
Boosting算法思路: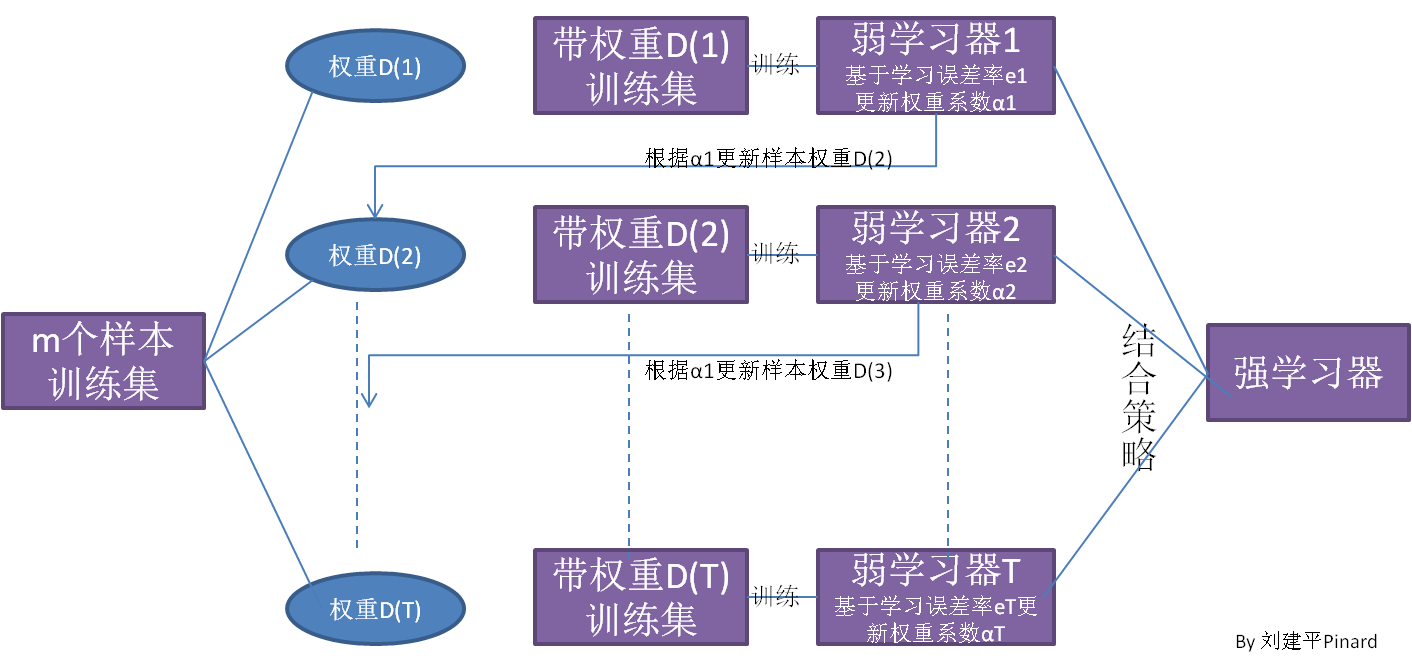
从图中可以看出,Boosting算法的工作机制是首先从训练集用初始权重训练出一个弱学习器1,根据弱学习的学习误差率表现来更新训练样本的权重,使得之前弱学习器1学习误差率高的训练样本点的权重变高,使得这些误差率高的点在后面的弱学习器2中得到更多的重视。然后基于调整权重后的训练集来训练弱学习器2.,如此重复进行,直到弱学习器数达到事先指定的数目T,最终将这T个弱学习器通过集合策略进行整合,得到最终的强学习器
Adaboost算法思路:
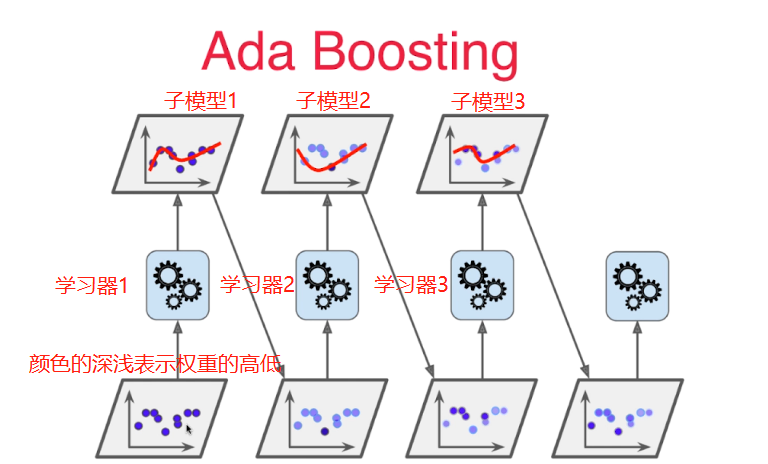
最后的分类/回归结果是由子模型投票决定的
CH1.Adaboost算法流程:
AdaBoost二元分类问题算法流程

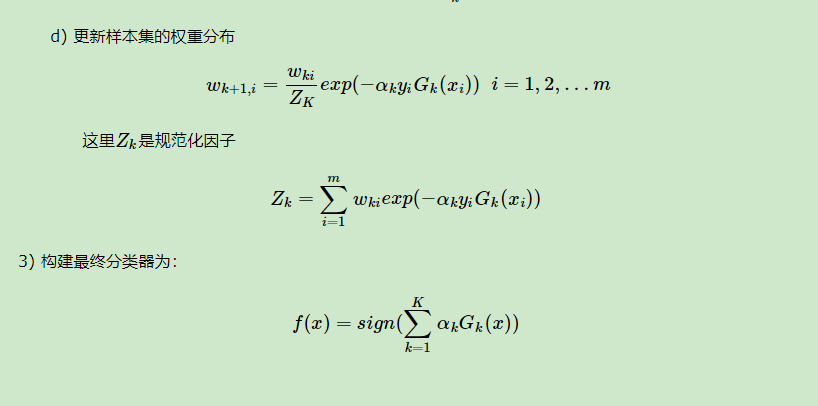
Adaboost回归问题的算法流程


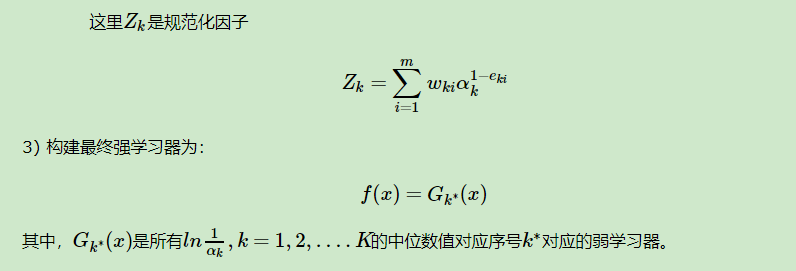
具体说来,整个Adaboost 迭代算法就3步:
1.初始化训练数据的权值分布。如果有N个样本,则每一个训练样本最开始时都被赋予相同的权重:1/N。
2.训练弱分类器。具体训练过程中,如果某个样本点已经被准确地分类,那么在构造下一个训练集中,它的权重就被降低;相反,如果某个样本点没有被准确地分类,那么它的权重就得到提高。然后,权重更新过的样本集被用于训练下一个分类器,整个训练过程如此迭代地进行下去。
3.将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起着较小的决定作用。换言之,误差率低的弱分类器在最终分类器中占的权重较大,否则较小。
Adaboost算法正则化:

CH2.算法实例
1.Adaboost算法实例一:
给定下列训练样本,请用AdaBoost算法学习一个强分类器: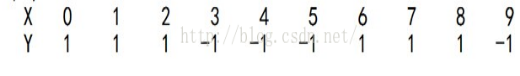
求解过程:
初始化训练数据的权值分布,令每个权值W1i = 1/N = 0.1,其中,N = 10,i = 1,2, …, 10
拿到这10组数据的训练样本后,根据 X 和 Y 的对应关系,要把这10个数据分为两类,一类是“Y=1”,一类是“Y=-1”,根据数据的特点发现:
“0 1 2”这3个数据对应的类是“1”,
“3 4 5”这3个数据对应的类是“-1”,
“6 7 8”这3个数据对应的类是“1”,
9是比较孤独的,对应类“-1”。
抛开孤独的9不讲,“0 1 2”、“3 4 5”、“6 7 8”这是3类不同的数据,分别对应的类是1、-1、1,直观上推测可知,可以找到对应的数据分界点,比如2.5、5.5、8.5 将那几类数据分成两类。当然,这只是主观臆测,下面实际计算下这个过程:
迭代过程1
在权值分布为D1(10个数据,每个数据的权值皆初始化为0.1)的训练数据上,经过计算可得:
1.阈值v取2.5时误差率为0.3(x < 2.5时取1,x > 2.5时取-1,则6 7 8分错,误差率为0.3),
2.阈值v取5.5时误差率最低为0.4(x < 5.5时取1,x > 5.5时取-1,则3 4 5 6 7 8皆分错,误差率0.6大于0.5,不可取。故令x > 5.5时取1,x < 5.5时取-1,则0 1 2 9分错,误差率为0.4),
3.阈值v取8.5时误差率为0.3(x < 8.5时取1,x > 8.5时取-1,则3 4 5分错,误差率为0.3)。
所以无论阈值v取2.5,还是8.5,总得分错3个样本,
故可任取其中任意一个如2.5,弄成第一个基本分类器:
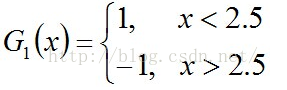
(1)0 1 2对应的类(Y)是1,因它们本身都小于2.5,所以被G1(x)分在了相应的类“1”中,分对了。
(2)3 4 5本身对应的类(Y)是-1,因它们本身都大于2.5,所以被G1(x)分在了相应的类“-1”中,分对了。
(3)但6 7 8本身对应类(Y)是1,却因它们本身大于2.5而被G1(x)分在了类"-1"中,所以这3个样本被分错了。
(4)9本身对应的类(Y)是-1,因它本身大于2.5,所以被G1(x)分在了相应的类“-1”中,分对了。
从而得到G1(x)在训练数据集上的误差率(被G1(x)误分类的样本“6 7 8”的权值之和):
e1=P(G1(xi)!=yi) = 3*0.1 = 0.3。
然后根据误差率e1计算G1的系数:
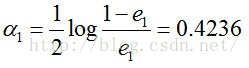
这个a1代表G1(x)在最终的分类函数中所占的权重,为0.4236。
接着更新训练数据的权值分布,用于下一轮迭代: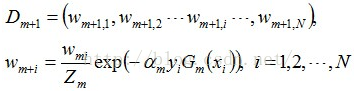
由权值更新的公式可知,每个样本的新权值是变大还是变小,取决于它是被分错还是被分正确。
第一轮迭代后,最后得到各个数据新的权值分布
D2 = (0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.1666, 0.1666, 0.1666, 0.0715)。
由此可以看出,因为样本中是数据“6 7 8”被G1(x)分错了,所以它们的权值由之前的0.1增大到0.1666,反之,其它数据皆被分正确,所以它们的权值皆由之前的0.1减小到0.0715。
分类函数f1(x)= a1*G1(x) = 0.4236G1(x)。
迭代过程2:
在权值分布为D2 = (0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.1666, 0.1666, 0.1666, 0.0715)的训练数据上,经过计算可得:
1.阈值v取2.5时误差率为0.16663(x < 2.5时取1,x > 2.5时取-1,则6 7 8分错,误差率为0.16663),
2.阈值v取5.5时误差率最低为0.07154(x > 5.5时取1,x < 5.5时取-1,则0 1 2 9分错,误差率为0.07153 + 0.0715),
3.阈值v取8.5时误差率为0.07153(x < 8.5时取1,x > 8.5时取-1,则3 4 5分错,误差率为0.07153)
对比发现,阈值v取8.5时误差率最低,故第二个基本分类器为: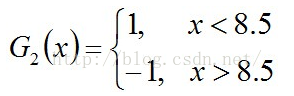
很明显:G2(x)把样本“3 4 5”分错了,根据D2可知它们的权值为0.0715, 0.0715, 0.0715,所以G2(x)在训练数据集上的误差率:
e2=P(G2(xi)!=yi) = 0.0715 * 3 = 0.2143。
