
知识点
- Redis Sentinel是Redis的高可用实现方案:故障发现、故障自动转移、配置中心、客户端通知。
- Redis Sentinel中的数据节点与普通数据节点没有区别。
- Redis Sentinel从Redis2.8版本开始才正式生产可用,之前版本生产不可用。
- Redis Sentinel中的Sentinel节点个数应该为大于等于3且最好为奇数。
- 尽可能在不同物理机上部署Redis Sentinel所有节点。
- 客户端初始化时连接的是Sentinel节点集合,不再是具体的Redis节点,但Sentinel只是配置中心不是代理。
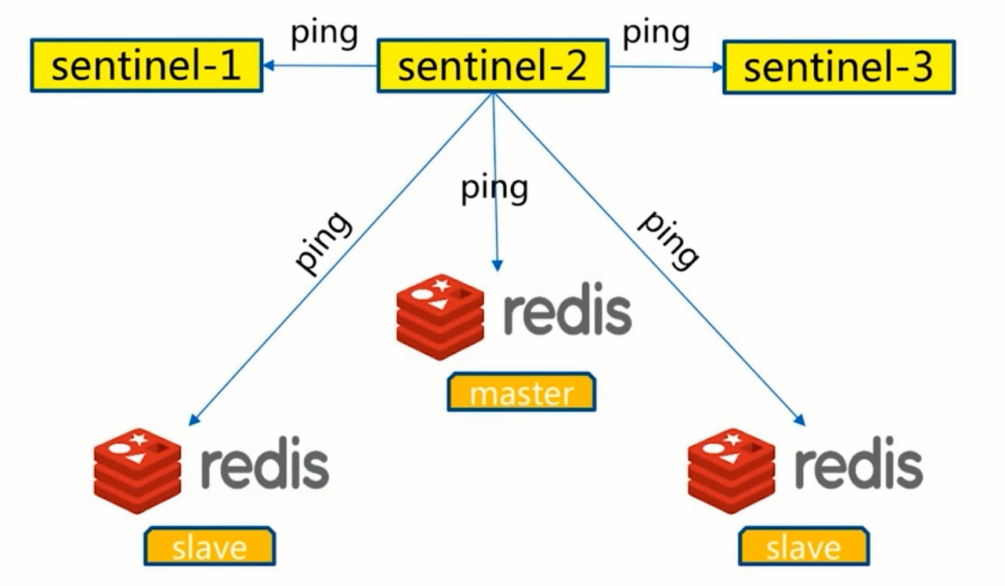
- Redis Sentinel通过三个定时任务实现了Sentinel节点对于主节点、从节点,其余Sentinel节点的监控。
- Redis Sentinel在对节点做失败判定时分为主观下线和客观下线。
- 看懂Redis Sentinel故障转移日志对于Redis Sentinel以及问题排查非常有帮助
- Redis Sentinel实现读写分离高可用可以依赖Sentinel节点的消息通知,获取Redis数据节点的状态变化
常见问题
fork(内存页的拷贝)
- 同步操作
- 与内存量息息相关:内存越大,耗时越长(与机器类型有关)
- info:latest_fork_usec (上一次执行fork的微秒数)
改善fork
- 优先使用物理机或者高效支持fork操作的虚拟化技术
- 控制Redis实例最大可用内存:maxmemory
- 合理配置Linux内存分配策略:vm.overcommit_memory=1
- 降低fork频率:例如放宽AOF重写自动触发时机,不必要的全量复制
子进程开销和优化
- 1.CPU:
- 开销:RDB和AOF文件生成,属于CPU密集型
- 优化:不做CPU绑定,不和CPU密集型部署
- 2.内存
- 开销:fork内存开销,copy-on-write。
- 不允许单机做部署的时候大量产生重写。在主进程写入量比较小的时候,进行重写
- 优化:echo never > /sys/kernel/mm/transparer 减少内存片
- 开销:fork内存开销,copy-on-write。
- 3.硬盘
- 开销:AOF和RDB文件写入,可以结合iostat,iotop分析
- 1.不要和高硬盘负载服务部署一起:存储服务、消息队列等
