式系统中的最后一道保障——监控。
监控这个事情,有点像我们平时对人的健康体检。想要效果好、结果靠谱,就得“全面体检”,每一项都做,否则哪怕检查报告都是正常,也不代表没有问题。下面这个景象是不是很熟悉?
运营小姐姐问:现在系统好卡啊。
程序员小哥哥答:我这里不卡啊,而且从数据来看很正常。
运营小姐姐问:[一张截图],你看一直在加载。
程序员小哥哥答:你的本地网络不好吧,打开别的网站试试。
……
监控里的“全面体检”有个高大上的叫法,「立体化监控」。
但是,越全面,成本越高。所以,根据所处的时期从中挑选合适的监控方式更加重要。
接下去,Z哥来和你一起梳理一下那些有必要做监控的地方。最后再给你一个普适性的建议。
监控的三个层次
从监控的目标来看,监控可以分为三个层次。分别是「环境指标」、「程序指标」、「业务指标」。
环境指标
环境指标主要是网络I/O、网络延迟、磁盘I/O、磁盘占用大小、CPU使用率、内存使用率、交换分区等等。
它们的目的是观测程序所在的环境,是不是稳定。就好比「水培绿箩」,再怎么好养的植物,你把下面的水煮一会,都得挂。
做环境指标的监控很简单。Z哥建议你二选一就好了。
无脑用的话,就Zabbix吧。非常成熟的企业级监控产品。网上安装教程有很多,随便搜一下就是。
如果服务器多的话,将Zabbix打包到进操作系统,做成一个镜像。这样一来,一台新服务器只要是从镜像安装的,就会自动加入到监控中。
如果愿意折腾,想二次开发的话可以使用小米开源的open-falcon。项目的活跃度还不错,可以了解一下:https://github.com/open-falcon/falcon-plus。
虽然功能的丰富度上比Zabbix差一些,但是毕竟是国人的产品,更加符合中国国情。国内有不少互联网企业也在用,或者基于它进行了二次开发,最有名的是美团二次开发的mt-falcon的。如果决定进行二次开发的话,可以借鉴一些mt-falcon在网上的公开信息。
程序指标
程序指标除了和环境指标一样的CPU使用率、内存使用率这种“外部“表现的指标之外,还有应用程序错误数、应用程序请求量、应用平均响应时间这种”内部“表现的指标。
其实做监控的时候有一个痛点,是不是「无侵入」的?
因为一旦需要侵入到具体的程序中去编写「埋点」代码,就很麻烦,毕竟涉及到更多的人一起配合嘛,推进更困难。
CPU使用率、内存使用率的监控比较简单,可以直接通过shell或者cmd调用系统API获取,和前面的环境指标一样。
