
导语
制作编程语言是一项很有趣但也有难度的活,准备徐徐道来,慢慢推进与讲解编程语言解释器的算法和代码。
都说程序员的最大理想就是开发出自己的编程语言来,现在,我也开始完成我最大的理想——开发我属于我自己的编程语言。
阅读了许多关于自制编程语言的书籍,可略感失望,感觉很多都是使用yacc/lex这些他人写好的工具生成代码,从而制作解释器,唯一得到的帮助就是解释器的大概基本原理和结构。
取名记
名字,是一个好项目很重要的一点,我绞尽脑汁思索许久,终于创造出来一个英语短语:BerryMath。为什么取这个名呢?首先Berry就是浆果,梅的意思,然后Math是数学的意思,翻译成中文就是数梅语言。因为Berry是我比较喜欢吃的一项水果类型😂,并且在编程中数学是非常重要的一环,所以取名BerryMath。
使用语言
为了速度和跨平台性着想,我选择C++语言进行编写。
项目链接
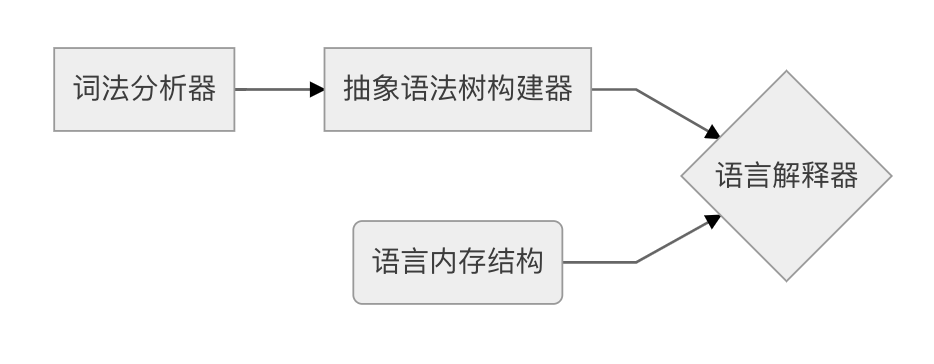
项目架构
项目架构图
项目文件结构
- include
- BerryMath.h
- interpreter.h
- value.h
- ast.h
- lex.h
- include
- BerryMath.cpp
- interpreter.cpp
- value.cpp
- ast.cpp
- lex.cpp
- main.cpp
解释器流程
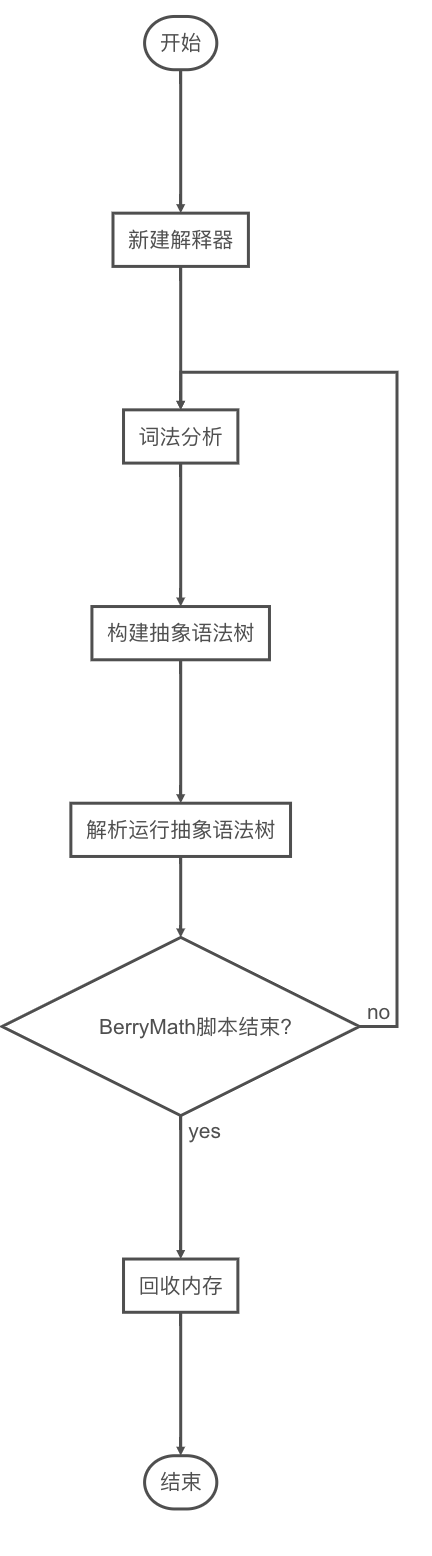
着手实现
接口文件编写
首先创建BerryMath.h和BerryMath.cpp文件,后期拓展开发等都需要引入该头文件
include/BerryMath.h
#ifndef BERRYMATH_BERRYMATH_H
#define BERRYMATH_BERRYMATH_H
#include "value.h"
#include "lex.h"
namespace BM {
}
#endif //BERRYMATH_BERRYMATH_H
src/BerryMath.cpp
#include "BerryMath.h"
语言内存实现
首先,这门语言我设计是动态类型语言,万物皆对象,所以内存部分设计如下:
并且,为了内存管理,编写妥善的垃圾回收机制,我们在基类Object中需要用unsigned long类型的linked属性以存储引用次数。这样在执行析构函数时,遍历所以属性,linked减一,尔后linked为0的就是没有任何Object或者后面的Variable类应用,即可删除了。
接着,为了便于调试查看,和后面编写语言拓展库时print等函数的编写,基类Object应当还有toString()成员函数用于返回std::string类型的值, 并有private的print函数用于打印数据,最后重载运算符,使得其可以被ostream类的实例化对象输出,比如cout。
在这时,我们还要考虑一点:toString转换有一个小bug:如果object的属性中有一个属性或属性的属性的值是自己(即循环调用),就会陷入死循环,所以我们还需要一个parent对象存储父节点,并有一个has成员函数用于判断某值是否是祖先节点,如果是,就将那个值toString的值为…。
然后呢,我们开始看一些有关属性读写的成员函数。
首先,我们需要一个插入值的函数,insert,需要接受std::string和Object*,这个函数流程主要是:插入属性值,增加引用计数,将值的parent属性设为自己。
有set函数,用于写属性值,如果没有该属性,就insert进去,有就修改,流程基本同insert
有get函数,用于获得某属性的值,return Object*类型的值。
还有del函数,用于删除某属性,首先找到该属性的值,然后从proto中删除,引用计数减一,如果引用计数为0,delete.
最后,析构函数,也与del函数类似,不过是遍历每一个属性,删除每一个属性罢了。
最后include/value.h、src/value.cpp代码如下:
include/value.h
#ifndef BERRYMATH_VALUE_H
#define BERRYMATH_VALUE_H
#include <iostream>
#include <string>
#include <map>
#include <sstream>
using std::string;
using std::map;
typedef unsigned long UL;
namespace BM {
class Object {
public:
Object() : linked(0), parent(nullptr) { }
bool has(Object*, Object*);
void set(const string &key, Object *value);
void insert(string, Object*);
Object* get(const string &key);
void del(const string &key);
Object& operator[](const string &key) { return *get(key); }
UL links() { return linked; }