- 2.no-appendfsync-on-rewrite=yes
- 3.根据写入量决定磁盘类型:例如ssd
- 4.单机多实例持久化文件目录可以考虑分盘
- 开销:AOF和RDB文件写入,可以结合iostat,iotop分析
Aof追加阻塞(刷盘策略)
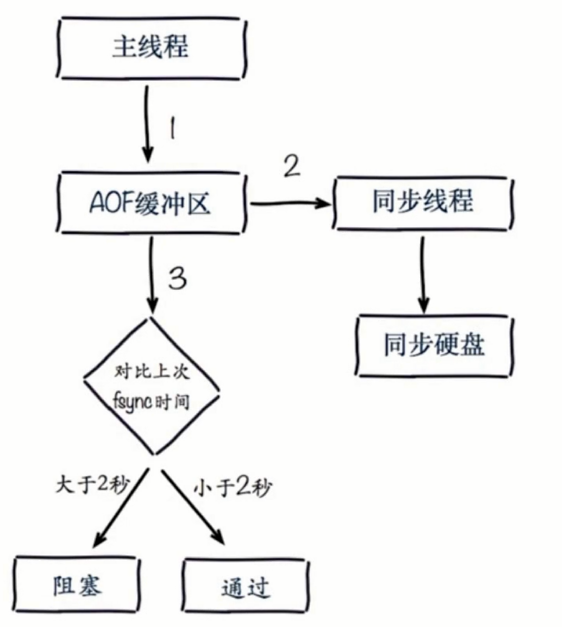
AOF阻塞定位

Redis复制
- 为数据提供副本,扩展读性能
- 单机问题
- 机器故障(高可用)
- 容量瓶颈
- QPS瓶颈
- 一个master可以有多个slave
- 一个slave只能有一个master
- 数据流向是单向的,master到slave
configuration


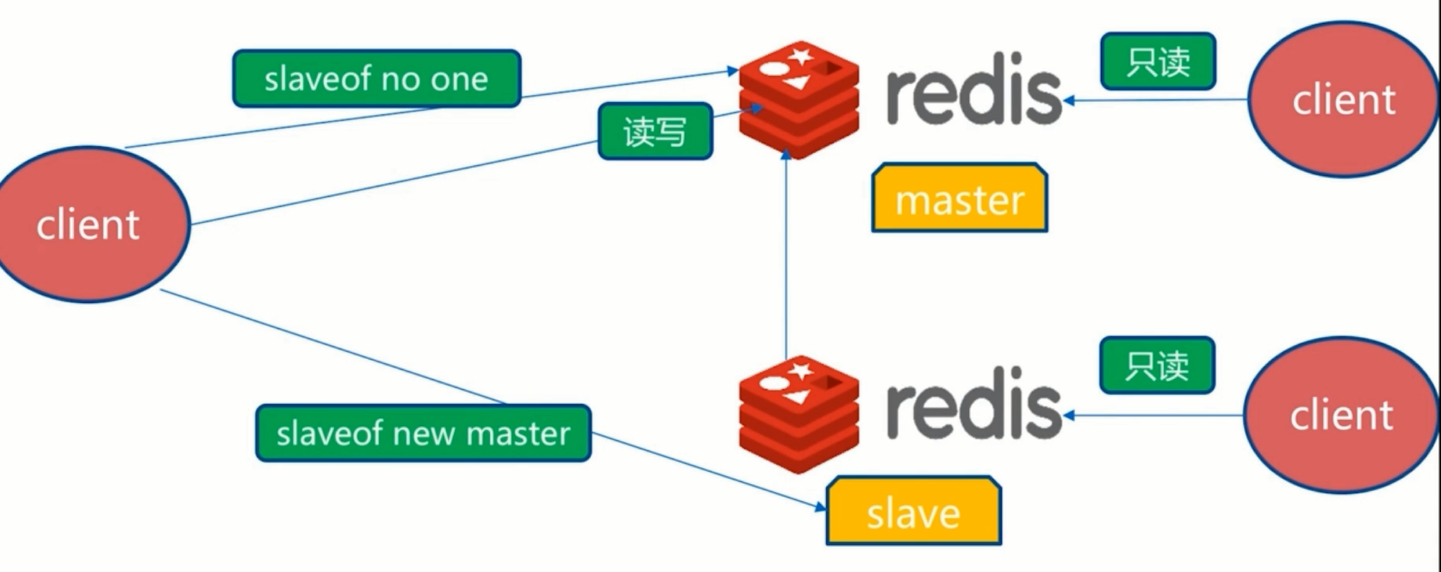
slaveof ip port
slave-read-only yes
| 方式 | 命令 | 配置 |
|---|---|---|
| 优点 | 无需重启 | 统一配置 |
| 缺点 | 不便于管理 | 需要重启 |
主机:
conf:
守护进程
daemonize yes
pidfile /var/run/redis-6379.pid
logfile '6379.log'
关掉 save 300 1 等三个检测配置
dbfilename dump-6379.rdb
dir /opt/soft/data
从机:
slave-read-only yes
dbfilename dump-6380.rdb
slaveof 127.0.0.1 6379
分别启动
我们可以使用redis-cli info replication 来检查主从情况
run id
- run id是一个唯一标识,重启之后消失
redis-cli info server | grep run- 如果id发生变化,从就会把主的数据全部复制过来,也就是全量复制
- 偏移量如果相差过多,可能说明主从复制有问题
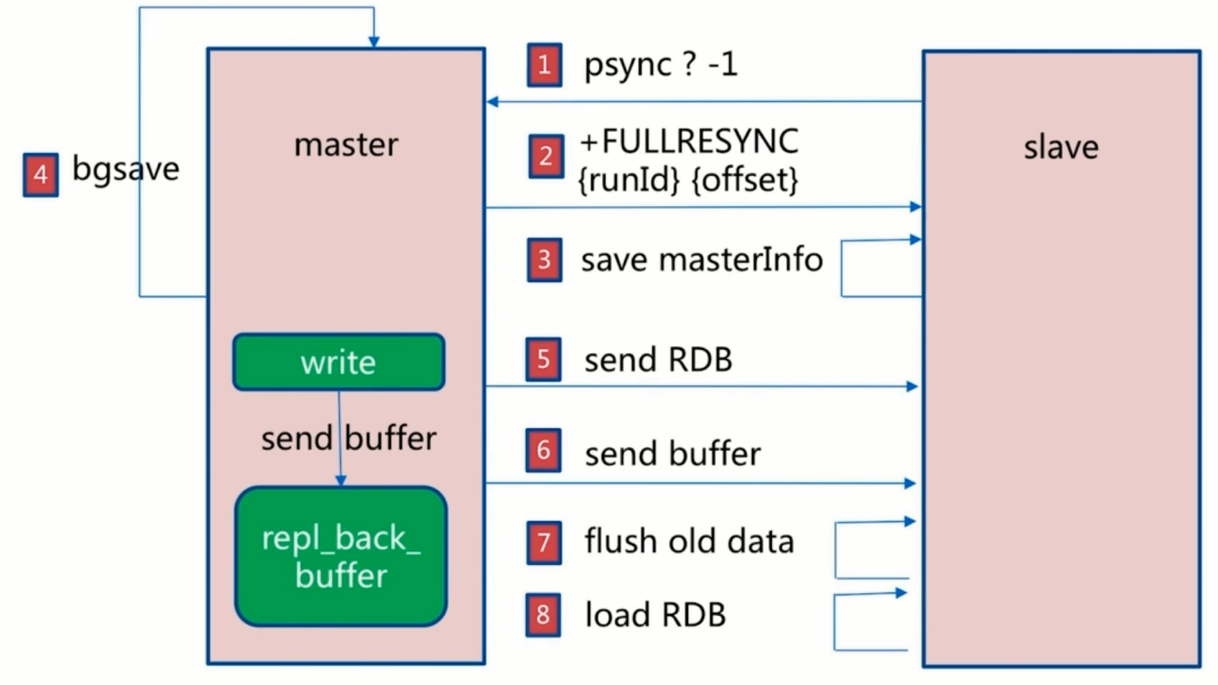
全量复制
- 开销过大(时间)
- bgsave
- RDB文件网络传输
- 从节点清空数据
- 从节点加载RDB
- 可能的AOF重写
部分复制
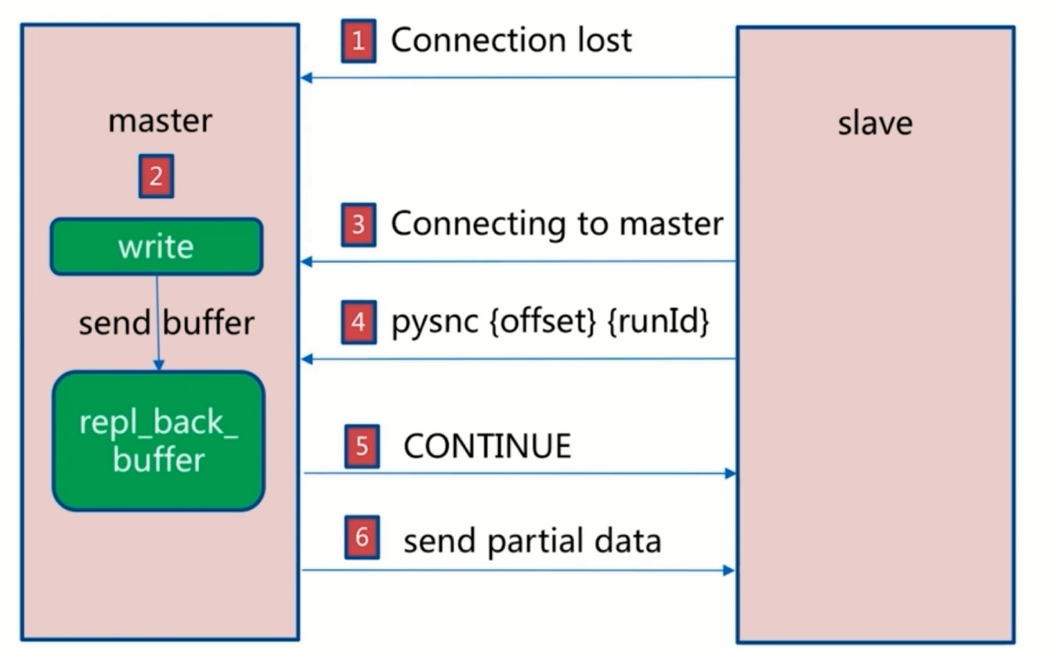
slave宕机和master宕机(how to automate?)