但对于应用程序错误数、应用程序请求量、应用平均响应时间的监控,这里是一个分水岭,因为这里想要做到「无侵入」的效果,需要做一些额外的工作,否则只能编写大量的“埋点”代码。
比如,是不是有一个网关来统一进行流量分发?是不是有一个统一的RPC框架、数据库访问框架等等。如果有这样的统一模块就好办了,直接在这些模块里增加监控功能。
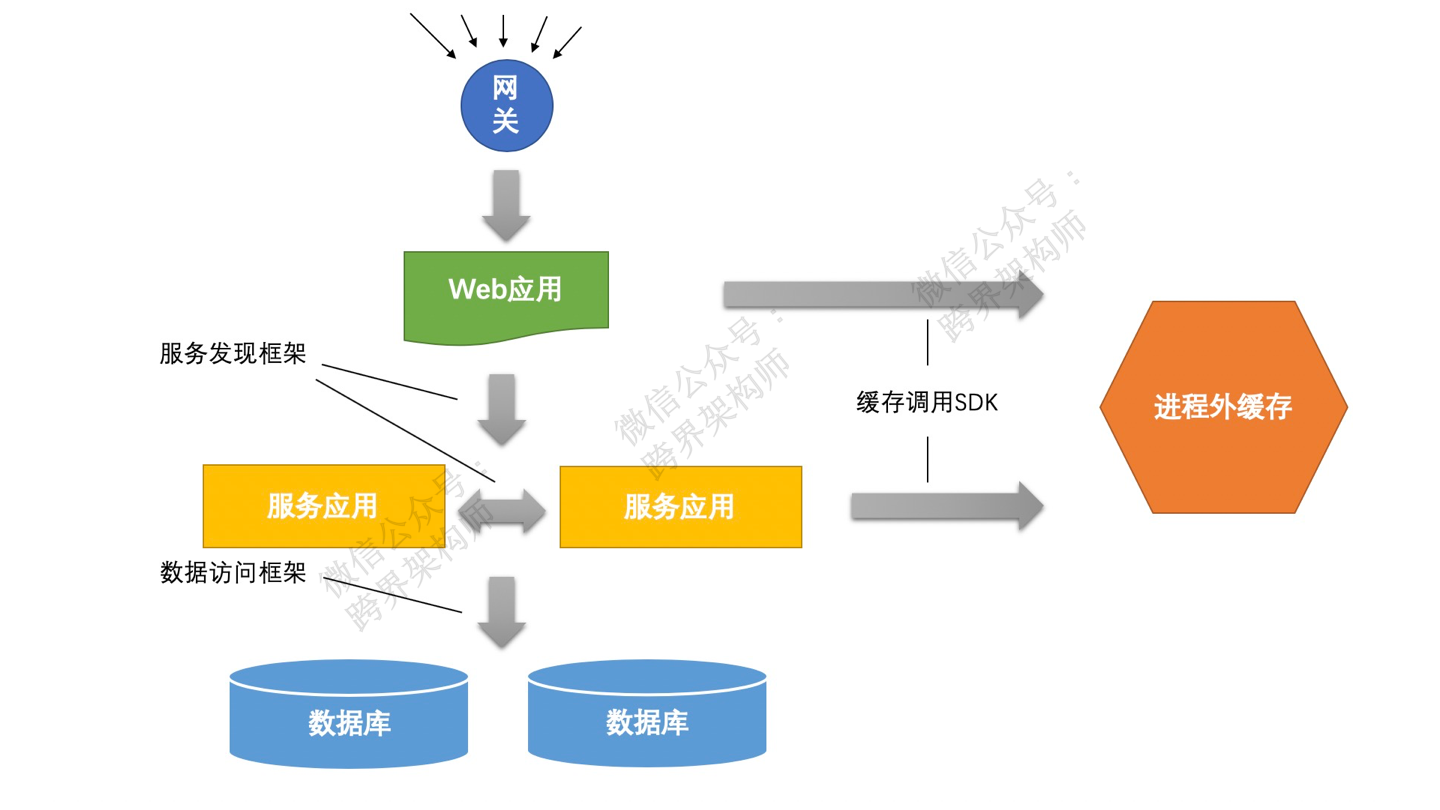
举个例子,你的rpc框架是统一的,那么只要在每次方法调用前和调用后记录好相应的数据,就可用于后续统计出结果。
关于采集到的数据如何存储,主流的选择是将数据写入到一个「时序数据库」中。比如Prometheus,这是一个专门做监控报警的开源框架,在全球都比较火,github上有23K的star。当然你也可以选择其他的时序数据库,如InfluxDB、OpenTSDB之类。
再配合以一个可视化框架,比如grafana,将其中的数据展示出来,就完成了整个监控系统的搭建。网上的搭建教程也有很多,就不多说了。
如果没有统一框架的话,可以优先考虑通过AOP的方式,以此尽量降低埋点代码的编写量。
数据采集就在AOP切入的位置进行。
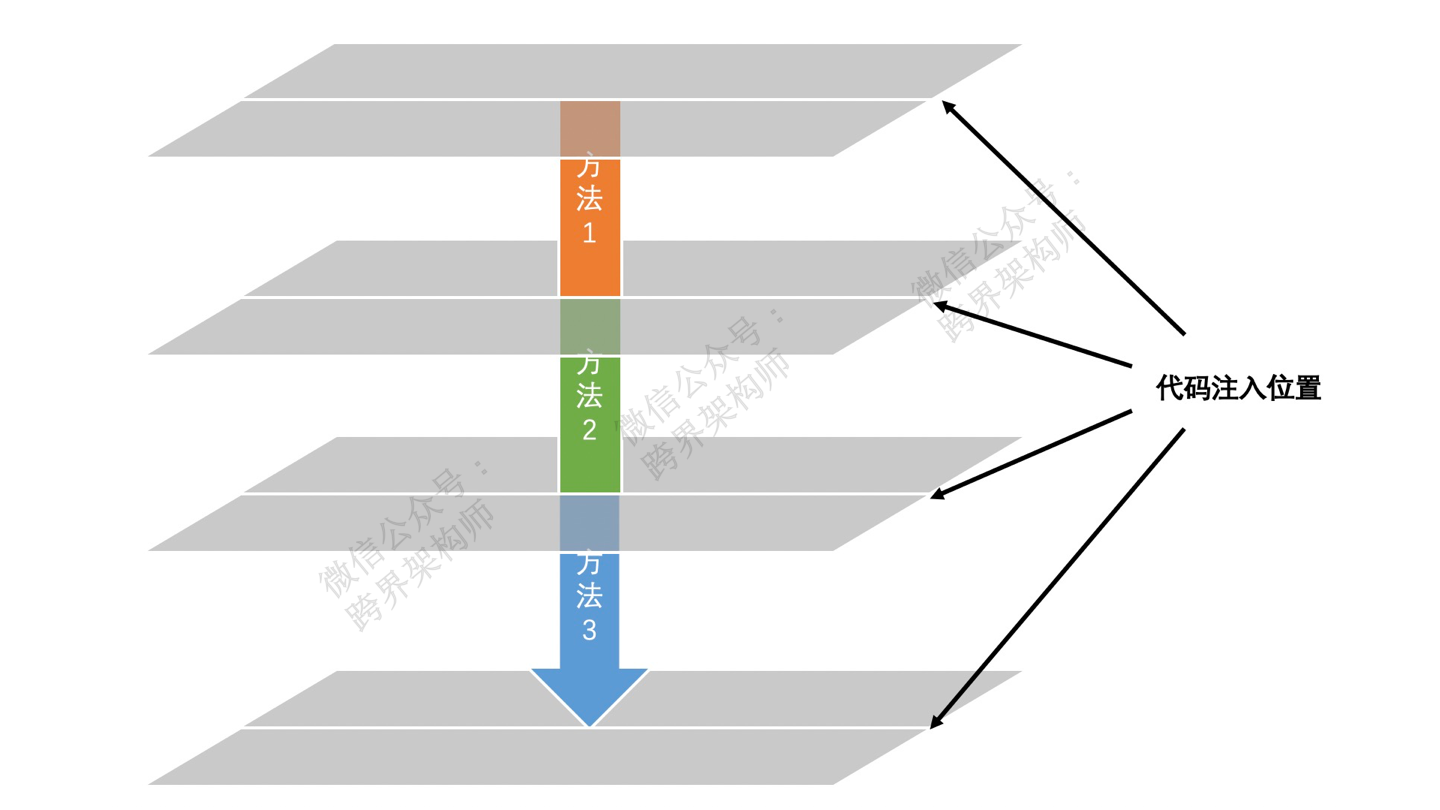
特别注意一点,由于监控产生的日志数量庞大,不建议直接与远程数据库交互。所以需要借助一些专门的日志采集和传输框架。比如flume、logstash。
怎么感觉一下子引入了好多新框架~,没办法,真要做好监控是挺繁琐的。
业务指标
在典型的程序员思维里,认为业务指标关我什么事。其实恰恰业务指标的监控更加的“有效”。因为业务指标出问题了,说明必然哪出问题了,不会像前面聊的两个层面的指标,可能看着好好的,但是实际业务却出了问题。
最近这2年在运营圈里被“爆炒”的「增长黑客」概念,本质上就是通过数据驱动的方式来做运营工作。而这背后依赖的就是一个业务指标监控系统。
每一个业务会经过的关键状态,都可以作为「业务指标」来监控。但是由于业务指标往往不具有「通用性」,所以,需要手动在程序里「埋点」。
因此,对业务指标的监控必然是「侵入性」的。
能不能不要埋点?也不是没有办法。
如果在一个系统的初期,比如日PV在百万以下的,直接通过业务数据库拉数据也不失为一个取巧的办法。这样就不用写什么埋点代码,简单粗暴。
