
hadoop单节点伪分布式
hadoop完全分布式
hadoop完全分布式高可用(HA) zookeeper
yarn高可用
hdfs
MapReduce
了解了hadoop基本的搭建,和前期可能遇到的问题。
以下是对各个功能组件的理解。
1.HADOOP
Hadoop分布式文件系统(HDFS)是一种分布式文件系统,设计用于在商品硬件上运行。它与现有的分布式文件系统有许多相似之处。但是,与其他分布式文件系统的差异很大。HDFS具有高度容错能力,旨在部署在低成本硬件上。HDFS提供对应用程序数据的高吞吐量访问,适用于具有大型数据集的应用程序。HDFS放宽了一些POSIX要求,以启用对文件系统数据的流式访问。HDFS最初是作为Apache Nutch网络搜索引擎项目的基础架构而构建的。HDFS是Apache Hadoop Core项目的一部分。
2.NameNode和DataNodes
HDFS具有主/从架构。一个HDFS集群包含一个NameNode,一个主服务器,用于管理文件系统名称空间并管理客户端对文件的访问。此外,还有许多DataNode,通常是群集中的每个节点一个DataNode,用于管理连接到它们所运行的节点的存储。HDFS公开文件系统名称空间并允许用户数据存储在文件中。在内部,文件被分成一个或多个块,大数据学习扣裙74 零零【加41 三8 1】这些块存储在一组DataNode中。NameNode执行文件系统命名空间操作,如打开,关闭和重命名文件和目录。它还确定块到DataNode的映射。DataNode负责提供来自文件系统客户端的读取和写入请求。DataNode还执行块创建,删除。 
NameNode和DataNode是设计用于在商品机器上运行的软件。这些机器通常运行GNU / Linux操作系统(OS)。HDFS使用Java语言构建; 任何支持Java的机器都可以运行NameNode或DataNode软件。使用高度可移植的Java语言意味着HDFS可以部署在各种机器上。典型的部署有一台只运行NameNode软件的专用机器。群集中的每台其他机器运行DataNode软件的一个实例。该体系结构不排除在同一台机器上运行多个DataNode,但在实际部署中很少出现这种情况。
集群中单个NameNode的存在极大地简化了系统的体系结构。NameNode是所有HDFS元数据的仲裁者和存储库。该系统的设计方式是用户数据永远不会流经NameNode。
总而言之,namenode负责记录文件存储在datanode上的位置,datanode则负责存储数据
Zookeeper
ZooKeeper是一个分布式的开源协调服务,用于分布式应用程序。它公开了一组简单的原语,分布式应用程序可以构建这些原语,以实现更高级别的服务,以实现同步,配置维护以及组和命名。它的设计易于编程,并使用在熟悉的文件系统目录树结构之后设计的数据模型。它运行在Java中,并且对Java和C都有绑定。
众所周知,协调服务很难做到正确。它们特别容易出现诸如竞态条件和死锁等错误。ZooKeeper背后的动机是减轻分布式应用程序从头开始实施协调服务的责任。
总而言之,zookeeper负责保证各个服务的高可用,我们在搭建伪分布式的时候存在SN,用于进行的edits和fsimage的合并,但是当namenode挂掉后,SN并不能起到替代NN的作用,为了保证项目中namenode的高可用,我们接入zookeeper,并启用多台NN,其中有一台NN处于active状态,其他的standby,而standby的节点不仅起到了备份的作用,还承担了SN的功能。很多架构都用到了zookeeper,来保证他们的高可用。
4.Yarn
YARN的基本思想是将资源管理和作业调度/监控的功能分解为单独的守护进程。这个想法是有一个全局的ResourceManager(RM)和每个应用程序的ApplicationMaster(AM)。应用程序可以是单个作业,也可以是DAG作业。
ResourceManager和NodeManager构成了数据计算框架。ResourceManager是仲裁系统中所有应用程序之间资源的最终权威机构。NodeManager是负责容器的每机器框架代理,监视它们的资源使用情况(cpu,内存,磁盘,网络),并将其报告给ResourceManager / Scheduler。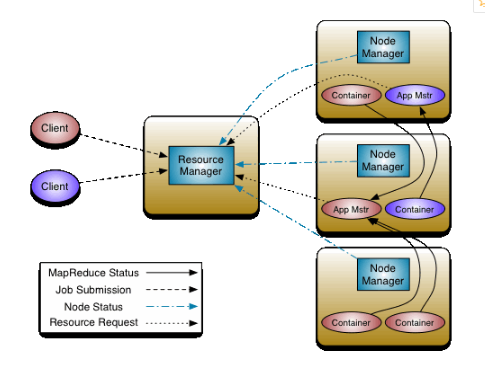
每个应用程序的ApplicationMaster实际上是一个特定于框架的库,并负责从ResourceManager协商资源,并与NodeManager一起工作来执行和监视这些任务。
ResourceManager有两个主要组件:Scheduler和ApplicationsManager。
调度程序负责将资源分配给各种正在运行的应用程序,这些应用程序受到容量,队列等熟悉的限制。调度程序是纯调度程序,因为它不会监视或跟踪应用程序的状态。此外,由于应用程序故障或硬件故障,它无法保证重启失败的任务。调度器根据应用程序的资源需求执行其调度功能; 它是基于资源容器的抽象概念来实现的,容器包含内存,CPU,磁盘,网络等元素。