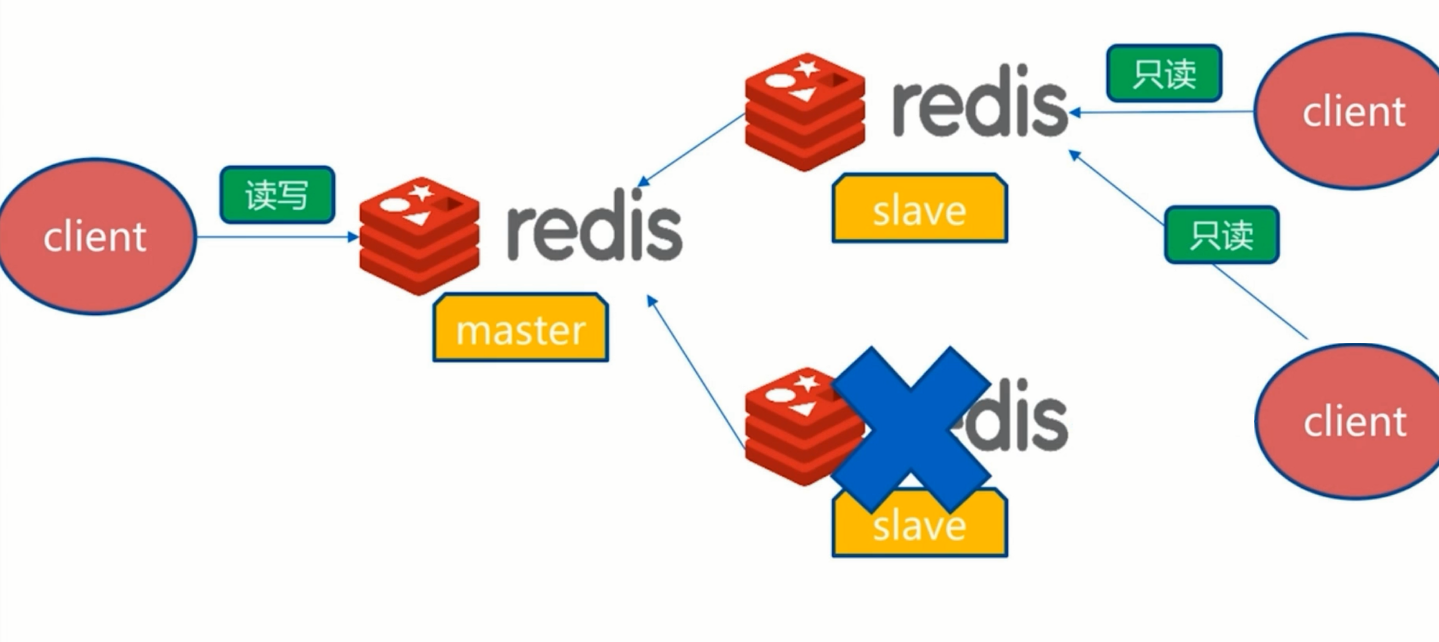
主从复制遇到的问题
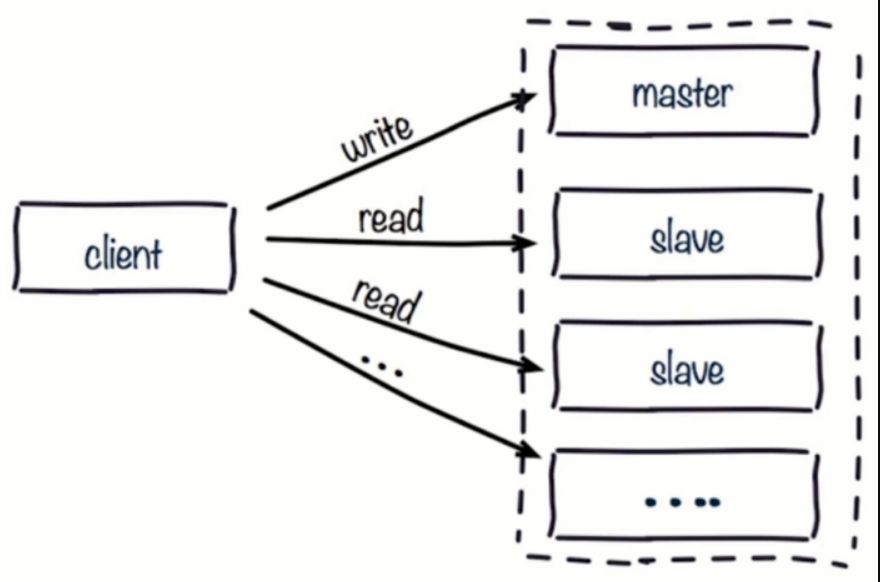
- 1.读写分离:读流量分摊到从节点。
- 2.可能遇到问题:
- 复制数据延迟
- 读到过期数据,从节点无法删除
- 从节点故障留

高可用
- 配置不一致
- 1.例如maxmemory不一致:丢失数据
- 2.例如数据结构优化参数(例如hash-max-ziplist-entries):内存不一致
规避全量复制
- 1.第一次全量复制
- 第一次不可避免
- 小主节点、低峰
- maxmemory设置小一些(传输的时候压力小一些),然后夜间处理
- 2.节点运行ID不匹配
- 主节点重启(运行ID变化)
- 故障转移,例如哨兵或集群
- 3.复制积压缓冲区不足
- 网络中断,部分复制无法满足
- 增大复制缓冲区配置rel_backlog_size,网络“增强"。
- 设置大一些,可以有效的防止全量复制
复制风暴
当主节点宕机重启之后,所有的从节点都要进行一次全量复制
当然,高可用(从当主)也可以解决这个问题
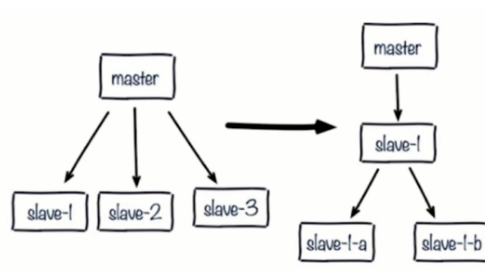
- 1.单主节点复制风暴:
- 问题:主节点重启,多从节点复制
- 解决:更换复制拓扑
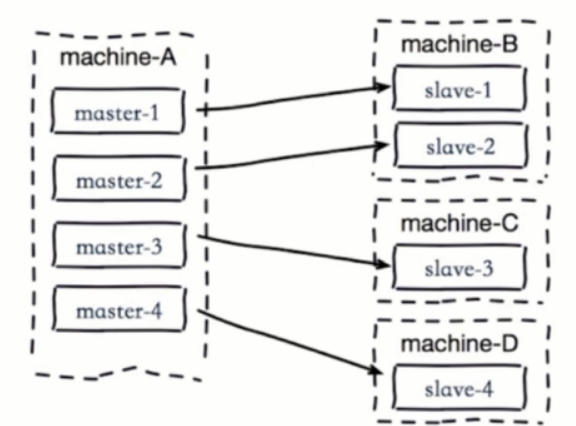
- 2.单机器复制风暴
- 如下图:机器宕机后,大量全量复制
- 主节点分散多机器
主从复制的问题
- 手动故障转移
- 写能力和存储能力受到限制
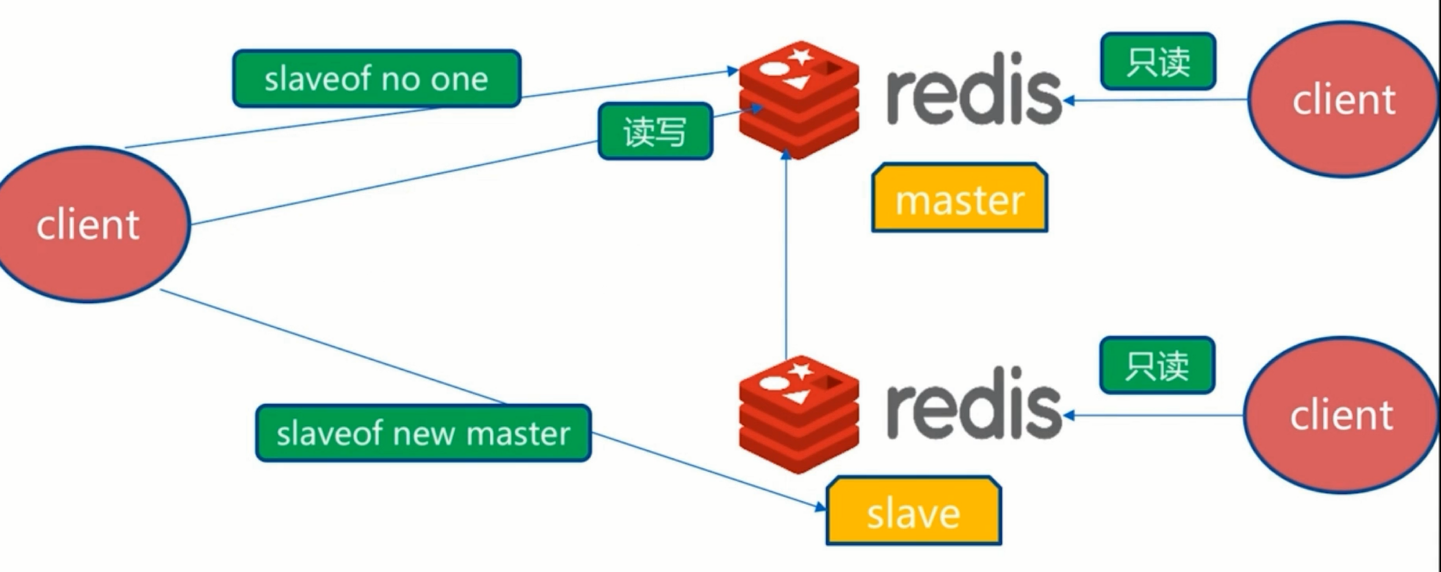