UL bind() { return ++linked; }
UL unbind() { return --linked; }
virtual string toString(bool = true, bool = true, string = "");
virtual Object* copy() {
auto object = new Object();
for (auto iter = proto.begin(); iter != proto.end(); iter++) {
object->set(iter->first, iter->second->copy());
}
return object;
}
virtual ~Object();
friend std::ostream& operator<<(std::ostream& o, Object& v) {
v.print(o);
return o;
}
protected:
void print(std::ostream&, bool = true);
UL linked;
map<string, Object*> proto;
Object* parent;
};
class Number : public Object {
public:
Number() : Object(), v(0) { }
Number(double t) : Object(), v(t) { }
string toString(bool = true, bool hl = true, string tab = "") {
string o("");
std::ostringstream oss;
oss << v;
if (hl) o += "\033[33m";
o += oss.str();
if (hl) o += "\033[0m";
return o;
}
double& value() { return v; }
Object* copy() {
return new Number(v);
}
~Number() { }
private:
double v;
};
class String : public Object {
public:
String() : Object(), v("") { }
String(const string& t) : Object(), v(t) { }
string toString(bool = true, bool hl = true, string tab = "") {
string o("");
if (hl) o += "\033[32m";
o += "\"" + v + "\"";
if (hl) o += "\033[0m";
return o;
}
string& value() { return v; }
Object* copy() {
return new String(v);
}
~String() { }
private:
string v;
};
class Null : public Object {
public:
Null() : Object() { }
string toString(bool = true, bool hl = true, string tab = "") {
string o("");
if (hl) o += "\033[36m";
o += "null";
if (hl) o += "\033[0m";
return o;
}
Object* copy() {
return new Null;
}
~Null() { }
};
class Undefined : public Object {
public:
Undefined() : Object() { }
string toString(bool = true, bool hl = true, string tab = "") {
string o("");
if (hl) o += "\033[35m";
o += "undefined";
if (hl) o += "\033[0m";
return o;
}
Object* copy() {
return new Undefined;
}
~Undefined() { }
};
}
#endif //BERRYMATH_VALUE_H
src/value.cpp
#include "../include/value.h"
bool BM::Object::has(Object *v, Object* root = nullptr) {
if (!root) root = this;
if (this == v || parent == v) return true;
if (parent == root) return false;
if (parent && parent != this) return parent->has(v, root);
return false;
}
string BM::Object::toString(bool indent, bool hl, string tab) {
string o("{");
if (indent) {
o += "\n";
tab += "\t";
}
