
完整代码如下:
特征X结构:X1_class/X1_num
import os
import pandas as pd
import numpy as np
def train_data_reads(path):
data_directory = path + "/data"
#获取数据路径
data_name_list = os.listdir(data_directory)
file_name = data_name_list[0]
#数据的路径:data_path
data_path = data_directory + "/" + file_name
name,extension = file_name.split(".")
if extension == "csv":
try:
data = pd.read_csv(data_path,encoding = "gbk")
except:
data = pd.read_csv(data_path,encoding = "utf-8")
elif extension == "txt":
try:
data = pd.read_csv(data_path,encoding = "gbk",sep = "\t")
except:
data = pd.read_csv(data_path,encoding = "utf-8",sep = "\t")
else:
data = pd.read_excel(data_path)
return data
def train_data_reprocess(data):
#剔除重复值
data = data.drop_duplicates()
data = data.reset_index(drop = True)
return data
def feature_label_split(data):
#获取dataFrame的名
name_list = data.columns.values.tolist()
label_name = name_list[len(name_list) - 1]
#将数据中label为空的数据删除
data = data[np.isnan(data[label_name]) == False]
#拆分特征与标签
x = data.drop(["ID",label_name],axis = 1)
y = data[label_name]
#补全特征中的缺失值
feature_name_list = x.columns.values.tolist()
class_name_list = [name for name in feature_name_list if name.find("class") > 0]
num_name_list = [name for name in feature_name_list if name.find("num") > 0]
class_filled_df = x[class_name_list].fillna("missing")
num_filled_df = x[num_name_list].fillna(data.mean())
new_x = pd.concat([class_filled_df,num_filled_df],axis = 1)
return new_x,y
#将分类特征转换成哑变量
def dummy_variable_transform(x):
#获取feature的列名
columns_name = x.columns.values.tolist()
for feature_name in columns_name:
feature_name_split = feature_name.split("_", 1)
name = feature_name_split[0]
feature_type = feature_name_split[1]
if feature_type == 'class':
dummy_class = pd.get_dummies(x[feature_name], prefix=name, drop_first=True)
x = x.drop(feature_name, axis=1).join(dummy_class)
return x
#对数据集X进行归一化
#线性回归对最大值,最小值敏感,思考一下,标准化Or归一化哪个更好
def data_MinMax(x):
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range = (0,1))
scaler.fit(x)
data = scaler.transform(x)
return data
def data_MinMax2(x):
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range = (-1,1))
scaler.fit(x)
data = scaler.transform(x)
return data
#为数据增加特征:多项式回归用的
def poly_data(x1):
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree = 2)
poly.fit(x1)
x2 = poly.transform(x1)
return x2
#划分训练集和测试集
def train_test_div(x,y,percent):
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size = percent)
return x_train,x_test,y_train,y_test
#train_test_split:先打乱顺序,然后进行分割
#1.线性回归预测
def lin_predict(x_train,x_test,y_train,y_test):
from sklearn import linear_model
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error,r2_score
linreg = LinearRegression()
linreg.fit(x_train,y_train)
y_pred = linreg.predict(x_test)
y_pred = list(map(lambda x: x if x >= 0 else 0,y_pred))
#y小于0时,赋值为0
y_pred = list(map(lambda x: x if x <= 10 else 10,y_pred))
#y大于10时,赋值为10
MAE = np.sum(np.absolute(y_pred - y_test)) / len(y_test)
return MAE
#2.决策树预测
#决策树不需要变量变为哑变量
def tree_predict(x_train,x_test,y_train,y_test):
from sklearn.tree import DecisionTreeRegressor
reg = DecisionTreeRegressor(max_depth = 100,min_samples_split = 50,min_samples_leaf = 50)
reg.fit(x_train,y_train)
y_pred = reg.predict(x_test)
y_pred = list(map(lambda x: x if x >= 0 else 0,y_pred))
#y小于0时,赋值为0
y_pred = list(map(lambda x: x if x <= 10 else 10,y_pred))
#y大于10时,赋值为10
MAE = np.sum(np.absolute(y_pred - y_test)) / len(y_test)
return MAE
def rf_predict(x_train,x_test,y_train,y_test):
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor()
rf.fit(x_train,y_train)
y_pred = rf.predict(x_test)
y_pred = list(map(lambda x: x if x >= 0 else 0,y_pred))
