
比上次增加了模型评估功能😎
import os
import pandas as pd
import numpy as np
import math
def train_data_reads(path):
data_directory = path + "/data"
#获取数据路径
data_name_list = os.listdir(data_directory)
file_name = data_name_list[0]
#数据的路径:data_path
data_path = data_directory + "/" + file_name
name,extension = file_name.split(".")
if extension == "csv":
try:
data = pd.read_csv(data_path,encoding = "gbk")
except:
data = pd.read_csv(data_path,encoding = "utf-8")
elif extension == "txt":
try:
data = pd.read_csv(data_path,encoding = "gbk",sep = "\t")
except:
data = pd.read_csv(data_path,encoding = "utf-8",sep = "\t")
else:
data = pd.read_excel(data_path)
return data
def train_data_reprocess(data):
#删除列数值相同的列
data = data.ix[:, (data != data.ix[0]).any()]
#剔除重复值
data = data.drop_duplicates()
data = data.reset_index(drop = True)
return data
def test_data_reads(path):
data_directory = path + "/data"
#获取数据路径
data_name_list = os.listdir(data_directory)
file_name = data_name_list[0]
#数据的路径:data_path
data_path = data_directory + "/" + file_name
name,extension = file_name.split(".")
if extension == "csv":
try:
data = pd.read_csv(data_path,encoding = "gbk")
except:
data = pd.read_csv(data_path,encoding = "utf-8")
elif extension == "txt":
try:
data = pd.read_csv(data_path,encoding = "gbk",sep = "\t")
except:
data = pd.read_csv(data_path,encoding = "utf-8",sep = "\t")
else:
data = pd.read_excel(data_path)
return data
def test_data_reprocess(data):
#删除列数值相同的列
#data = data.ix[:, (data != data.ix[0]).any()]
#剔除重复值
data = data.drop_duplicates()
data = data.reset_index(drop = True)
#删除ID
x = data.drop(["ID"],axis = 1)
#补全特征中的缺失值
feature_name_list = x.columns.values.tolist()
class_name_list = [name for name in feature_name_list if name.find("class") > 0]
num_name_list = [name for name in feature_name_list if name.find("num") > 0]
class_filled_df = x[class_name_list].fillna("missing")
num_filled_df = x[num_name_list].fillna(data.mean())
new_x = pd.concat([class_filled_df,num_filled_df],axis = 1)
return new_x
def feature_label_split(data):
#获取dataFrame的列名
name_list = data.columns.values.tolist()
label_name = name_list[len(name_list) - 1]
#将数据中label为空的数据删除
data = data[np.isnan(data[label_name]) == False]
#拆分特征与标签
x = data.drop([label_name],axis = 1)
y = data[label_name]
#补全特征中的缺失值
feature_name_list = x.columns.values.tolist()
class_name_list = [name for name in feature_name_list if name.find("class") > 0]
num_name_list = [name for name in feature_name_list if name.find("num") > 0]
class_filled_df = x[class_name_list].fillna("missing")
num_filled_df = x[num_name_list].fillna(data.mean())
new_x = pd.concat([class_filled_df,num_filled_df],axis = 1)
return new_x,y
#将分类特征转换成哑变量
def dummy_variable_transform(x):
#获取feature的列名
columns_name = x.columns.values.tolist()
columns_name = columns_name[1:-1]
for feature_name in columns_name:
feature_name_split = feature_name.split("_", 1)
name = feature_name_split[0]
feature_type = feature_name_split[1]
if feature_type == 'class':
dummy_class = pd.get_dummies(x[feature_name], prefix=name, drop_first=True)
x = x.drop(feature_name, axis=1).join(dummy_class)
return x
#对数据集X进行归一化
#线性回归对最大值,最小值敏感,思考一下,标准化Or归一化哪个更好
def data_MinMax(x):