auto iter = proto.begin();
auto end = proto.end();
for (; iter != end; iter++) {
const string& key = iter->first;
if (key[0] == '_' && key[1] == '_') continue;// 双下划线开头的属性不显示
o += tab;
if (hl) {
o += "\033[32m\"" + key + "\"\033[0m";
} else {
o += "\"" + key + "\"";
}
o += ": ";
if (has(iter->second)) o += "...";
else o += iter->second->toString(indent, hl, tab);
o += ",";
if (indent) o += '\n';
}
if (indent) {
tab.pop_back();
o += tab;
}
o += "}";
return o;
}
void BM::Object::print(std::ostream &o, bool hl) {
o << toString(true, hl) << std::endl;
}
void BM::Object::set(const string &key, Object *value) {
if (proto.count(key) == 0) {
insert(key, value);
} else {
proto[key] = value;
if (this != value) value->linked++;
value->parent = this;
}
}
BM::Object* BM::Object::get(const string &key) {
auto iter = proto.find(key);
if (iter == proto.end()) return nullptr;
return iter->second;
}
void BM::Object::insert(string key, Object *value) {
proto.insert(std::pair<string, Object*>(key, value));
if (this != value) value->linked++;
value->parent = this;
}
void BM::Object::del(const string &key) {
auto iter = proto.find(key);
if (iter == proto.end()) return;,
proto.erase(iter);
Object* v = iter->second;
v->linked--;
if (v->linked < 1) delete v;
}
BM::Object::~Object() {
for (auto iter = proto.begin(); iter != proto.end(); iter++) {
Object* v = iter->second;
if (!v || v->linked < 1 || has(v)) continue;
v->linked--;
if (v->linked < 1) delete v;
iter->second = nullptr;
}
proto.clear();
}
以上,内存管理部分基本完成。
语言设计
磨刀不误砍柴工,在继续编写解释器之前,我们还要首先确定语言语法的结构内容。
首先,作为一门动态语言,我希望它是类似JavaScript这样的脚本语言,以花括号著称,而非Python那样的冒号。但是呢,在语言、API方面也要和JavaScript有所不同。
第一,是枚举类型的定义
enum COLORS {
RED, BLACK, WHITE, BLUE, ORANGE, PINK
}
然后可以通过COLORS.RED这样的方式来访问枚举类型。
第二,是using方法的定义
enum COLORS {
RED, BLACK, WHITE, BLUE, ORANGE, PINK
}
using COLORS;
println(RED);
可以将对象、枚举类型的所有属性加入到当前作用域中
第三,是class的构造函数为ctor而非construction
第四,将js中的get和set改为getter和setter
第五,是可以设置class中的一些原型属性为private
class Human {
private:
_name, _age, _gender
public:
ctor(n, a, g) {
this._name = n;
this._age = a;
this._gender = g;
}
getter name() { return this._name; }
getter age() { return this._age; }
getter gender() { return this._gender; }
glow() {
this._age += 1;
}
}
词法分析器
对于语言解释器,最基础的就是词法分析器了,没有这个,其他语法树构建啊都完不成。
那什么是词法分析器呢?