生命周期
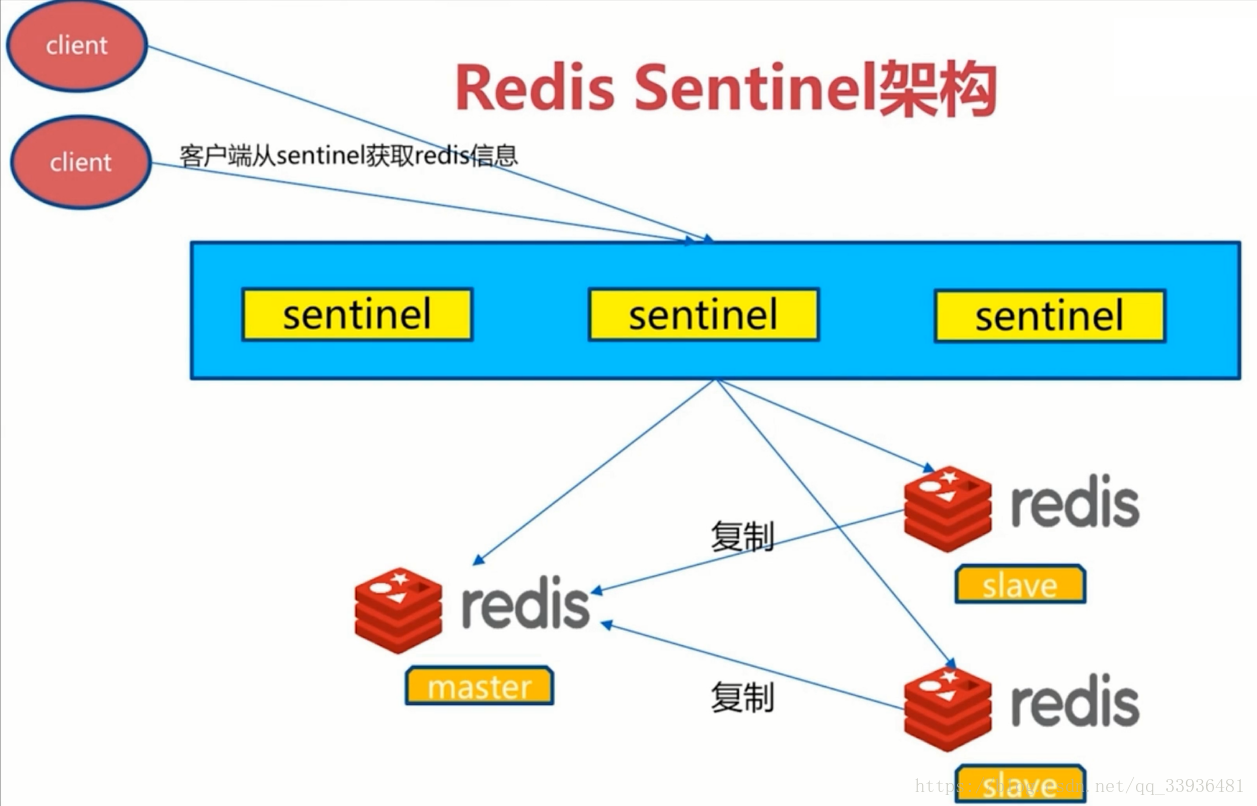
Redis Sentine 架构
sentine对redis进行故障判断,故障转移,通知客户端
可以监控多套redis主从架构,通过master-name作为标识
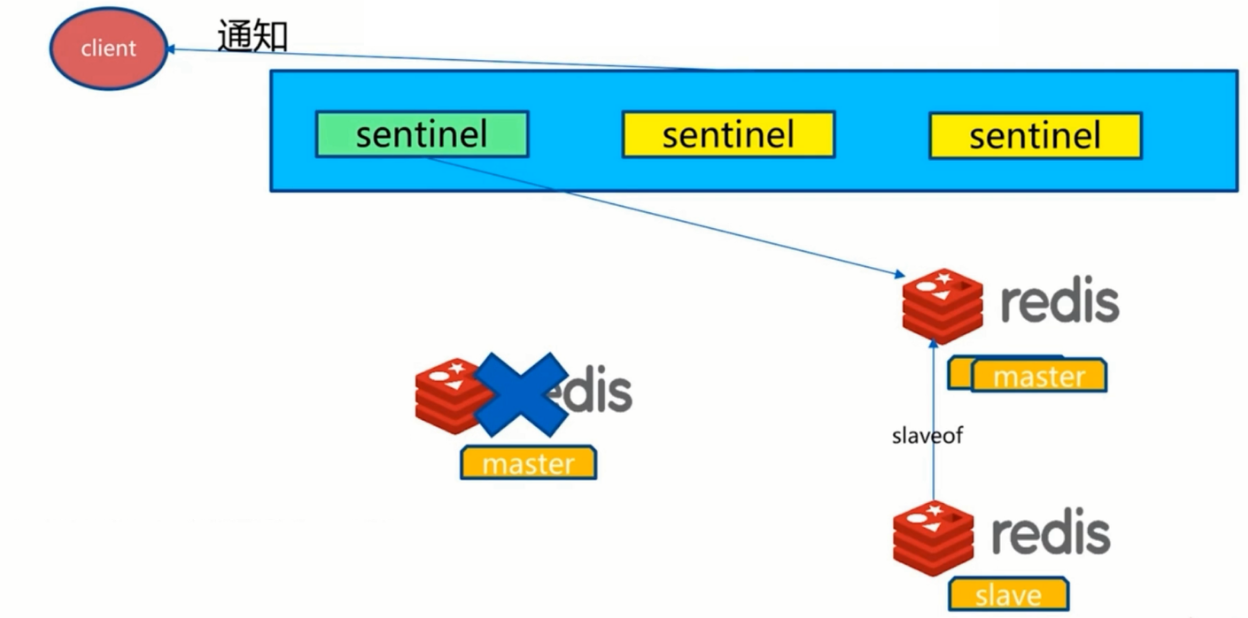
- 1.多个sentinel发现并确认master有问题。
- 2.选举出一个sentinel作为领导。
- 3.选出一个slave作为master。
- 4.通知其余slave成为新的master的slave。
- 5.通知客户端主从变化
- 6.等待老的master复活成为新master的slave。
安装配置
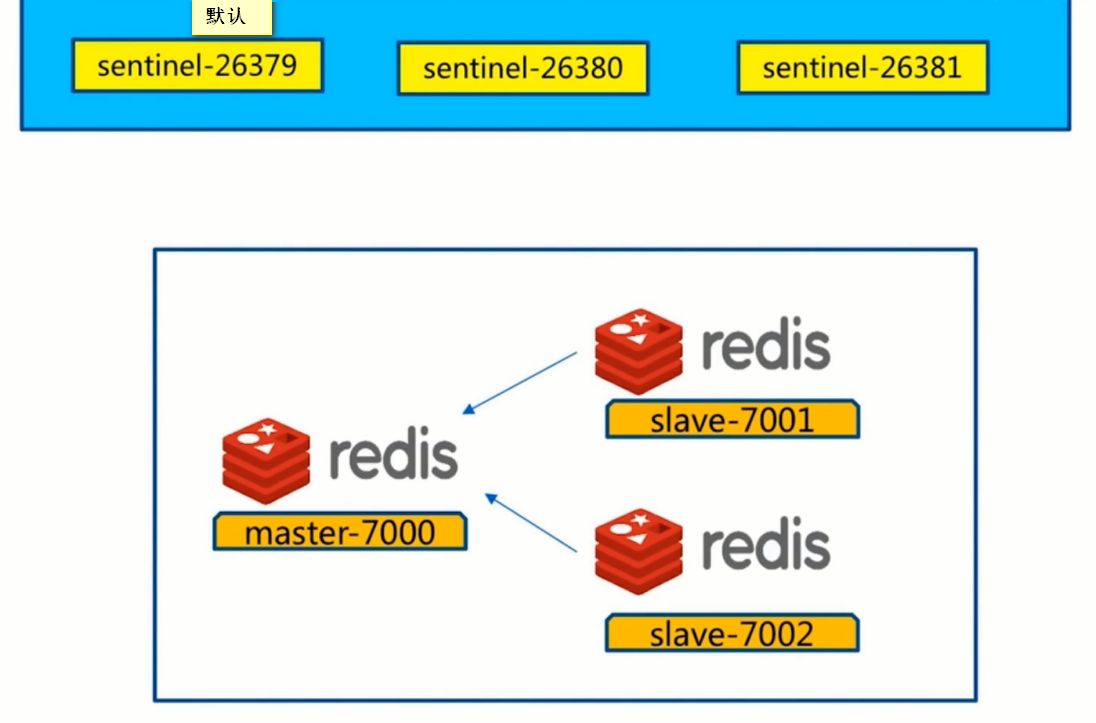
Redis主节点

Redis从节点
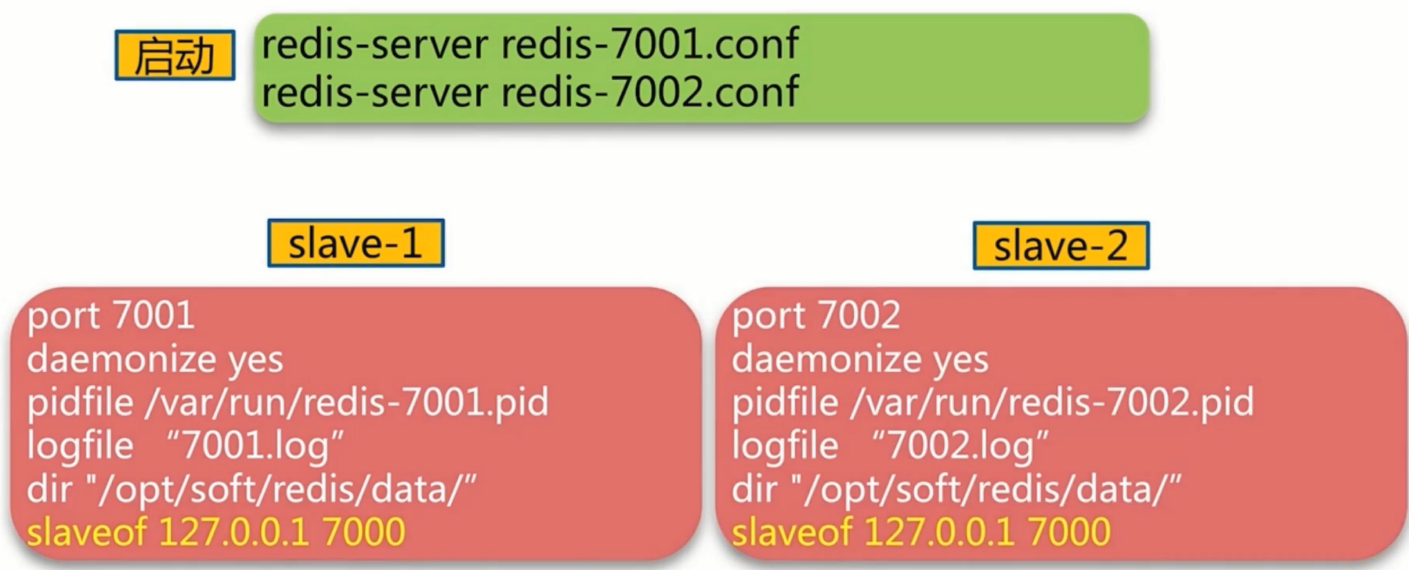
sentinel配置
port ${port}
dir "/opt/soft/redis/data/"
logfile "$(port}.log"
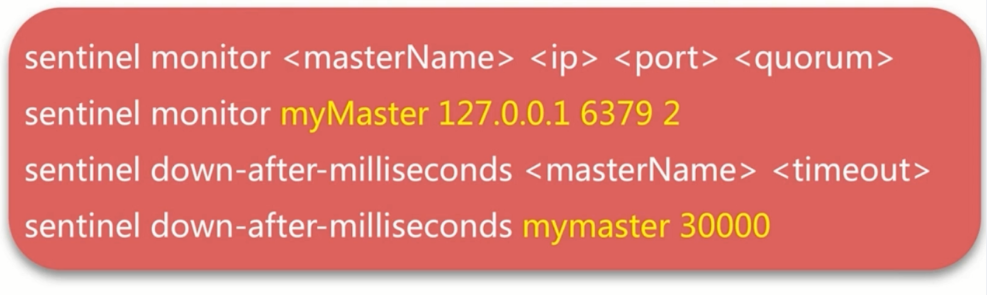
sentinel monitor mymaster 127.0.0.170002
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
- 2表示两台sentinel对redis master 进行监控,故障发现
- 30000毫秒如果无反应,则判断成功
- 转移时间 failover-timeout
