
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
n = np.nan
type(n)
#结果:
<class 'float'>
m = 1
m + n
#结果为:nan
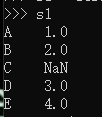
s1 = Series([1,2,np.nan,3,4],index = ['A','B','C','D','E'])
s1
还有判断Series中元素是否为nan的函数
s1.isnull()
s1.notnull()
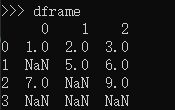
dframe = DataFrame([[1,2,3],[np.nan,5,6],[7,np.nan,9],[np.nan,np.nan,np.nan]])
dframe
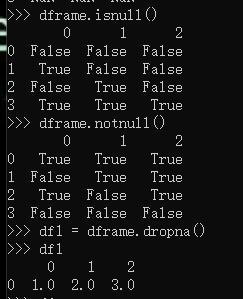
df1 = dframe.dropna(axis =0) :删除含NaN的行
df1 = dframe.dropna(axis = 1) :删除含NaN的列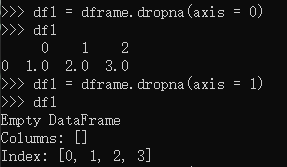
df1 = dframe.dropna(axis = 0 ,how = ‘any’):
行里面,存在NaN就删除该行
df1 = dframe.dropna(axis = 0,how = ‘all’):
行里面,全是NaN就删除该行
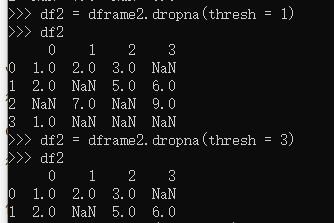
使用thresh参数过滤缺失值
df1.dropna(thresh=3)表示至少有3个不是缺失值,
df1.dropna(thresh=4)表示至少有4个不是缺失值,
前面两篇手记写得很烂,日浏览量居然还挺高的,后面我会好好整理滴
点击查看更多内容
为 TA 点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中




感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