计算G2的系数: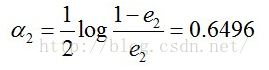
得到各个数据新的权值分布:
D3 = (0.0455, 0.0455, 0.0455, 0.1667, 0.1667, 0.01667, 0.1060, 0.1060, 0.1060, 0.0455)。
被分错的样本“3 4 5”的权值变大,其它被分对的样本的权值变小。
f2(x)=0.4236G1(x) + 0.6496G2(x)
迭代过程3:
对于m=3,在权值分布为D3 = (0.0455, 0.0455, 0.0455, 0.1667, 0.1667, 0.01667, 0.1060, 0.1060, 0.1060, 0.0455)的训练数据上,经过计算可得:
1.阈值v取2.5时误差率为0.10603(x < 2.5时取1,x > 2.5时取-1,则6 7 8分错,误差率为0.10603),
2.阈值v取5.5时误差率最低为0.04554(x > 5.5时取1,x < 5.5时取-1,则0 1 2 9分错,误差率为0.04553 + 0.0715),
3.阈值v取8.5时误差率为0.16673(x < 8.5时取1,x > 8.5时取-1,则3 4 5分错,误差率为0.16673)。
所以阈值v取5.5时误差率最低
此时,被误分类的样本是:0 1 2 9,这4个样本所对应的权值皆为0.0455,
所以G3(x)在训练数据集上的误差率:
e3= P(G3(xi)!=yi) = 0.0455*4 = 0.1820
计算G3的系数: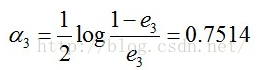
得到各个数据新的权值分布:
D4 = (0.125, 0.125, 0.125, 0.102, 0.102, 0.102, 0.065, 0.065, 0.065, 0.125)。被分错的样本“0 1 2 9”的权值变大,其它被分对的样本的权值变小。
f3(x)=0.4236G1(x) + 0.6496G2(x)+0.7514G3(x)
得到最终的分类器为:
G(x) = sign[f3(x)] = sign[ 0.4236G1(x) + 0.6496G2(x)+0.7514G3(x) ]。
2.Adaboost算法实例二:
代码来源:https://github.com/sidthekidder/ml_algorithms
import numpy as np
from decision_tree import id3, predict_example, print_tree
from sklearn.model_selection import train_test_split
def adaboost_classify(Xtrn, ytrn, Xtst, ytst, iterations):
# init weights to 1/N each
wts = np.ones(len(Xtrn)) / len(Xtrn)
pred_train = np.zeros(len(Xtrn))
pred_test = np.zeros(len(Xtst))
for i in range(iterations):
print("Training stump in iteration " + str(i))
dtree = id3(x=Xtrn, y=ytrn, attribute_value_pairs=None, depth=0, max_depth=1, weights=wts)
ytrn_pred = [predict_example(X, dtree) for X in Xtrn]
ytst_pred = [predict_example(X, dtree) for X in Xtst]
# number of misclassified examples for training set
misclassified = [int(x) for x in (ytrn_pred != ytrn)]
# multiply misclassified examples by weights
err = np.dot(wts, misclassified) / sum(wts)
# calculate alpha
alpha = np.log((1 - err) / err)
# convert misclassified from 0/1 to -1/1
misclassified = [x if x == 1 else -1 for x in misclassified]
# recalculate weights
wts = [x * np.exp(alpha*(x != ytrn_pred[i])) for i,x in enumerate(misclassified)]
# make predictions with current test observations
pred_train = [sum(x) for x in zip(pred_train, [x * alpha for x in ytrn_pred])]
pred_test = [sum(x) for x in zip(pred_test, [x * alpha for x in ytst_pred])]
pred_test = np.sign(pred_test)
return (sum(pred_test != ytst) / len(pred_test))
完整代码:
# implements adaboost and bagging classifier using decision tree as base estimator
import numpy as np
import os
import math
import random
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
from sklearn.ensemble import BaggingClassifier, AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
def entropy(y, wts=None):
counter = {}
for idx, i in enumerate(y):
if i in counter:
counter[i] += wts[idx]*1
else:
counter[i] = wts[idx]*1
entr = 0
for k,v in counter.items():
entr += -(v/sum(wts)) * math.log(v/sum(wts), 2)
return entr