[root@localhost ~]# redis-server redis-conf
[root@localhost ~]# redis-cli -p 7000 ping
PONG
[root@localhost ~]# redis-server redis-7001-conf
[root@localhost ~]# redis-server redis-7002-conf
[root@localhost ~]# ps -ef | grep redis-server | grep 700
root 6646 1 0 11:51 ? 00:00:00 redis-server *:7000
root 6673 1 0 11:54 ? 00:00:00 redis-server *:7001
root 6678 1 0 11:54 ? 00:00:00 redis-server *:7002
[root@localhost ~]# redis-cli -p 7000 info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=7001,state=online,offset=85,lag=0
slave1:ip=127.0.0.1,port=7002,state=online,offset=85,lag=0
master_repl_offset:99
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:98
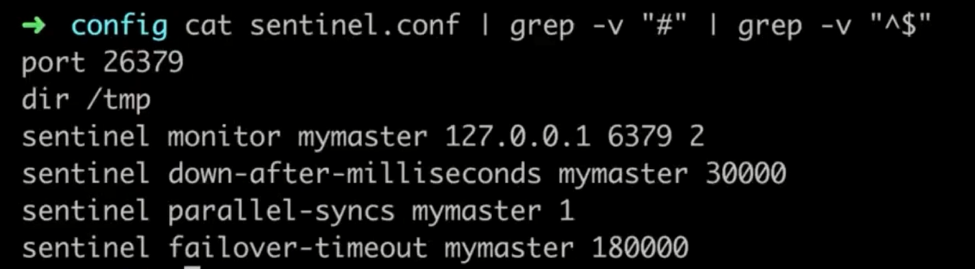
redis-sentinel redis-sentinel-26379(配置文件)
redis-cli -p 26379
