
安妮 乾明 发自 凹非寺
量子位 报道 |QbitAI

实习生又立功了!
这一次,亮出好成绩的实习生来自地平线,是一名华中科技大学的硕士生。
他作为第一作者完成的研究Mask Scoring R-CNN,在COCO图像实例分割任务上超越了何恺明的Mask R-CNN,拿下了计算机视觉顶会CVPR 2019的口头报告。
也就是说,它从5000多篇投稿中脱颖而出,成为最顶尖的5.6%。
无论搭配的基干怎么变,表现一直稳定,总是比Mask R-CNN好一点。
可谓青出于蓝而胜于蓝。
并且,他们的算法已经开源了(传送门在文末)。
给蒙版打分
Mask R-CNN,一种简洁、灵活的实例分割框架,大神何恺明的“拿手作”之一。自2017年一出场就惊艳了四方研究者,何恺明也借此一举拿下ICCV 2017最佳论文奖。
△ 何恺明
新鲜出炉的Mask Scoring R-CNN,性能是怎样超越前辈的呢?
关键就在名字里的“打分”(Scoring)。这篇论文中,研究人员提出了一种给算法的“实例分割假设”打分的新方法。这个分数打得是否准确,就会影响实例分割模型的性能。
而Mask R-CNN等前辈,用的打分方法就不太合适。
这些模型在实例分割任务里,虽然输出结果是一个蒙版,但打分却是和边界框目标检测共享的,都是针对目标区域分类置信度算出来的分数。
这个分数,和图像分割蒙版的质量可未必一致,用来评价蒙版的质量,可能就会出偏差。