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range = (0,1))
scaler.fit(x)
data = scaler.transform(x)
return data
def data_MinMax2(x):
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range = (-1,1))
scaler.fit(x)
data = scaler.transform(x)
return data
def data_std(x):
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(x)
data = scaler.transform(x)
return data
#为数据增加特征
def poly_data(x1):
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree = 2)
poly.fit(x1)
x2 = poly.transform(x1)
return x2
#划分训练集和测试集
def train_test_div(x,y,percent):
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size = percent)
return x_train,x_test,y_train,y_test
#train_test_split:先打乱顺序,然后进行分割
#1.线性回归预测
def lin_predict(x_train,x_test,y_train,y_test):
from sklearn import linear_model
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error,r2_score
linreg = LinearRegression()
linreg.fit(x_train,y_train)
y_pred = linreg.predict(x_test)
y_pred = list(map(lambda x: x if x >= 0 else 0,y_pred))
#y小于0时,赋值为0
y_pred = list(map(lambda x: x if x <= 10 else 10,y_pred))
#y大于10时,赋值为10
MAE = np.sum(np.absolute(y_pred - y_test)) / len(y_test)
return MAE
#2.决策树预测
#决策树不需要变量变为哑变量
def tree_predict(x_train,x_test,y_train,y_test):
from sklearn.tree import DecisionTreeRegressor
reg = DecisionTreeRegressor(max_depth = 100,min_samples_split = 50,min_samples_leaf = 50)
reg.fit(x_train,y_train)
y_pred = reg.predict(x_test)
y_pred = list(map(lambda x: x if x >= 0 else 0,y_pred))
#y小于0时,赋值为0
y_pred = list(map(lambda x: x if x <= 10 else 10,y_pred))
#y大于10时,赋值为10
MAE = np.sum(np.absolute(y_pred - y_test)) / len(y_test)
return MAE
def rf_predict(x_train,x_test,y_train,y_test):
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor()
rf.fit(x_train,y_train)
y_pred = rf.predict(x_test)
y_pred = list(map(lambda x: x if x >= 0 else 0,y_pred))
#y小于0时,赋值为0
y_pred = list(map(lambda x: x if x <= 10 else 10,y_pred))
#y大于10时,赋值为10
MAE = np.sum(np.absolute(y_pred - y_test)) / len(y_test)
return MAE
def xgb_predict(x_train,x_test,y_train,y_test):
import xgboost as xgb
model_xgb = xgb.XGBRegressor(base_score=0.5, booster='gbtree', colsample_bylevel=0.7, colsample_bytree=0.7, gamma=0,
learning_rate=0.05, max_delta_step=0, max_depth=6, min_child_weight=50, missing=None,
n_estimators=350, n_jobs=-1, nthread=None, objective='reg:linear', random_state=2019,
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None, silent=True, subsample=1)
model_xgb.fit(x_train, y_train)
y_pred = model_xgb.predict(x_test)
y_pred = list(map(lambda x: x if x >= 0 else 0,y_pred))
y_pred = list(map(lambda x: x if x <= 10 else 10,y_pred))
MAE = np.sum(np.absolute(y_pred - y_test)) / len(y_test)
return MAE
def gbr_predict(x_train,x_test,y_train,y_test):
from sklearn.ensemble import GradientBoostingRegressor
model_gbr = GradientBoostingRegressor(alpha=0.6, criterion='friedman_mse', init=None, learning_rate=0.05, loss='ls',
max_depth=3, max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None, min_samples_leaf=10, min_samples_split=2,
min_weight_fraction_leaf=0.01, n_estimators=750, presort='auto',
random_state=2019, subsample=0.7, verbose=0, warm_start=False)
model_gbr.fit(x_train, y_train)