简单来说,词法分析器就是将语言的代码分割成一个又一个小的部分(我们称之为token),比如let a = 1 + 1;就可以分割成[keyword: let] [unknown: let] [operator: =] [number: 1] [operator: +] [number: 1] [operator: ;]这些部分。
所以,该这么写呢?观察就可以发现,当我们分隔的关键字标识这些由字母下划线组成的token时,其分隔符其实就是运算符或者空格;数字也同理,只不过是0-9.(考虑二进制八进制十六进制的话也就是算上b, o, x)组成的,至于符号的话,空格和非符号便是其分界。当然,括号是比较特殊的,比如(++i)就应该切成( ++ i )而不是(++ i )。
所以,我们就可以开始写词法分析器了,上代码
include/lex.h
#ifndef BERRYMATH_LEX_H
#define BERRYMATH_LEX_H
#include <string>
#include <map>
#include <regex>
#include "types.h"
using std::string;
using std::map;
namespace BM {
class Lexer {
public:
enum TOKENS {
NO_STATUS = 0,// 初始化状态
UNKNOWN_TOKEN,// 未知token
// key words
LET_TOKEN, DEF_TOKEN,
IF_TOKEN, ELIF_TOKEN, ELSE_TOKEN, SWITCH_TOKEN, CASE_TOKEN, DEFAULT_TOKEN,
FOR_TOKEN, WHILE_TOKEN, DO_TOKEN, CONTINUE_TOKEN, BREAK_TOKEN,
REFER_TOKEN,
RETURN_TOKEN,
ENUM_TOKEN,
USING_TOKEN,
PASS_TOKEN,
IMPORT_TOKEN, EXPORT_TOKEN, AS_TOKEN,
DELETE_TOKEN,
CLASS_TOKEN, PUBLIC_TOKEN, PRIVATE_TOKEN, NEW_TOKEN, STATIC_TOKEN, OPERATOR_TOKEN, EXTENDS_TOKEN,
NULL_TOKEN, UNDEFINED_TOKEN, DEBUGGER_TOKEN,
NUMBER_TOKEN, STRING_TOKEN,
// 注释token
NOTE_TOKEN,
// 符号token
UNKNOWN_OP_TOKEN,
SET_TOKEN, COLON_TOKEN,
EQUAL_TOKEN, NOT_EQUAL_TOKEN, LEQUAL_TOKEN, MEQUAL_TOKEN,
LESS_TOKEN, MORE_TOKEN,
BRACKETS_LEFT_TOKEN, BRACKETS_RIGHT_TOKEN,
MIDDLE_BRACKETS_LEFT_TOKEN, MIDDLE_BRACKETS_RIGHT_TOKEN,
BIG_BRACKETS_LEFT_TOKEN, BIG_BRACKETS_RIGHT_TOKEN,
DOT_TOKEN, COMMA_TOKEN,
MAND_TOKEN, MOR_TOKEN, MXOR_TOKEN, MNOT_TOKEN,
LAND_TOKEN, LOR_TOKEN, LNOT_TOKEN,
ADD_TOKEN, SUB_TOKEN, MUL_TOKEN, DIV_TOKEN, MOD_TOKEN, POWER_TOKEN,
SLEFT_TOKEN, SRIGHT_TOKEN,
ADD_TO_TOKEN, SUB_TO_TOKEN, MUL_TO_TOKEN, DIV_TO_TOKEN, MOD_TO_TOKEN, POWER_TO_TOKEN,
SLEFT_TO_TOKEN, SRIGHT_TO_TOKEN,
MAND_TO_TOKEN, MOR_TO_TOKEN, MXOR_TO_TOKEN,
DADD_TOKEN, DSUB_TOKEN,// double add & double sub
IN_TOKEN, OF_TOKEN,
RANGE_TOKEN,
END_TOKEN,// 语句结束
PROGRAM_END
};
struct Token {
TOKENS t;
string s;
};
Lexer() : script(""), i(0), l(0) {
script += ";pass";
}
Lexer(const string& s) : script(s), i(0), l(0) {
script += ";pass";
}
void open(const string& s) {
script = s;
i = 0;
l = 0;
updateLine = false;
script += ";pass";
}
Token get();
Token token() { return t; }
UL index() { return i; }
UL line() { return l; }
private:
bool updateLine = false;
UL i;
UL l;
UL sIndex = 0;
Token t;
string script;
friend class AST;
#define IS_SPACE(c) (c == '\t' || c == ' ' || c == '\n')
#define IS_OP(c) \
(!(c >= '0' && c <= '9') && !(c >= 'a' && c <= 'z') && !(c >= 'A' && c <= 'Z') && c != '_' && c != '$')
};
#define IS_NUM(c) (c >= '0' && c <= '9')
}
#endif //BERRYMATH_LEX_H
src/lex.cpp
#include <iostream>
#include "lex.h"
BM::Lexer::Token BM::Lexer::get() {
sIndex = i;
if (updateLine) {
l++;
updateLine = false;
}
if (i >= script.length()) {
t.s = "";
t.t = PROGRAM_END;
return t;
}
t.s = "";
t.t = NO_STATUS;
bool numberDot = false;
for (; i < script.length(); i++) {
if (IS_SPACE(script[i])) {
if (t.t) {// 已经有分割出来的token, 遇到空符就意味着语句的结束
i++;
if (script[i - 1] == '\n'/* && lastI < (i - 1)*/)
updateLine = true;
break;
}
if (script[i - 1] == '\n'/* && lastI < (i - 1)*/)
l++;
// 尚未有分割出来的token, 所以不做处理
continue;
} else if (IS_OP(script[i])) {
if (!t.s.empty() && (script[i] == '(' || script[i] == '[' || script[i] == '{')) {
break;
}
if (t.t >= UNKNOWN_TOKEN && t.t <
NOTE_TOKEN) {// 如果是是word token的话, 遇到符号就说明word token的结束, 但是数字如果遇到.除外, 因为这种情况是小数, 但是数字只有一个小数点, 所有当numberDot为true以后又有.就是分割界线了
if (script[i] == '.' && t.t == NUMBER_TOKEN && !numberDot) {
numberDot = true;
t.s += script[i];
continue;
} else break;
}
if (script[i] == '"' || script[i] == '\'') {
if (t.t != NO_STATUS) break;
auto s = script[i];
bool trans = false;// 转义'\'
t.s += script[i];
for (i++; i < script.length(); i++) {
t.s += script[i];
if (script[i] == s) {
if (!trans) {
i++;
break;
} else {
trans = !trans;
}
}
if (script[i] == '\\') trans = !trans;
else if (trans) trans = false;
}
t.t = STRING_TOKEN;
break;
}
if (script[i] == ';') {
if (t.t == NO_STATUS) t.s = ";";
break;
}
if (
script[i] == ')' || script[i] == ']' || script[i] == '}' ||
script[i] == '(' || script[i] == '[' || script[i] == '{') {
if (t.t == NO_STATUS) {
t.s = script[i];
t.t = UNKNOWN_OP_TOKEN;
i++;
}
break;
}
t.t = UNKNOWN_OP_TOKEN;
// if (t.t == NO_STATUS || (t.t > NOTE_TOKEN && t.t < END_TOKEN))
} else {
if (
t.t > NOTE_TOKEN && t.t < END_TOKEN
)
break;// 如果是符号token的话, 遇到非符号就说明该token结束了
if (IS_NUM(script[i]) && t.t != UNKNOWN_TOKEN) t.t = NUMBER_TOKEN;
else t.t = UNKNOWN_TOKEN;
}
t.s += script[i];
}
// 判断类型