def id3(x, y, attribute_value_pairs=None, depth=0, max_depth=5, weights=[]):
"""
creates a decision tree in dictionary format -
{(3, 2, False):
{(0, 1, False):
{(4, 2, True): 1,
(4, 2, False): 0},
(0, 1, True):
{(2, 1, True): 0,
(2, 1, False): 1}},
(3, 2, True): 1}
"""
# initialize default weights
if len(weights) == 0:
weights = np.ones(len(x)) / len(x)
# initialize attribute-value pairs
if attribute_value_pairs == None:
# generate all combinations of (column, value)
aggr = {}
# initialize empty list for each index
for idx, col in enumerate(x[0]):
aggr[idx] = set()
for row in x:
for idx, col in enumerate(row):
aggr[idx].add(col)
attribute_value_pairs = []
for k,v in aggr.items():
for vi in v:
attribute_value_pairs.append((k, vi))
# if all elements of list are the same, a set formed from the list will be of length 1
if len(set(y)) <= 1:
return y[0]
# if max depth reached or no further values to split on, return majority element
if len(attribute_value_pairs) == 0 or depth == max_depth:
# store a weighted counter for all unique elements
counter = {}
for idx, label in enumerate(y):
if label not in counter:
counter[label] = weights[idx]*1
else:
counter[label] += weights[idx]*1
# save the label with max weight
maj_ele = 0
max_val = 0
for k,v in counter.items():
if v > max_val:
maj_ele, max_val = k, v
return maj_ele
max_attr = None
max_info_gain = 0
cur_entropy = entropy(y, weights)
# for each possible column/value pair, split that column into 1s and 0s based on if it is equal to the value
# save attribute which gives max possible information gain
for attr in attribute_value_pairs:
column_index = attr[0]
value_to_split_on = attr[1]
new_column = [int(val == value_to_split_on) for val in x[:, column_index]]
# calculate mutual information if we choose this column to split on with this value
new_label_split_true = []
new_label_split_true_weights = []
new_label_split_false = []
new_label_split_false_weights = []
before_entropy = entropy(y, weights)
for idx, row in enumerate(new_column):
if row == 1:
new_label_split_true.append(y[idx])
new_label_split_true_weights.append(weights[idx])
else:
new_label_split_false.append(y[idx])
new_label_split_false_weights.append(weights[idx])
possible_entropy = (sum(new_label_split_true_weights)/sum(weights)) * entropy(new_label_split_true, new_label_split_true_weights) + \
(sum(new_label_split_false_weights)/sum(weights)) * entropy(new_label_split_false, new_label_split_false_weights)
mutual_info = abs(before_entropy - possible_entropy)
if (mutual_info > max_info_gain):
max_info_gain, max_attr = mutual_info, attr
# remove the selected next max attribute-value pair from the list of pairs
new_attribute_value_pairs = attribute_value_pairs.copy()
new_attribute_value_pairs.remove(max_attr)
# separate previous dataset into two datasets, based on rows which satisfy attr
x_true_elements = []
x_false_elements = []
y_true_elements = []
y_false_elements = []