调度程序有一个可插拔策略,负责在各种队列,应用程序等之间对集群资源进行分区。当前调度程序(如CapacityScheduler和FairScheduler)将是插件的一些示例。
ApplicationsManager负责接受作业提交,协商执行特定于应用程序的ApplicationMaster的第一个容器,并提供失败时重新启动ApplicationMaster容器的服务。每个应用程序的ApplicationMaster负责从调度程序中协商适当的资源容器,跟踪其状态并监视进度。
hadoop-2.x中的MapReduce 与以前的稳定版本(hadoop-1.x)保持API兼容性。这意味着只需重新编译,所有MapReduce作业仍应在YARN之上保持不变。
YARN支持的概念,资源预留通过ReservationSystem,即允许用户在指定时间资源和时间的限制(例如,截止日期),以及后备资源的配置文件,以确保重要jobs.The可预见的执行组件ReservationSystem跟踪资源过时,对预留执行准入控制,并动态指示底层调度程序确保预留满员。
为了将YARN扩展到几千个节点之外,YARN 通过YARN Federation功能支持Federation的概念。Federation允许透明地将多个YARN(子)群集在一起,并使它们看起来像一个单一的大型群集。这可以用于实现更大规模,和/或允许将多个独立的群集一起用于非常大的工作,或者对于所有人都具有容量的租户。
总而言之,yarn是我们编写MapReduce必备的组件,起到了资源调度的作用,他还保证了datanode的高可用,而zookeeper又保证了yarn的高可用。
MapReduce

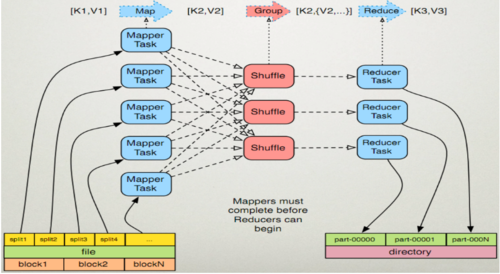
Hadoop MapReduce是一个软件框架,用于轻松编写应用程序,以可靠的容错方式在大型群集(数千个节点)的大型商业硬件上并行处理大量数据(多TB数据集)。
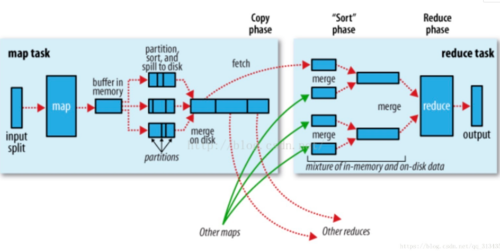
MapReduce 作业通常将输入数据集分成独立的块,由地图任务以完全平行的方式进行处理。框架对映射的输出进行排序,然后输入到reduce任务。通常,作业的输入和输出都存储在文件系统中。该框架负责调度任务,监控它们并重新执行失败的任务。
通常,计算节点和存储节点是相同的,即MapReduce框架和Hadoop分布式文件系统(请参阅HDFS体系结构指南)在同一组节点上运行。该配置允许框架在数据已经存在的节点上有效地调度任务,从而在整个集群中产生非常高的聚合带宽。
MapReduce框架由单个主资源管理器,每个集群节点的一个从属NodeManager和每个应用程序的MRAppMaster组成(参见YARN体系结构指南)。
最小程度上,应用程序通过实现适当的接口和/或抽象类来指定输入/输出位置并提供映射和减少函数。这些和其他作业参数构成作业配置。
然后,Hadoop 作业客户端将作业(jar /可执行文件等)和配置提交给ResourceManager,然后负责将软件/配置分发给从服务器,安排任务并监控它们,向作业提供状态和诊断信息,客户。
尽管Hadoop框架是用Java™实现的,但MapReduce应用程序不需要用Java编写。
总而言之,MapReduce始终计算架构,他负责分布式的运算数据,他的数据来源可以不仅仅来自于hdfs,传统的计算是以计算服务为主,将数据放置在计算服务上进行计算,而如今数据量飞速增长的时代,这几乎是一件不可能的事情,MapReduce就是为了解决这个现象而产生的计算框架,他执行在各个数据节点,并发计算,保证了数据处理的速度。
(input) -> map -> -> combine -> -> partition-> sort -> group -> reduce -> (output)
中间所有的环节,我们都可以根据我们自己的业务逻辑重写
map
逐行得到元数据并进行拆分combine
可以提前对map节点中的部分数据进行排序和合并,但是必须保证他的inputkey和outputkey一致,inputvalue和outputvalue一致,combine可以用于减少reduce的压力。partition
可以根据自己的规则将数据均匀划分,分配给节点进行运算,默认是hash值%节点数。sort
可以根据自己的项目需求重写排序规则,当你的mapreduce不为简单数据时,你可以对他进行重写,已得到你想要的排序效果group
将排序好的数据进行分组,提供给reduce进行计算,例如,你的key是a-b-c形式的数据,你想将ab相同的分为同一组递交给reduce,那么你可以在这里修改group的规则。自定义结构类型
必须 implements WritableComparable,实现write(写序列化)、readFields(度序列化)、compareTo(比较)sort、group、combine必须继承WritableComparator,通过重写compare方法实现自己的逻辑
combine和reduce一样,需要继承Reducer
共同学习,写下你的评论
评论加载中...
作者其他优质文章