// 运算符判断
if (t.s == ";") {
t.t = END_TOKEN;
i++;
} else if (t.s == "=") {
t.t = SET_TOKEN;
} else if (t.s == ":") {
t.t = COLON_TOKEN;
} else if (t.s == "==") {
t.t = EQUAL_TOKEN;
} else if (t.s == "!=") {
t.t = NOT_EQUAL_TOKEN;
} else if (t.s == "<=") {
t.t = LEQUAL_TOKEN;
} else if (t.s == ">=") {
t.t = MEQUAL_TOKEN;
} else if (t.s == "<") {
t.t = LESS_TOKEN;
} else if (t.s == ">") {
t.t = MORE_TOKEN;
} else if (t.s == "(") {
t.t = BRACKETS_LEFT_TOKEN;
} else if (t.s == ")") {
t.t = BRACKETS_RIGHT_TOKEN;
} else if (t.s == "[") {
t.t = MIDDLE_BRACKETS_LEFT_TOKEN;
} else if (t.s == "]") {
t.t = MIDDLE_BRACKETS_RIGHT_TOKEN;
} else if (t.s == "{") {
t.t = BIG_BRACKETS_LEFT_TOKEN;
} else if (t.s == "}") {
t.t = BIG_BRACKETS_RIGHT_TOKEN;
} else if (t.s == ".") {
t.t = DOT_TOKEN;
} else if (t.s == ",") {
t.t = COMMA_TOKEN;
} else if (t.s == "&") {
t.t = MAND_TOKEN;
} else if (t.s == "|") {
t.t = MOR_TOKEN;
} else if (t.s == "^") {
t.t = MXOR_TOKEN;
} else if (t.s == "~") {
t.t = MNOT_TOKEN;
} else if (t.s == "&&") {
t.t = LAND_TOKEN;
} else if (t.s == "||") {
t.t = LOR_TOKEN;
} else if (t.s == "!") {
t.t = LNOT_TOKEN;
} else if (t.s == "+") {
t.t = ADD_TOKEN;
} else if (t.s == "-") {
t.t = SUB_TOKEN;
} else if (t.s == "*") {
t.t = MUL_TOKEN;
} else if (t.s == "/") {
t.t = DIV_TOKEN;
} else if (t.s == "%") {
t.t = MOD_TOKEN;
} else if (t.s == "**") {
t.t = POWER_TOKEN;
} else if (t.s == "<<") {
t.t = SLEFT_TOKEN;
} else if (t.s == ">>") {
t.t = SRIGHT_TOKEN;
} else if (t.s == "+=") {
t.t = ADD_TO_TOKEN;
} else if (t.s == "-=") {
t.t = SUB_TO_TOKEN;
} else if (t.s == "*=") {
t.t = MUL_TO_TOKEN;
} else if (t.s == "/=") {
t.t = DIV_TO_TOKEN;
} else if (t.s == "%=") {
t.t = MOD_TO_TOKEN;
} else if (t.s == "**=") {
t.t = POWER_TO_TOKEN;
} else if (t.s == "<<=") {
t.t = SLEFT_TO_TOKEN;
} else if (t.s == ">>=") {
t.t = SRIGHT_TO_TOKEN;
} else if (t.s == "&=") {
t.t = MAND_TO_TOKEN;
} else if (t.s == "|=") {
t.t = MOR_TO_TOKEN;
} else if (t.s == "^=") {
t.t = MXOR_TO_TOKEN;
} else if (t.s == "++") {
t.t = DADD_TOKEN;
} else if (t.s == "--") {
t.t = DSUB_TOKEN;
} else if (t.s == "~~") {
t.t = RANGE_TOKEN;
}
// 特判
else if (t.s[0] == '0' && t.t != NUMBER_TOKEN && t.s.length() > 2) {
t.t = NUMBER_TOKEN;
string s(t.s);