for idx, val in enumerate(x):
if val[max_attr[0]] == max_attr[1]:
x_true_elements.append(val)
y_true_elements.append(y[idx])
else:
x_false_elements.append(val)
y_false_elements.append(y[idx])
x_true_elements = np.asarray(x_true_elements)
x_false_elements = np.asarray(x_false_elements)
# set the key as specified in comments above and value as recursive call to id3
max_attr_true = (max_attr[0], max_attr[1], True)
max_attr_false = (max_attr[0], max_attr[1], False)
tree = {}
tree[max_attr_true] = id3(x_true_elements, y_true_elements, new_attribute_value_pairs.copy(), depth+1, max_depth)
tree[max_attr_false] = id3(x_false_elements, y_false_elements, new_attribute_value_pairs.copy(), depth+1, max_depth)
return tree
def predict_item(x, tree):
# check if leaf label reached
if type(tree) is not dict:
return tree
for key in tree.keys():
true_option = tree[(key[0], key[1], True)]
false_option = tree[(key[0], key[1], False)]
if x[key[0]] == key[1]:
return predict_item(x, true_option)
else:
return predict_item(x, false_option)
def print_tree(tree, depth=0):
if type(tree) is not dict:
print(depth*"\t" + str(tree))
return
for idx, key in enumerate(tree):
print(depth*"\t" + "data[" + str(key[0]) + "] == " + str(key[1]) + "? " + str(key[2]))
print_tree(tree[key], depth+1)
def bagging(x, y, max_depth, num_trees):
trees_ensemble = []
for i in range(num_trees):
# randomly sample with replacement
sample_indexes = np.random.choice(np.arange(len(x)), len(x), replace=True)
xsample = x[sample_indexes]
ysample = y[sample_indexes]
dt = id3(xsample, ysample, max_depth=max_depth)
trees_ensemble.append(dt)
return trees_ensemble
def adaboost(Xtrn, ytrn, max_depth, num_stumps):
ensemble = []
# init weights to 1/N each
weights = np.ones(len(Xtrn)) / len(Xtrn)
for i in range(num_stumps):
dtree = id3(Xtrn, ytrn, max_depth=max_depth, weights=weights)
# predict using the newly learnt stump
y_pred = [predict_item(X, dtree) for X in Xtrn]
# calculate error
err = 0
for idx, predicted_item in enumerate(y_pred):
if predicted_item != ytrn[idx]:
err += weights[idx]
err /= sum(weights)
# calculate alpha
alpha = 0.5 * np.log((1 - err) / err)
# save the hypothesis stump along with alpha weight
ensemble.append((dtree, alpha))
# recalculate weights
new_weights = []
for idx, weight in enumerate(weights):
if y_pred[idx] == ytrn[idx]:
new_weights.append(weight * np.exp(-alpha))
else:
new_weights.append(weight * np.exp(alpha))
# normalize weights
newsum = weights / (2 * np.sqrt((1 - err) * err))
new_weights = new_weights / sum(newsum)
weights = new_weights
return ensemble
def predict_example(x, h_ens):
predictions = []
# for each testing example
for item in x:
# keep count of the weighted number of times each label is predicted
options = {}
for tree in h_ens:
pred_label = predict_item(item, tree[0])
if pred_label not in options:
options[pred_label] = 0
options[pred_label] += 1*tree[1] # multiply by weight of this ensemble