到了成长期,直接拉业务数据库行不通了,因为会对正常的业务处理产生显著的性能影响。不过,此时还可以通过数据库层面做二次分发,将数据实时地复制到一个单独的库中,从这个库拉数据也能“撑”一段时间。
当然了,这些办法只能解决一部分问题。如果需要监控的业务指标不存在于业务流转的数据中(比如用户行为数据),那就没办法了,只能老老实实的写「埋点」代码。
总体来看,这三层指标恰好构成一个金字塔结构。从监控价值来看 业务指标 > 程序指标 > 环境指标。从实施的一个成本来看,也是 业务指标 > 程序指标 > 环境指标。

Z哥给你的普适性建议是,不管怎么样,环境指标先做了,毕竟投入的成本非常小,聊胜于无嘛。
其次,先通过直接拉db的方式监控部分重点业务指标。
然后,再把程序指标监控补充上。
最后,再查漏补缺完成所谓的全方位「立体化监控」。
告警策略
可能你会觉得文章到这里结束了,其实还没,前面主要聊了监控体系的“看”。但是监控体系还有另外一个重点是“叫”。缺少了「告警机制」的监控体系更像是个“面子工程”,实际的用处比较有限。
当你的系统还比较小的时候,告警怎么弄都行,哪怕每一次异常都触发告警。但是随着系统的发展,告警次数一多,就麻烦了,完全被“淹没”在了告警信息的”海洋“中,特别是那种专门有个“告警群”的情况下。
想象一下,告警群里每分钟都在弹出新的告警,哪怕你有“三头六臂”也处理不过来……
所以这里需要引入一个告警策略,使得告警更加的人性化。这个机制的核心就是4点。
梳理不同的告警级别
制定告警频率以及做好「收敛」(主要是去重、合并数量)
决定不同的告警级别通过什么形式发出通知(短信、手机通知、邮件等)
发给谁(比如,是不是需要“轮转”或者“逐级上报”这样)
当然了,现在越来越多的大型开发团队开始引入AI来使得告警更加的智能化,但是离我们大多数人所处的工作场景还是有一定距离的,不用急,一步一步来。
总结
好了,来一起总结一下。
这次呢,Z哥主要和你聊了在三个层次上的监控做法,并且给出了个人认为相对平滑的演进路线,供你参考。
然后,再聊了下告警策略的制定方式。告警需要更加的人性化,如此才能让人重视。
希望对你有所帮助。
如果你喜欢这篇文章,可以点一下左侧的「大拇指」。
这样可以给我一点反馈。: )
谢谢你的举手之劳。
关于作者:张帆(Zachary,个人号:跨界架构师)。坚持用心打磨每一篇高质量原创。
共同学习,写下你的评论
评论加载中...
作者其他优质文章