于是,这篇CVPR 2019论文就提出了一种新的打分方法:给蒙版打分,他们称之为蒙版得分(mask score)。
△ MS R-CNN架构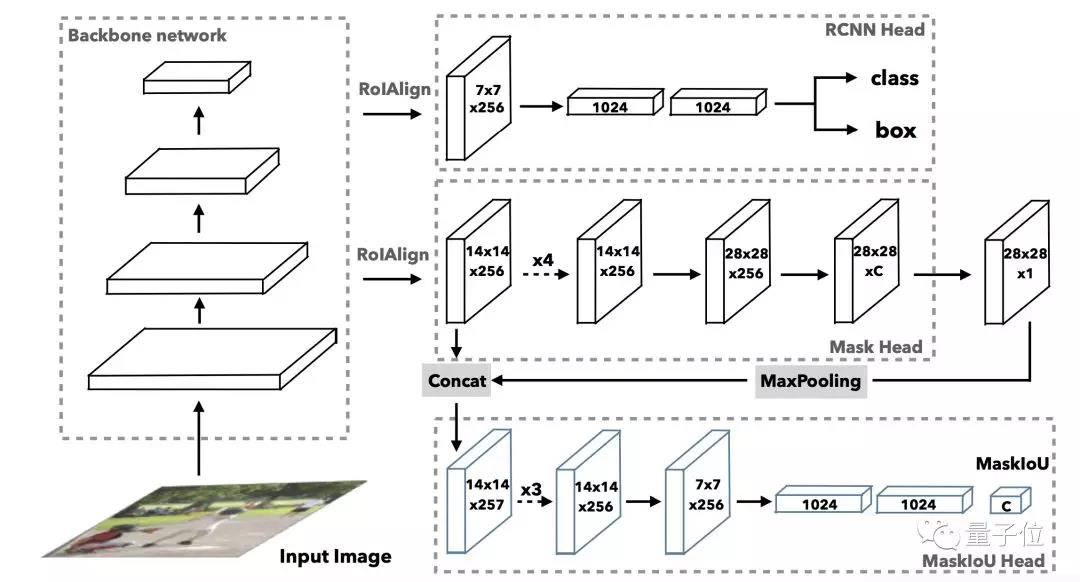
Mask Scoring R-CNN中提出的计分方式很简单:不仅仅直接依靠检测得到的分类算分,而且还让模型单独学一个针对蒙版的得分规则:MaskIoU head。
MaskIoU head是在经典评估指标AP(平均正确率)启发下得到的,会拿预测蒙版与物体特征进行对比。MaskIoU head同时接收蒙版head的输出与ROI的特征(Region of Interest)作为输入,用一种简单的回归损失进行训练。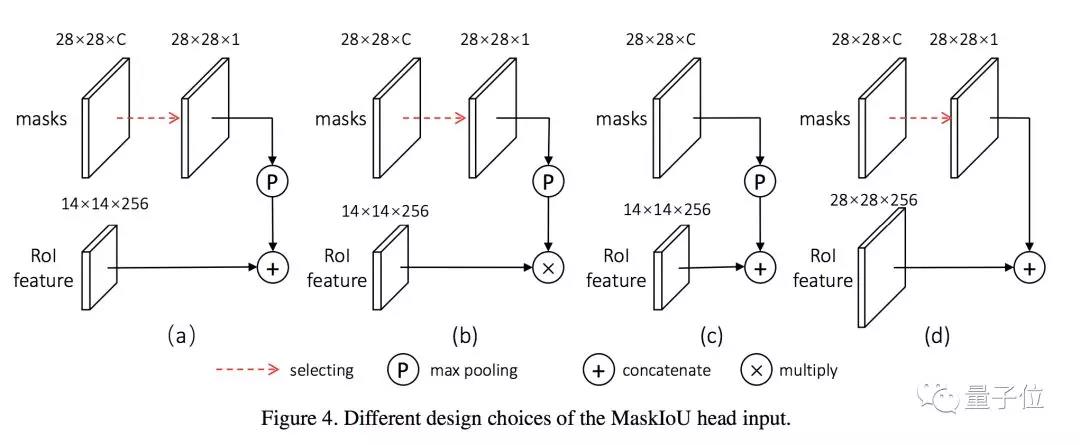
最后,同时考虑分类得分与蒙版的质量得分,就可以去评估算法质量了。
评测方法公平公正,实例分割模型性能自然也上去了。
实验证明,在挑战COCO benchmark时,在用MS R-CNN的蒙版得分评估时,在不同基干网路上,AP始终提升近1.5%。
优于Mask R-CNN
下面的表格,是COCO 2017测试集(Test-Dev set)上MS R-CNN和其他实例分割方法的成绩对比。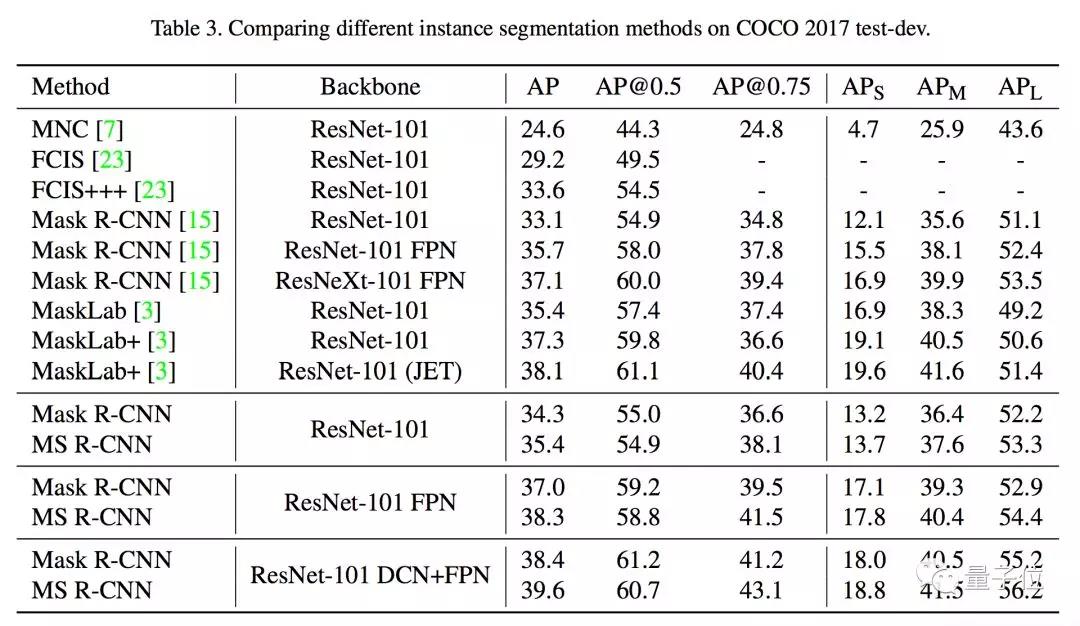
