
简单介绍
flink-kafka-connector用来连接kafka,用于消费kafka的数据, 并传入给下游的算子。
使用方式
首先来看下flink-kafka-connector的简单使用, 在官方文档中已经介绍了,传入相关的配置, 创建consumer对象, 并调用addsource即可
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");// only required for Kafka 0.8properties.setProperty("zookeeper.connect", "localhost:2181");
properties.setProperty("group.id", "test");
DataStream<String> stream = env
.addSource(new FlinkKafkaConsumer08<>("topic", new SimpleStringSchema(), properties));类图分析
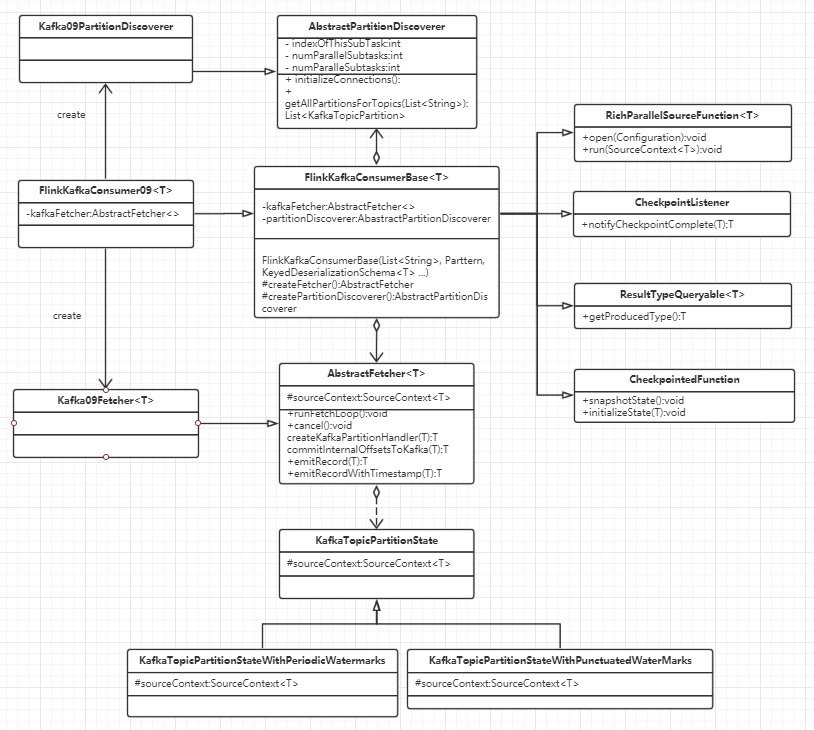
从类图来看,flink-kafka-connector 基本类为FlinkKafkaConsumerBase, 继承RichParallelSourceFunction, 重写了open和run方法。
再open方法中主要是做一些初始化的工作, 获得所有的topic的partiiton信息, 使用partitionDiscoverer来获得topic的parition信息, 不同版本的connector对于getAllPartitionsForTopics有着不同的实现。 在run方法中用于从kafka中读取消息放入SourceContext中, 其中消息获取逻辑放在了AbstractFetcher中, 不同版本的Fetcher对于runFetchLoop有不同的实现,不同版本的kafka-connector有着不同的实现.
并行逻辑解析
对于RichParallelSourceFunction, 是可以设置并行的, 通过设置设置并行度, 可以在多个taskMansger中同时消费kafka在AbstractFetcher中, 有两个队列, subscribedPartitionStates和unassignedPartitionsQueue分别用于保存当前已经在读取的topic的parition和未读取的parition。 通过partitionDiscoverer中的getAllPartitionsForTopics来获得所有topic的partition, 后通过KafkaTopicPartiitonAssigner来判断当前parition是否为当前的source所消费,
public static int assign(KafkaTopicPartition partition, int numParallelSubtasks) { int startIndex = ((partition.getTopic().hashCode() * 31) & 0x7FFFFFFF) % numParallelSubtasks; // here, the assumption is that the id of Kafka partitions are always ascending
// starting from 0, and therefore can be used directly as the offset clockwise from the start index
return (startIndex + partition.getPartition()) % numParallelSubtasks;
}在初始化时, 会放入subscribedPartitionStates((此逻辑在FlinkKafkaConsumerBase的open方法中), 之后发现的新的topicparition(在FlinkFafkaConsumerBase的run方法中),调用kafkaFetcher.addDiscoveredPartitions() 会同时放入 subscribedPartitionStates和unassignedPartitionsQueue,。
unassignedPartitionsQueue主要用于将新发现的parition信息传递给消费线程, 在kafka-0.9版本中, 由ConsumerThread不断获取,如果有新的partition, 会由client一并消费.
在kafka-08版本中,使用线程池来消费, 每个borker对应一个线程, 会在Kafka08Fetcher的runfetchloop中不断获取,会放到parition的所在的borker对应的线程中.
subscribedPartitionStates 用于初始化的工作消费设置和保存所有的topic的消费信息。 在消息的消费中, 会不断更新队列中每个partition的partitionstate. 主要用于其他线程的offset上报或者metric的上报.
watermark的处理
flink-kafka提供了设置watermark的接口 assignTimestampsAndWatermarks(), 在emitRecord中会调用对所设置的watermater生成函数,为每个partition生成其对应的watermark.
如果设置了PeriodicWatermark, 会起一个线程, 定时发送watermark。
如果设置了PunctuatedWatermark, 会在emitRecordWithTimestampAndPunctuatedWatermark中, 调用checkAndGetNewWatermark(), 是否有新的watermark生成.
checkpoint的处理
通过继承相关的类和接口。 CheckpointedFunction,initializeState用于初始化checkpoint, snapshotState用于保存checkpoint
CheckpointListener中notifyCheckpointComplete, 用作checkpoint保存成功的回调, 在kafka-connector中调用commitInternalOffsetsToKafka, 将offset信息上报给kafka.
metric的使用
flink-kafka-connector中使用了flink中的metric库, 用来监控消费信息, 主要是commitoffset和currentOffset信息。
在AbstractFetcher的registerOffsetMetrics中, 注册了对于CurrentOffset和CommitOffset的监控.
通过flink job的查看页面,可以看到各个topic的partition的消费情况.
作者:fk12138
共同学习,写下你的评论
评论加载中...
作者其他优质文章