故障转移演练(客户端)
- 客户端高可用观察
- 服务端日志分析: 数据节点和sentinel节点
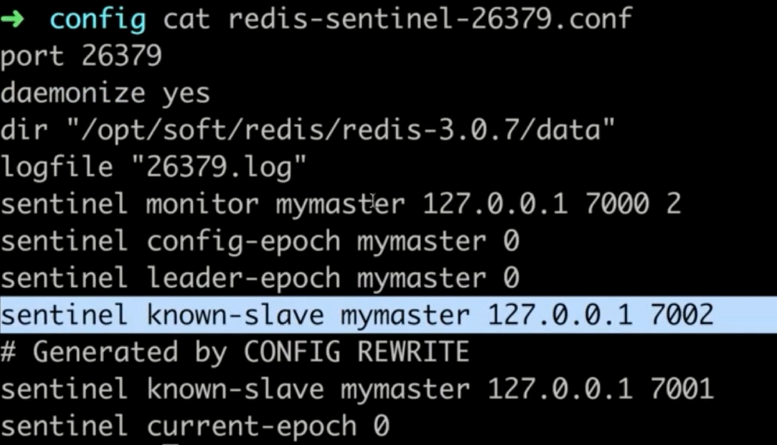

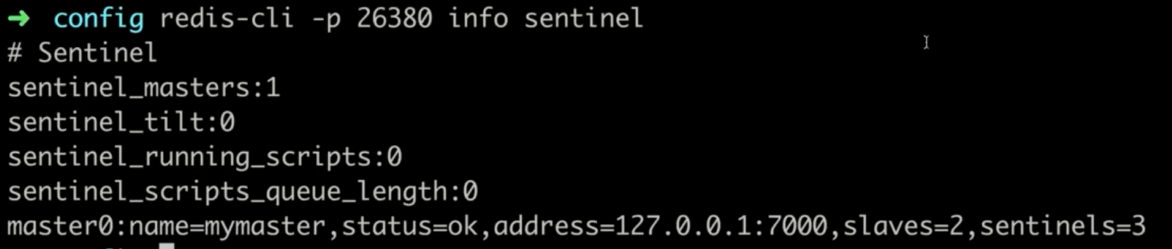
客户端高可用
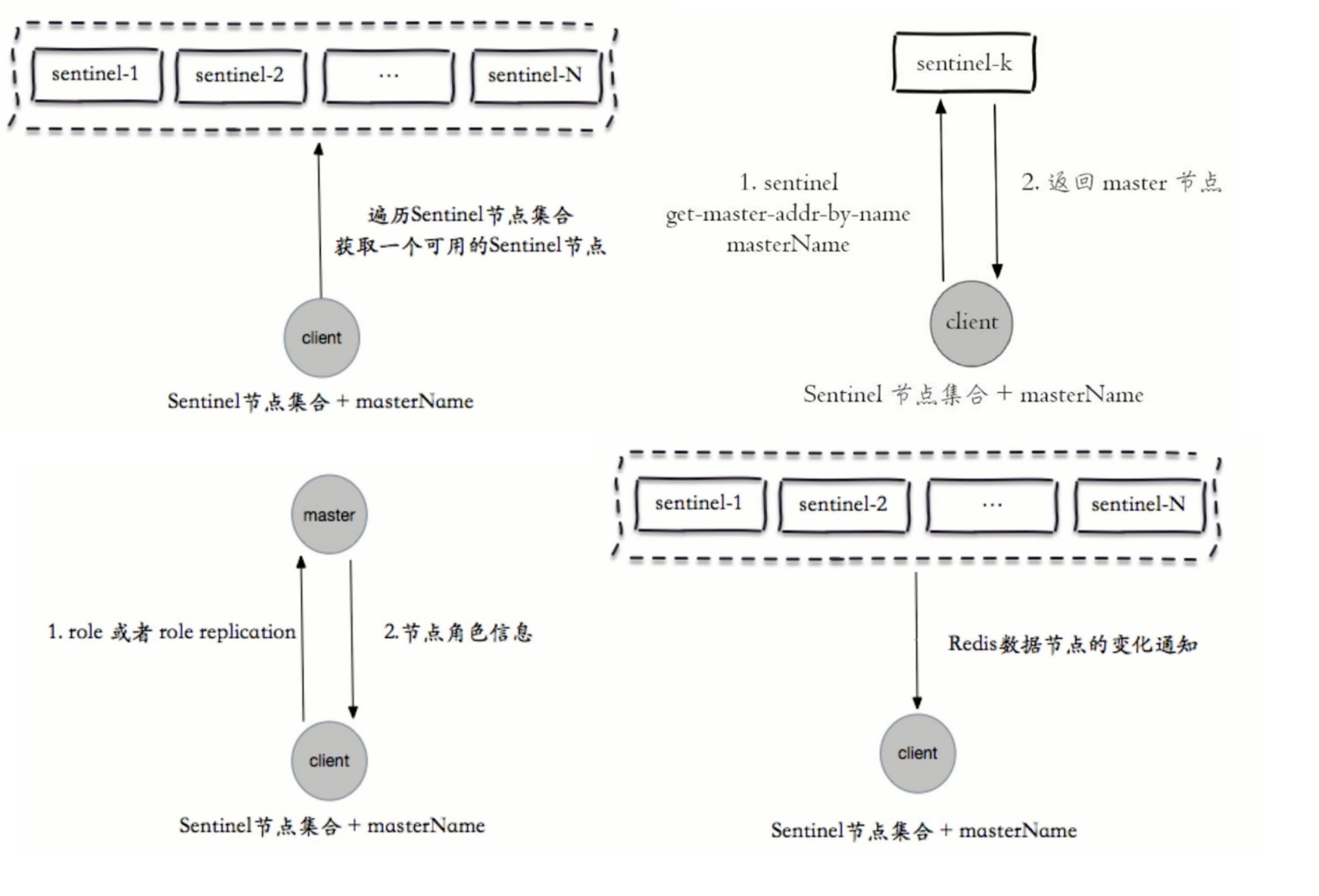
客户端接入流程
- Sentinel地址集合
- masterName
- 不是代理模式(只获取一次masterName,如果master没有变化之前)
java

py

故障转移
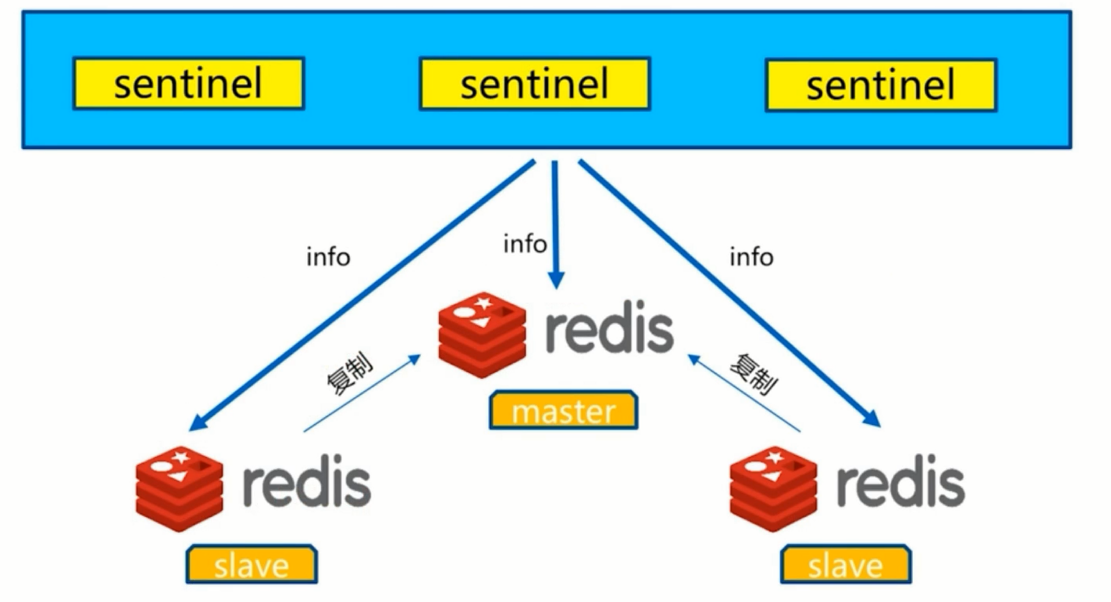
三个定时任务
- 1.每10秒每个sentinel对master和slave执行info
- 发现slave节点
- 确认主从关系
- 2.每2秒每个sentinel通过master节点的channel交换信息(pub/sub)
- 通过_sentinel_:hello频道交互
- 交互对节点的“看法”和自身信息
- 3.每1秒每个sentinel对其他sentinel和redis执行ping
- 心跳检测,失败判定依据
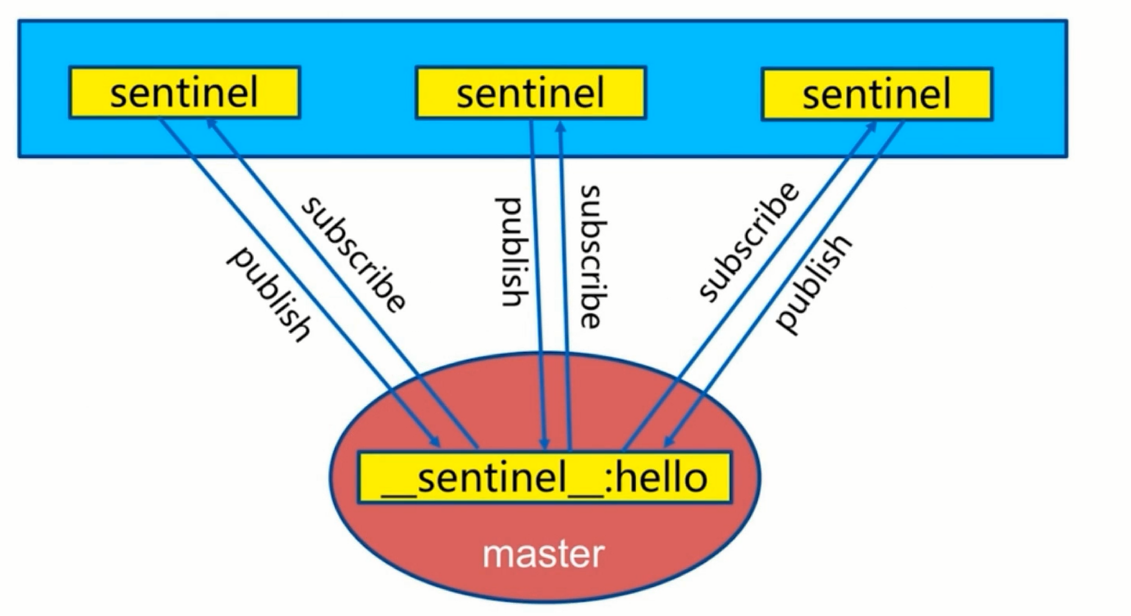
主观下线和客观下线
- quorum 法定人数,判定是否客观下线,最好是奇数,sentinel个数%2+1
- 主观下线:每个sentinel节点对Redis节点失败的“偏见"
- 客观下线:所有sentinel节点对Redis节点失败“达成共识"(超过quorum个统一)
- sentinel is-master-down-by-addr