y_pred = model_gbr.predict(x_test)
y_pred = list(map(lambda x: x if x >= 0 else 0,y_pred))
y_pred = list(map(lambda x: x if x <= 10 else 10,y_pred))
MAE = np.sum(np.absolute(y_pred - y_test)) / len(y_test)
return MAE
def xgb_predict2(x_train,x_test,y_train,y_test):
import xgboost as xgb
model_xgb = xgb.XGBRegressor(base_score=0.5, booster='gbtree', colsample_bylevel=0.7, colsample_bytree=0.7, gamma=0,
learning_rate=0.05, max_delta_step=0, max_depth=10, min_child_weight=50, missing=None,
n_estimators=600, n_jobs=-1, nthread=None, objective='reg:linear', random_state=2019,
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None, silent=True, subsample=0.9)
# booster : bgttree,gliner
model_xgb.fit(x_train, y_train)
y_pred = model_xgb.predict(x_test)
y_pred = list(map(lambda x: x if x >= 0 else 0,y_pred))
y_pred = list(map(lambda x: x if x <= 10 else 10,y_pred))
return y_pred
def gbr_predict2(x_train,x_test,y_train,y_test):
from sklearn.ensemble import GradientBoostingRegressor
model_gbr = GradientBoostingRegressor(alpha=0.6, criterion='friedman_mse', init=None, learning_rate=0.05, loss='ls',
max_depth=10, max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None, min_samples_leaf=200, min_samples_split=200,
min_weight_fraction_leaf=0.01, n_estimators=750, presort='auto',
random_state=2019, subsample=0.9, verbose=0, warm_start=False)
model_gbr.fit(x_train, y_train)
y_pred = model_gbr.predict(x_test)
y_pred = list(map(lambda x: x if x >= 0 else 0,y_pred))
y_pred = list(map(lambda x: x if x <= 10 else 10,y_pred))
return y_pred
#保存模型
def xgb_model(path,x_train,y_train):
import pickle
import xgboost as xgb
model_xgb = xgb.XGBRegressor(base_score=0.5, booster='gbtree', colsample_bylevel=0.7, colsample_bytree=0.7, gamma=0,
learning_rate=0.05, max_delta_step=0, max_depth=10, min_child_weight=50, missing=None,
n_estimators=600, n_jobs=-1, nthread=None, objective='reg:linear', random_state=2019,
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None, silent=True, subsample=0.9)
model_xgb.fit(x_train,y_train)
with open(path + "/model/xgb_regressor.pkl",'wb') as fw:
pickle.dump(model_xgb,fw)
def gbr_model(path,x_train,y_train):
import pickle
from sklearn.ensemble import GradientBoostingRegressor
model_gbr = GradientBoostingRegressor(alpha=0.6, criterion='friedman_mse', init=None, learning_rate=0.05, loss='ls',
max_depth=10, max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None, min_samples_leaf=200, min_samples_split=200,
min_weight_fraction_leaf=0.01, n_estimators=750, presort='auto',
random_state=2019, subsample=0.9, verbose=0, warm_start=False)
model_gbr.fit(x_train,y_train)
with open(path + "/model/gbr_regressor.pkl",'wb') as fw:
pickle.dump(model_gbr,fw)
#用模型做预测
def xgb_model_predict(path,x_test):
import pickle
import xgboost as xgb
with open(path + "/model/xgb_regressor.pkl",'rb') as fr:
reg = pickle.load(fr)
y = reg.predict(x_test)
return y
def gbr_model_predict(path,x_test):
import pickle
from sklearn.ensemble import GradientBoostingRegressor
with open(path + "/model/gbr_regressor.pkl","rb") as fr:
reg = pickle.load(fr)
y = reg.predict(x_test)
return y
