
日本漫画《铳梦》改编电影《阿丽塔:战斗天使(Alita: Battle Angel)》于2019年2月22日在中国大陆上映了。近几天,网上对于这部电影的分析评论也很多,今天通过猫眼电影上的评论粗浅地看一下大众对这部科幻电影的评价。
工具库
- jieba
- pyecharts
- wordcloud
- matplotlib
分析网站
通过在浏览器模拟移动端请求评论的数据,可以看到随着页面的更改url并没有发生变化,初步判断该网页是通过js加载的,要想爬取首先得找到真实url和返回的数据格式。
通过多次的实践,找到了请求返回的真实url和关键参数,这里返回的是json格式的数据,里面有我们需要的信息。
通过比较多次请求信息,发现以下的参数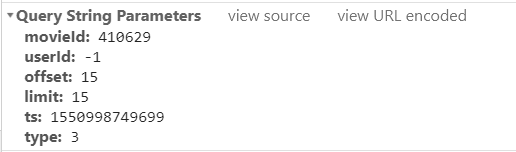
其中,offset是每次请求的起始评论条数;limit是每次请求的条数;ts我猜测应该是时间戳,不用管它
抓取信息
通过返回的json数据,选取其中的content,score,nick ,gender这四个参数,将这些信息写入一个文本中保存起来。
代码:
def get_comments(self):
'''
爬取评论信息
:return:
'''
for i in range(0, 14352, 15):
URL = self.url.format(i)
data = requests.get(url=URL, headers=self.header)
time.sleep(random.random() * 3)
com = json.loads(data.text)
comments = com['data']['comments']
if comments:
for item in comments:
data = {
'content': item['content'],
'score': item['score'],
'nick': item['nick'],
'gender': item['gender'],
}
print(data)
# 存入文本中
with open('comments.txt', 'a+', encoding='UTF-8') as file:
file.writelines(
json.dumps(data, ensure_ascii=False) + '\n')
else:
break
由于爬取的数据都是比较规整,并且没有选择太多的特征,所以就跳过清洗阶段,直接进行分析。为了便于观察,这里使用pyecharts进行可视化处理。
1. 评论词云
通过词云,能够一目了然地知道这些精选评论都说了些什么。由于使用pyecharts制作词云需要比较繁琐的处理,所以直接使用jieba分词并用WordCloud进行制作词云。
可以看到,“好看”,“特效”,“第二部”,“剧情”,这几个词都是出现比较多次的,再通过去原来保存评论信息的文本中查询,这些词的整个评论,我发现很多人都是在说电影没有结局,或者期待出第二部的。
2.性别比例
由于爬取到的性别都是使用数字0,1,2进行标识的,所以按照程序员的思维。我就用 0代表男,1代表女,2代表未知来进行处理了。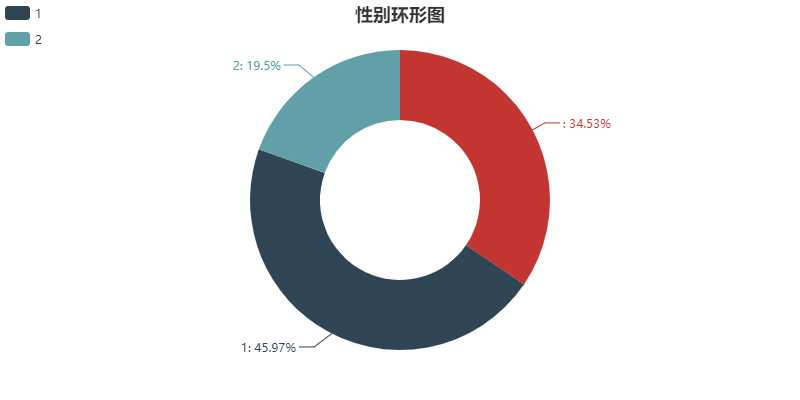
从图中可以看出,评论以男性居多,约占总数的50%,估计是男同胞们对这类比较抽象,充满想象的电影比较感兴趣吧~
3.评分情况
从猫眼的总评分9.0来看,这部电影还是比较不错的,截止2月24日已经在中国拿下了39510万元的票房。
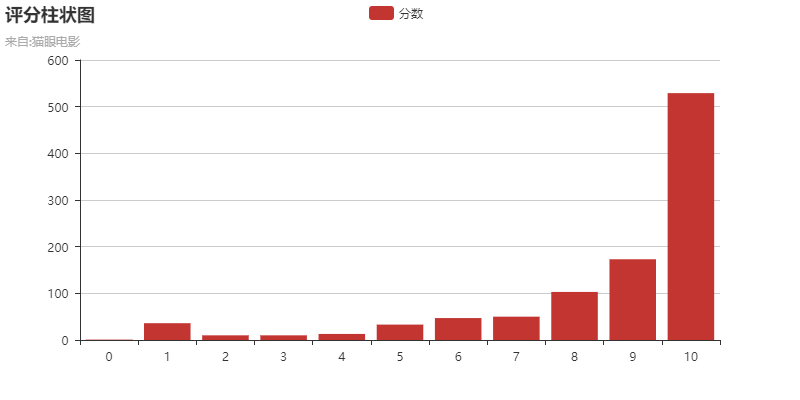
通过上图,可以清楚地看到,大部分的评分都是8-10分的,所以总评的9.0也是有依据的。
最后
虽然这部电影一些的情节都没有介绍清楚,但是很多的战斗细节都用特效展现的淋漓尽致。据说全片特效渲染动用了30000台电脑,总耗时4.32亿小时,这也是国内的“五毛钱”特效所不能比拟的。
最后来看下这部片的女主吧!

附
共同学习,写下你的评论
评论加载中...
作者其他优质文章