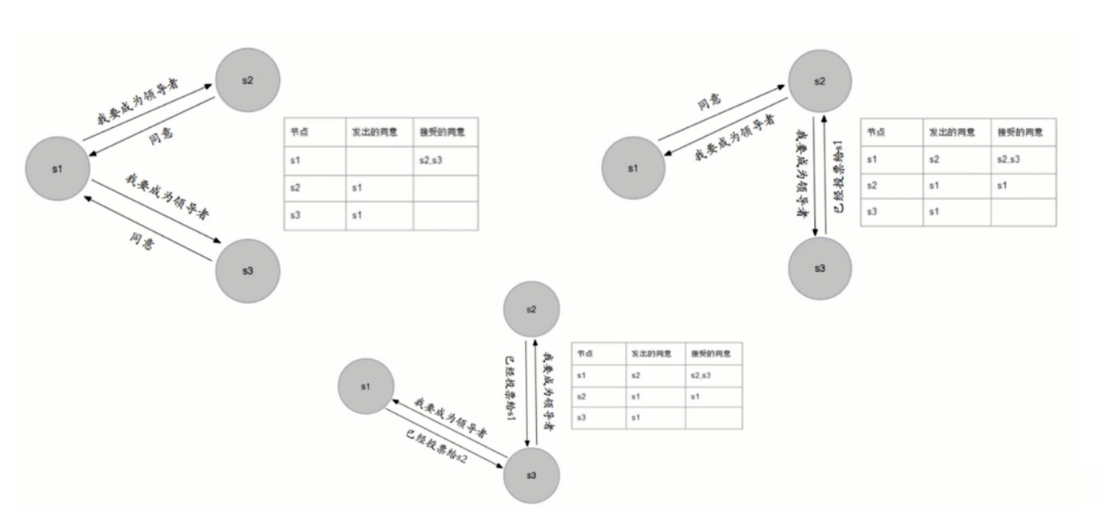
领导者选举
- 原因:只有一个sentinel节点完成故障转移
- 选举:通过sentinel is-master-down-by-addr命令都希望成为领导者
- 每个做主观下线的Sentinel节点向其他Sentinel节点发送命令,要求将它设置为领导者。
- 收到命令的Sentinel节点如果没有同意通过其他Sentinel节点发送的命令,那么将同意该请求,否则拒绝
- 如果该Sentinel节点发现自己的票数已经超过Sentinel集合半数且超过quorum,那么它将成为领导者。
- 如果此过程有多个Sentinel节点成为了领导者,那么将等待一段时间重新进行选举。
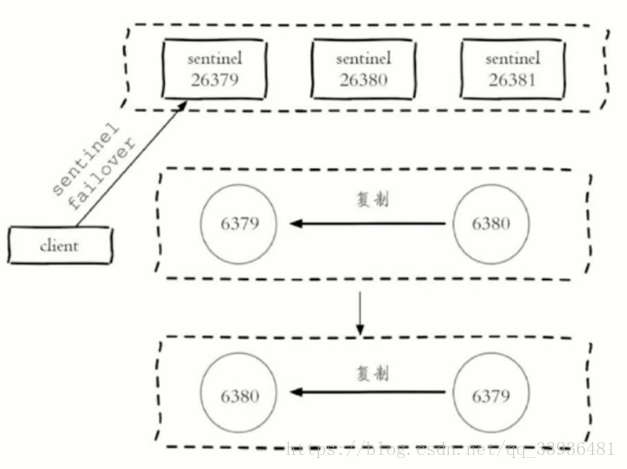
故障转移(sentinel领导者节点完成)
- 1.从slave节点中选出一个“合适的"节点作为新的master节点
- 2.对上面的slave节点执行slaveof no one命令让其成为master节点。
- 3.向剩余的slave节点发送命令,让它们成为新master节点的slave节点,复制规则和parallel-syncs参数有关。
- 4.更新对原来master节点配置为slave,并保持着对其“关注",当其恢复后命令它去复制新的master节点。
选择最好的slave节点
- 1 选择slave-priority(slave节点优先级)最高的slave节点,如果存在则返回,不存在则继续。
- 2 选择复制偏移量最大的slave节点(复制的最完整),如果存在则返回,不存在则
- 3 选择runId最小的slave节点。