#********************************************************学习曲线:基于分类问题*****************************************************************
#绘制学习曲线函数
def plot_learning_curves(model,X_train,X_test,y_train,y_test):
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
train_errors,test_errors = [],[]
for m in range(1,len(X_train)):
model.fit(X_train[:m],y_train[:m])
y_train_predict = model.predict(X_train[:m])
y_test_predict = model.predict(X_test)
train_errors.append(mean_squared_error(y_train_predict,y_train[:m]))
test_errors.append(mean_squared_error(y_test_predict,y_test))
plt.plot(np.sqrt(train_errors),"r-",linewidth = 1,label = "train")
plt.plot(np.sqrt(test_errors),"b-",linewidth = 1,label = "test")
plt.legend()
plt.show()
#GBDT学习曲线
def gbr_learning_curves(x_train,x_test,y_train,y_test):
from sklearn.ensemble import GradientBoostingClassifier
model_gbr = GradientBoostingClassifier()
plot_learning_curves(model_gbr,x_train,x_test,y_train,y_test)
#XGBOOST学习曲线
def xgb_learning_curves(x_train,x_test,y_train,y_test):
from xgboost.sklearn import XGBClassifier
model_xgb = XGBClassifier()
plot_learning_curves(model_xgb,x_train,x_test,y_train,y_test)
#随机森林学习曲线
def rf_learning_curves(x_train,x_test,y_train,y_test):
from sklearn.ensemble import RandomForestClassifier
model_rf = RandomForestClassifier()
plot_learning_curves(model_rf,x_train,x_test,y_train,y_test)
#**********************************************************ROC曲线**************************************************************************
def plot_roc_curve(fpr, tpr):
import matplotlib.pyplot as plt
from sklearn.metrics import auc
plt.figure()
lw = 2
roc_auc = auc(fpr,tpr)
plt.plot(fpr, tpr, color='darkorange',lw=lw, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0,1], [0,1], color='navy', lw=lw, linestyle='--')
plt.xlim([0, 1.0])
plt.ylim([0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.legend(loc="lower right")
plt.show()
def gbr_roc_curves(x_train,x_test,y_train,y_test):
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import roc_curve
model_gbr = GradientBoostingClassifier()
model_gbr.fit(x_train,y_train)
y_score = model_gbr.predict_proba(x_test)
fpr, tpr, _ = roc_curve(y_test, y_score[:,1])
plot_roc_curve(fpr, tpr)
def xgb_roc_curves(x_train,x_test,y_train,y_test):
from xgboost.sklearn import XGBClassifier
from sklearn.metrics import roc_curve
model_xgb = XGBClassifier()
model_xgb.fit(x_train,y_train)
y_score = model_xgb.predict_proba(x_test)
fpr, tpr, _ = roc_curve(y_test, y_score[:,1])
plot_roc_curve(fpr, tpr)
def rf_roc_curves(x_train,x_test,y_train,y_test):
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import roc_curve
model_rf = RandomForestClassifier()
model_rf.fit(x_train,y_train)
y_score = model_rf.predict_proba(x_test)
fpr, tpr, _ = roc_curve(y_test, y_score[:,1])
plot_roc_curve(fpr, tpr)
#**************************************************学习曲线2********************************
import matplotlib.pyplot as plt
from sklearn.model_selection import learning_curve
from sklearn.model_selection import ShuffleSplit
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None, n_jobs=1, train_sizes=np.linspace(.1, 1.0, 5)):
#estimator :模型
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel("Training examples")