无论基干网络是纯粹的ResNet-101,还是用了DCN、FPN,MS R-CNN的AP成绩都比Mask R-CNN高出一点几个百分点。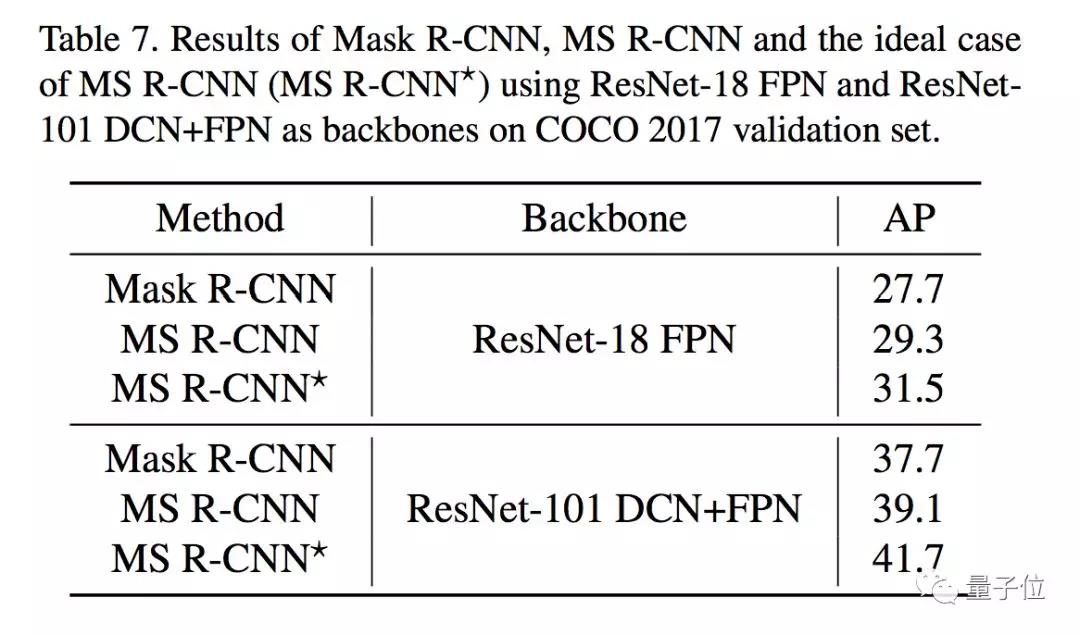
在COCO 2017验证集上,MS R-CNN的得分也优于Mask R-CNN:
作者是谁?
第一作者,名为黄钊金,华中科技大学的硕士生,师从华中科技大学电信学院副教授王兴刚,王兴刚也是这篇论文的作者之一。
其他的作者,分别是地平线的Chang Huang、Yongchao Gong和Lichao Huang。
如果你对这项研究感兴趣,请收好传送门:
Mask Scoring R-CNN论文:
Mask R-CNN的其他优化思路
在此之前,也有人提出了优化Mask R-CNN的思路。
比如,香港中文大学、北京大学、商汤科技、腾讯优图在CVPR 2018发表的一篇论文,提出了一个名为PANet的实例分割框架。
优化了Mask R-CNN中的信息传播,通过加速信息流、整合不同层级的特征,提高了生成预测蒙版的质量。
在未经大批量训练的情况下,就拿下了COCO 2017挑战赛实例分割任务的冠军。

论文地址:
Path Aggregation Network for Instance Segmentation
https://arxiv.org/abs/1803.01534
— 完 —
共同学习,写下你的评论
评论加载中...
作者其他优质文章