# save the label with max weight
selected_label = 0
max_val = 0
for k,v in options.items():
if v > max_val:
selected_label, max_val = k, v
predictions.append(selected_label)
return predictions
if __name__ == "__main__":
# load training data
dataset1 = np.genfromtxt('./mushroom.train', missing_values=0, delimiter=',', dtype=int)
ytrn = dataset1[:, 0] # select prediction column
Xtrn = dataset1[:, 1:] # select all other columns
dataset2 = np.genfromtxt('./mushroom.test', missing_values=0, delimiter=',', dtype=int)
ytst = dataset2[:, 0] # select prediction column
Xtst = dataset2[:, 1:] # select all other columns
# BAGGING
print("BAGGING:")
for depth in [3, 5]:
for tree in [5, 10]:
print("\nLearning ensemble for depth = " + str(depth) + " and k = " + str(tree) + "")
ensemble = bagging(Xtrn, ytrn, max_depth=depth, num_trees=tree)
y_pred = predict_example(Xtst, [(e, 1) for e in ensemble])
# compute testing error
tst_err = sum(ytst != y_pred) / len(ytst)
print("Accuracy: " + str(100 - tst_err*100) + "%")
print("Confusion matrix: ")
print(confusion_matrix(ytst, y_pred))
# BOOSTING
print("\nBOOSTING:")
for depth in [1, 2]:
for stump in [5, 10]:
print("\nLearning ensemble for depth = " + str(depth) + " and k = " + str(stump) + "...")
ensemble = adaboost(Xtrn, ytrn, max_depth=depth, num_stumps=stump)
y_pred = predict_example(Xtst, ensemble)
# compute testing error
tst_err = sum(ytst != y_pred) / len(ytst)
print("Accuracy: " + str(100 - tst_err*100) + "%")
print(confusion_matrix(ytst, y_pred))
# BAGGING using scikit-learn
print("\nBAGGING using scikit-learn:")
for depth in [3, 5]:
for tree in [5, 10]:
print("\nLearning ensemble for depth = " + str(depth) + " and k = " + str(tree) + "")
y_pred = BaggingClassifier(base_estimator=DecisionTreeClassifier(criterion='entropy', max_depth=depth), n_estimators=tree).fit(Xtrn, ytrn).predict(Xtst)
#, max_depth=depth, num_trees=tree)
# y_pred = predict_example(Xtst, [(e, 1) for e in ensemble])
# compute testing error
tst_err = sum(ytst != y_pred) / len(ytst)
print("Accuracy: " + str(100 - tst_err*100) + "%")
print("Confusion matrix: ")
print(confusion_matrix(ytst, y_pred))
# BOOSTING using scikit-learn
print("\nBOOSTING using scikit-learn:")
for depth in [1, 2]:
for tree in [5, 10]:
print("\nLearning ensemble for depth = " + str(depth) + " and k = " + str(tree) + "")
y_pred = AdaBoostClassifier(base_estimator=DecisionTreeClassifier(criterion='entropy', max_depth=depth), n_estimators=tree).fit(Xtrn, ytrn).predict(Xtst)
#, max_depth=depth, num_trees=tree)
# y_pred = predict_example(Xtst, [(e, 1) for e in ensemble])
# compute testing error
tst_err = sum(ytst != y_pred) / len(ytst)
print("Accuracy: " + str(100 - tst_err*100) + "%")
print("Confusion matrix: ")
print(confusion_matrix(ytst, y_pred))
3.Adaboost算法实例三——马疝病的预测
代码来源:ApacheCN :https://github.com/apachecn/AiLearning
这个就不贴代码了,有时间我会把它复现一遍,单独写一篇博客
4.Adaboost算法实例四:
代码来源:https://github.com/simsicon/AdaBoostTrees