节点运维问题
- 节点上线和下线
- 主节点
- 从节点
- Sentinel节点
- 机器下线:例如过保等情况
- 机器性能不足:例如CPU、内存、硬盘、网络等
- 节点自身故障:例如服务不稳定等
主节点下线
手动故障转移,忽略主观下线和客观下线和领导者选举,只有故障转移的过程
sentinel failover masterName
- 从节点:临时下线还是永久下线,例如是否做一些清理工作。但是要考虑读写分离的情况。
- Sentinel节点:同上
sentinel上线
- 主节点:sentinel failover进行替换。
- 从节点:slaveof即可,sentinel节点可以感知。
- sentinel节点:参考其他sentinel节点启动即可。
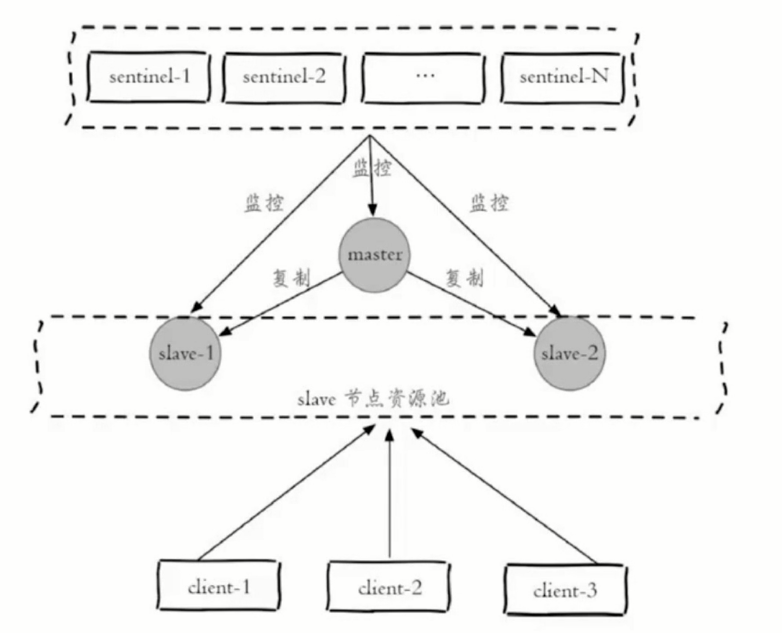
高可用读写分离
从节点的作用
- 副本:高可用的基础
- 扩展:读能力
- sentinel不会对master进行故障转移,只会做一个下线的判断
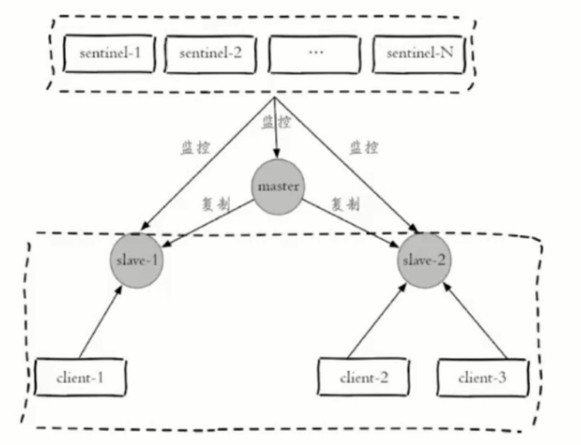
客户端
- 对slave做一个资源池
- 自定义客户端,监控如下的可能的变化
- +switch-master:切换主节点(从节点晋升主节点)
- +convert-to-slave:切换从节点(原主节点降为从节点)
- +sdown:主观下线。
点击查看更多内容
1人点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中



感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