plt.ylabel("Score")
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.1,
color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, 'o-', color="r",
label="Training score")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g",
label="Cross-validation score")
plt.legend(loc="best")
plt.show()
def gbr_learning_curves2(x,y):
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import roc_curve
model_gbr = GradientBoostingClassifier()
#model_gbr.fit(x_train,y_train)
title = "gbr_learning_curves"
cv = ShuffleSplit(n_splits=10, test_size=0.3, random_state=0)
plot_learning_curve(model_gbr, title, x,y, ylim=(0.5, 1.01), cv=cv, n_jobs=1)
def xgb_learning_curves2(x,y):
from xgboost.sklearn import XGBClassifier
from sklearn.metrics import roc_curve
model_xgb = XGBClassifier()
#model_xgb.fit(x_train,y_train)
title = "xgb_learning_curves"
cv = ShuffleSplit(n_splits=10, test_size=0.3, random_state=0)
plot_learning_curve(model_xgb, title,x,y, ylim=(0.5, 1.01), cv=cv, n_jobs=1)
def rf_learning_curves2(x,y):
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import roc_curve
model_rf = RandomForestClassifier()
#model_rf.fit(x_train,y_train)
title = "rf_learning_curves"
cv = ShuffleSplit(n_splits=10, test_size=0.3, random_state=0)
plot_learning_curve(model_rf, title,x,y, ylim=(0.5, 1.01), cv=cv, n_jobs=1)
def main():
path1 = "E:/AnaLinReg/Data6"
data = train_data_reads(path1)
data = train_data_reprocess(data)
x,y = feature_label_split(data)
x = dummy_variable_transform(x)
x = x.astype(np.float64)
x = data_std(x)
x_train,x_test,y_train,y_test = train_test_div(x,y,0.3)
xgb_learning_curves2(x,y)
if __name__ == "__main__":
main()
#模型生成
'''
path1 = "E:/AnaLinReg/Data"
data = train_data_reads(path1)
data = train_data_reprocess(data)
x,y = feature_label_split(data)
x = x.iloc[0:30000,:]
y = y.iloc[0:30000]
x = dummy_variable_transform(x)
x = x.astype(np.float64)
x = data_std(x)
x_train,x_test,y_train,y_test = train_test_div(x,y,0.3)
#生成模型
xgb_model(path1,x_train,y_train)
gbr_model(path1,x_train,y_train)
'''
#预测
'''
path1 = "E:/AnaLinReg/Data"
data = test_data_reads(path1)
data = test_data_reprocess(data)
x = dummy_variable_transform(data)
x = x.astype(np.float64)
x = data_MinMax(x)
y1 = xgb_model_predict(path1,x)
y2 = gbr_model_predict(path1,x)
y1 = pd.DataFrame(y1,index = data.index)
y2 = pd.DataFrame(y2,index = data.index)
y1 = pd.concat([data,y1],axis = 1)
y2 = pd.concat([data,y2],axis = 1)
y1.to_csv('predict1.csv')
y2.to_csv('predict2.csv')
'''
#指标
"""
a1 = 0
b1 = 0
c1 = 0
y = y.tolist()
y2 = y2.tolist()
for i in range(len(y)):
if (abs(y[i] - y2[i])) < 1:
a1 += 1
elif (abs(y[i] - y2[i])) < 2:
b1 += 1
else:
c1 += 1
print (len(y))
print ("a1 : ",a1," ",a1 / len(y))
print ("b1 : ",b1," ",b1 / len(y))
print ("c1 : ",c1," ",c1 / len(y))
s1 = 0
s2 = 0
for i in range(len(y)):
if (y2[i] >= 7):
s1 += 1
else:
s2 += 1
print ("满意: ", s1 / len(y))
print ("不满意 : ", s2 / len(y))
print ("\n")
print (y[0:20])
print ("\n")
print (y2[0:20])
print ("\n")
print (MAE)
"""
运行结果:
ROC曲线:
学习率曲线: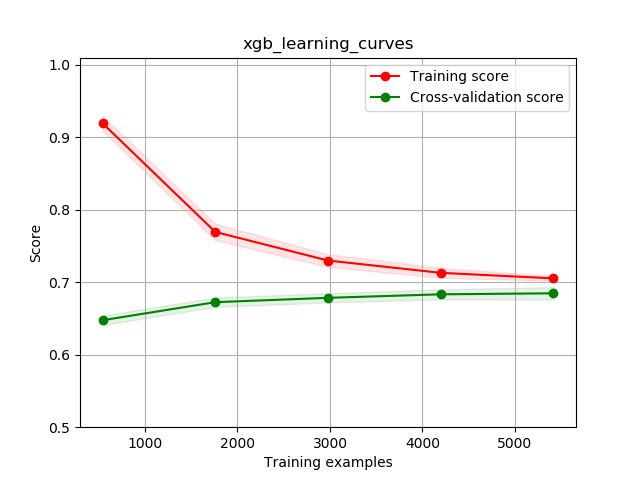
点击查看更多内容
1人点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中



感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