Boost.py
import random
import time
import numpy as np
from collections import Counter
from tree import Tree
class Boosting:
def __init__(self, X, y, n_estimators=10, n_samples=1024):
self.X = X
self.y = y
self.n_estimators = n_estimators
self.n_samples = n_samples
self.N = self.y.shape[0]
self.weights = [1 / self.N for _ in range(self.N)]
self.alphas = []
self.estimators = None
self.count = 0
def init_estimator(self):
indices = [i for i in np.random.choice(X.shape[0], self.n_samples, p=self.weights)]
X_tree = np.array([X[i, :] for i in indices])
y_tree = np.array([y[i] for i in indices])
print "%s / %s" % (self.count, self.n_estimators)
while True:
t1 = time.time()
tree = Tree(X_tree, y_tree)
t2 = time.time()
print "tree generation time: %s" % (t2 - t1)
predictions = tree.predict(self.X)
accuracy = accuracy_score(self.y, predictions)
print "accuracy: %s" % accuracy
if accuracy != 0.50:
self.estimators.append(tree)
break
return tree, predictions
def train(self):
self.count = 0
self.estimators = []
t1 = time.time()
for _ in range(self.n_estimators):
self.count += 1
estimator, y_pred = self.init_estimator()
errors = np.array([ y_i != y_p for y_i, y_p in zip(y, y_pred)])
agreements = [-1 if e else 1 for e in errors]
epsilon = sum(errors * self.weights)
print "epsilon: %s" % epsilon
alpha = 0.5 * np.log((1 - epsilon) / epsilon)
z = 2 * np.sqrt(epsilon * ( 1 - epsilon))
self.weights = np.array([(weight / z) * np.exp(-1 * alpha * agreement)
for weight, agreement in zip(self.weights, agreements)])
print "weights sum: %s" % sum(self.weights)
self.alphas.append(alpha)
t2 = time.time()
print "train took %s s" % (t2 - t1)
def predict(self, X):
predicts = np.array([estimator.predict(X) for estimator in self.estimators])
weighted_prdicts = [[(p_i, alpha) for p_i in p] for alpha, p in zip(self.alphas, predicts)]
H = []
for i in range(X.shape[0]):
bucket = []
for j in range(len(self.alphas)):
bucket.append(weighted_prdicts[j][i])
H.append(bucket)
return [self.weighted_majority_vote(h) for h in H]
def weighted_majority_vote(self, h):
weighted_vote = {}
for label, weight in h:
if label in weighted_vote:
weighted_vote[label] = weighted_vote[label] + weight
else:
weighted_vote[label] = weight
max_weight = 0
max_vote = 0
for vote, weight in weighted_vote.iteritems():
if max_weight < weight:
max_weight = weight
max_vote = vote
return max_vote
import random
import time
import numpy as np
from collections import Counter
class Node:
STOP_ESITIMATOR_NUM = 10
def __init__(self, X, y, verbose=False, verboseverbose=False):
self.X = X
self.y = y
self.left_child, self.right_child = None, None
self.is_leaf = False
self.best_attr_index = None
self.threshold_func = self.random_uniform_threshold_split
self.before_split_entropy = self.entropy(self.y)
self.verbose = verbose
self.verboseverbose = verboseverbose
def walk(self, x, indent=0):
if self.is_leaf:
_v = self.vote()