char* endp;
s.erase(0, 2);
switch (t.s[1]) {
case 'x':
t.s = std::to_string(strtol(s.c_str(), &endp, 16));
break;
case 'b':
t.s = std::to_string(strtol(s.c_str(), &endp, 2));
break;
case 'o':
t.s = std::to_string(strtol(s.c_str(), &endp, 8));
break;
}
}
// key word token判断
else if (t.s == "let") {
t.t = LET_TOKEN;
} else if (t.s == "def") {
t.t = DEF_TOKEN;
} else if (t.s == "if") {
t.t = IF_TOKEN;
} else if (t.s == "elif") {
t.t = ELIF_TOKEN;
} else if (t.s == "else") {
t.t = ELSE_TOKEN;
} else if (t.s == "switch") {
t.t = SWITCH_TOKEN;
} else if (t.s == "case") {
t.t = CASE_TOKEN;
} else if (t.s == "for") {
t.t = FOR_TOKEN;
} else if (t.s == "while") {
t.t = WHILE_TOKEN;
} else if (t.s == "do") {
t.t = DO_TOKEN;
} else if (t.s == "continue") {
t.t = CONTINUE_TOKEN;
} else if (t.s == "break") {
t.t = BREAK_TOKEN;
} else if (t.s == "refer") {
t.t = REFER_TOKEN;
} else if (t.s == "return") {
t.t = RETURN_TOKEN;
} else if (t.s == "in") {
t.t = IN_TOKEN;
} else if (t.s == "of") {
t.t = OF_TOKEN;
} else if (t.s == "null") {
t.t = NULL_TOKEN;
} else if (t.s == "undefined") {
t.t = UNDEFINED_TOKEN;
} else if (t.s == "enum") {
t.t = ENUM_TOKEN;
} else if (t.s == "using") {
t.t = USING_TOKEN;
} else if (t.s == "default") {
t.t = DEFAULT_TOKEN;
} else if (t.s == "class") {
t.t = CLASS_TOKEN;
} else if (t.s == "public") {
t.t = PUBLIC_TOKEN;
} else if (t.s == "private") {
t.t = PRIVATE_TOKEN;
} else if (t.s == "operator") {
t.t = OPERATOR_TOKEN;
} else if (t.s == "extends") {
t.t = EXTENDS_TOKEN;
} else if (t.s == "new") {
t.t = NEW_TOKEN;
} else if (t.s == "static") {
t.t = STATIC_TOKEN;
} else if (t.s == "import") {
t.t = IMPORT_TOKEN;
} else if (t.s == "export") {
t.t = EXPORT_TOKEN;
} else if (t.s == "as") {
t.t = AS_TOKEN;
} else if (t.s == "debugger") {
t.t = DEBUGGER_TOKEN;
} else if (t.s == "delete") {
t.t = DELETE_TOKEN;
} else if (t.s == "//") {
t.t = NOTE_TOKEN;
while (true) {
if (script[++i] == '\n') break;
}
} else if (t.s == "/*") {
t.t = NOTE_TOKEN;
t.s = "/*";
while (true) {
if (script[i] == '*' && script[i + 1] == '/') break;
t.s += script[i];
i++;
}
i += 2;
} else if (t.s == "pass") {
t.t = PASS_TOKEN;
}
if (t.t == NOTE_TOKEN) return get();
return t;
}
[未完待续]
共同学习,写下你的评论
评论加载中...
作者其他优质文章