#y小于0时,赋值为0
y_pred = list(map(lambda x: x if x <= 10 else 10,y_pred))
#y大于10时,赋值为10
MAE = np.sum(np.absolute(y_pred - y_test)) / len(y_test)
return MAE
def xgb_predict(x_train,x_test,y_train,y_test):
import xgboost as xgb
model_xgb = xgb.XGBRegressor(base_score=0.5, booster='gbtree', colsample_bylevel=0.7, colsample_bytree=0.7, gamma=0,
learning_rate=0.05, max_delta_step=0, max_depth=6, min_child_weight=50, missing=None,
n_estimators=350, n_jobs=-1, nthread=None, objective='reg:linear', random_state=2019,
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None, silent=True, subsample=1)
model_xgb.fit(x_train, y_train)
y_pred = model_xgb.predict(x_test)
y_pred = list(map(lambda x: x if x >= 0 else 0,y_pred))
y_pred = list(map(lambda x: x if x <= 10 else 10,y_pred))
MAE = np.sum(np.absolute(y_pred - y_test)) / len(y_test)
return MAE
def gbr_predict(x_train,x_test,y_train,y_test):
from sklearn.ensemble import GradientBoostingRegressor
model_gbr = GradientBoostingRegressor(alpha=0.6, criterion='friedman_mse', init=None, learning_rate=0.05, loss='ls',
max_depth=3, max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None, min_samples_leaf=10, min_samples_split=2,
min_weight_fraction_leaf=0.01, n_estimators=750, presort='auto',
random_state=2019, subsample=0.7, verbose=0, warm_start=False)
model_gbr.fit(x_train, y_train)
y_pred = model_gbr.predict(x_test)
y_pred = list(map(lambda x: x if x >= 0 else 0,y_pred))
y_pred = list(map(lambda x: x if x <= 10 else 10,y_pred))
MAE = np.sum(np.absolute(y_pred - y_test)) / len(y_test)
return MAE
def xgb_predict2(x_train,x_test,y_train,y_test):
import xgboost as xgb
model_xgb = xgb.XGBRegressor(base_score=0.5, booster='gbtree', colsample_bylevel=0.7, colsample_bytree=0.7, gamma=0,
learning_rate=0.05, max_delta_step=0, max_depth=6, min_child_weight=50, missing=None,
n_estimators=600, n_jobs=-1, nthread=None, objective='reg:linear', random_state=2019,
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None, silent=True, subsample=0.9)
model_xgb.fit(x_train, y_train)
y_pred = model_xgb.predict(x_test)
y_pred = list(map(lambda x: x if x >= 0 else 0,y_pred))
y_pred = list(map(lambda x: x if x <= 10 else 10,y_pred))
return y_pred
def gbr_predict2(x_train,x_test,y_train,y_test):
from sklearn.ensemble import GradientBoostingRegressor
model_gbr = GradientBoostingRegressor(alpha=0.6, criterion='friedman_mse', init=None, learning_rate=0.05, loss='ls',
max_depth=3, max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None, min_samples_leaf=10, min_samples_split=2,
min_weight_fraction_leaf=0.01, n_estimators=750, presort='auto',
random_state=2019, subsample=0.9, verbose=0, warm_start=False)
model_gbr.fit(x_train, y_train)
y_pred = model_gbr.predict(x_test)
y_pred = list(map(lambda x: x if x >= 0 else 0,y_pred))
y_pred = list(map(lambda x: x if x <= 10 else 10,y_pred))
return y_pred
def main():
path = "E:/AnaLinReg/Data"
data = train_data_reads(path)
data = train_data_reprocess(data)
x,y = feature_label_split(data)
x = x.iloc[0:30000,:]
y = y.iloc[0:30000]
x = dummy_variable_transform(x)
x = x.astype(np.float64)
x = data_MinMax(x)
x_train,x_test,y_train,y_test = train_test_div(x,y,0.3)
y1 = xgb_predict2(x_train,x_test,y_train,y_test)
y2 = gbr_predict2(x_train,x_test,y_train,y_test)
y = [ ((y1[i] + y2[i]) / 2.0 ) for i in range(len(y1))]
MAE = np.sum(np.absolute(y - y_test)) / len(y_test)
print (MAE)
if __name__ == "__main__":
main()
酸爽的调参过程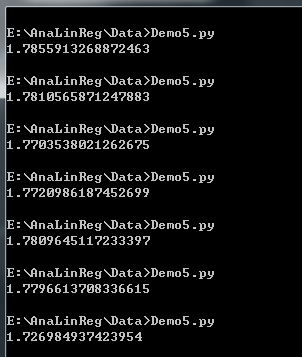
点击查看更多内容
为 TA 点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中




感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