if self.verboseverbose:
print indent * " " + "leaf: %s" % _v
return _v
if self.verboseverbose:
print indent * " " + "branch: %s, %s" % (self.best_attr_index, self.best_threshold)
if x[self.best_attr_index] <= self.best_threshold:
return self.left_child.walk(x, indent=indent+1)
elif x[self.best_attr_index] > self.best_threshold:
return self.right_child.walk(x, indent=indent+1)
def vote(self):
if self.is_leaf:
return Counter(self.y).most_common(1)[0][0]
else:
return None
def choose_best_attr(self):
if self.X.shape[0] < self.STOP_ESITIMATOR_NUM:
if self.verboseverbose:
print "time to stop with sample %s, %s" % self.X.shape
self.is_leaf = True
return
max_info_gain = -1
_best_attr_index = None
_best_threshold = None
_best_X_left, _best_y_left, _best_X_right, _best_y_right = None, None, None, None
for i in range(self.X_attrs_num()):
X_left, y_left, X_right, y_right, threshold, conditional_entropy = \
self.split_with_attr(i)
info_gain = self.before_split_entropy - conditional_entropy
if info_gain > max_info_gain:
max_info_gain = info_gain
_best_attr_index = i
_best_threshold = threshold
_best_X_left, _best_y_left, _best_X_right, _best_y_right = X_left, y_left, X_right, y_right
if self.verboseverbose:
print "attr %s with info gain %s, current max info gain is %s" % (i, info_gain, max_info_gain)
if _best_attr_index is not None:
self.best_attr_index = _best_attr_index
self.best_threshold = _best_threshold
self.X_left = _best_X_left
self.y_left = _best_y_left
self.X_right = _best_X_right
self.y_right = _best_y_right
def split_with_attr(self, attr_index):
if self.threshold_func is None:
self.threshold_func = self.random_uniform_threshold_split
return self.threshold_func(attr_index)
def random_uniform_threshold_split(self, attr_index):
X_sorted = sorted(self.X, key=lambda x: x[attr_index])
_min, _max = X_sorted[0][attr_index], X_sorted[-1][attr_index]
threshold = np.random.uniform(_min, _max, 1)[0]
_conditional_entropy, _X_left, _y_left, _X_right, _y_right = self.conditional_entropy(attr_index, threshold)
return _X_left, _y_left, _X_right, _y_right, threshold, _conditional_entropy
def exhaustive_approx_threshold_split(self, attr_index, approx_precision=1):
total_count = len(self.y)
X_sorted = sorted(self.X, key=lambda x: x[attr_index])
thresholds = [(X_sorted[i][attr_index] + X_sorted[i+1][attr_index]) / 2
for i in range(total_count) if i < total_count - 1]
approx_thresholds = set([round(threshold, approx_precision) for threshold in thresholds])
_best_threshold_of_attr = None
_max_info_gain_of_attr = -1
_least_conditional_entropy = None
if self.verboseverbose:
print " %s thresholds to approx: %s" % (len(approx_thresholds), approx_thresholds)
for threshold in approx_thresholds:
_conditional_entropy, _X_left, _y_left, _X_right, _y_right = self.conditional_entropy(attr_index, threshold)
info_gain = self.before_split_entropy - _conditional_entropy
if info_gain > _max_info_gain_of_attr:
_max_info_gain_of_attr = info_gain
_best_threshold_of_attr = threshold
_least_conditional_entropy = _conditional_entropy
X_left, y_left, X_right, y_right = _X_left, _y_left, _X_right, _y_right
if self.verboseverbose:
print " approx threshold %s with info gain %s" % (threshold, info_gain)
return X_left, y_left, X_right, y_right, _best_threshold_of_attr, _least_conditional_entropy
def X_len(self):
return self.X.shape[0]
def X_attrs_num(self):
return self.X.shape[1]
def entropy(self, labels):
labels_counter = Counter(labels)
total_count = len(labels)
label_probabilities = [label_count / total_count for label_count in labels_counter.values()]
return sum([ - p * np.log2(p) for p in label_probabilities if p])
def conditional_entropy(self, attr_index, threshold):
total_count = len(self.y)
_X_left, _y_left, _X_right, _y_right = self.partitions(attr_index, threshold)
entropy_left = self.entropy(_y_left)
entropy_right = self.entropy(_y_right)
_conditional_entropy = ((len(_y_left) / total_count) * entropy_left +
(len(_y_right) / total_count) * entropy_right)
return _conditional_entropy, _X_left, _y_left, _X_right, _y_right
def partitions(self, attr_index, threshold):
indices_left = [i for i, x_i in enumerate(self.X) if x_i[attr_index] <= threshold]
indices_right = [i for i, x_i in enumerate(self.X) if x_i[attr_index] > threshold]
X_left = np.array([self.X[i] for i in indices_left])
y_left = np.array([self.y[i] for i in indices_left])
X_right = np.array([self.X[i] for i in indices_right])
y_right = np.array([self.y[i] for i in indices_right])
return X_left, y_left, X_right, y_right
def X_left_len(self):
return self.X_left.shape[0]
def X_right_len(self):
return self.X_right.shape[0]
class Tree:
def __init__(self, X, y, verbose=False, verboseverbose=False):
self.X = X
self.y = y
self.verbose = verbose
self.verboseverbose = verboseverbose
self.root = self.build_tree(self.X, self.y)
def build_tree(self, X, y, indent=0):
"""
Three concerns:
1. Node has no enough samples to choose the best attr and split,
then return the node itself.
2. Either left or right child has no enough samples to continue,
then attach the child and contiue the other.
If the other child is classified, return the node.
3. Neither left nor right child has enough samples to continue,
then attach the both children and return the node itself.
"""
if self.verbose:
print indent * " " + str(X.shape[0])
if X.shape[0] == 0:
return None
node = Node(X, y, verbose=self.verbose, verboseverbose=self.verboseverbose)
if len(set(y)) == 1 or node.X_len() < node.STOP_ESITIMATOR_NUM:
node.is_leaf = True
return node
node.choose_best_attr()
if not node.is_leaf:
node.left_child = self.build_tree(node.X_left, node.y_left, indent=indent + 1)
node.right_child = self.build_tree(node.X_right, node.y_right, indent=indent + 1)
return node
def predict(self, X):
return [self.root.walk(x_i) for x_i in X]
共同学习,写下你的评论
评论加载中...
作者其他优质文章



