
爬前叨叨
今天要爬取一下正规大学名单,这些名单是教育部公布具有招生资格的高校名单,除了这些学校以外,其他招生的单位,其所招学生的学籍、发放的毕业证书国家均不予承认,也就是俗称的野鸡大学!

网址是 https://daxue.eol.cn/mingdan.shtml 爬取完毕之后,我们进行一些基本的数据分析,套路如此类似,哈哈
这个小项目采用的是scrapy,关键代码
import scrapyfrom scrapy import Request,Selectorclass SchoolSpider(scrapy.Spider):
name = 'School'
allowed_domains = ['daxue.eol.cn']
start_urls = ['https://daxue.eol.cn/mingdan.shtml'] def parse(self, response):
select = Selector(response)
links = select.css(".province>a")
for item in links:
name = item.css("::text").extract_first()
link = item.css("::attr(href)").extract_first() if name in ["河南","山东"]: yield Request(link,callback=self.parse_he_shan,meta={"name" : name}) else: yield Request(link,callback=self.parse_school,meta={"name" : name})注意到几个问题,第一个所有的页面都可以通过第一步抓取到
但是里面出现了两个特殊页面,也就是山东和河南
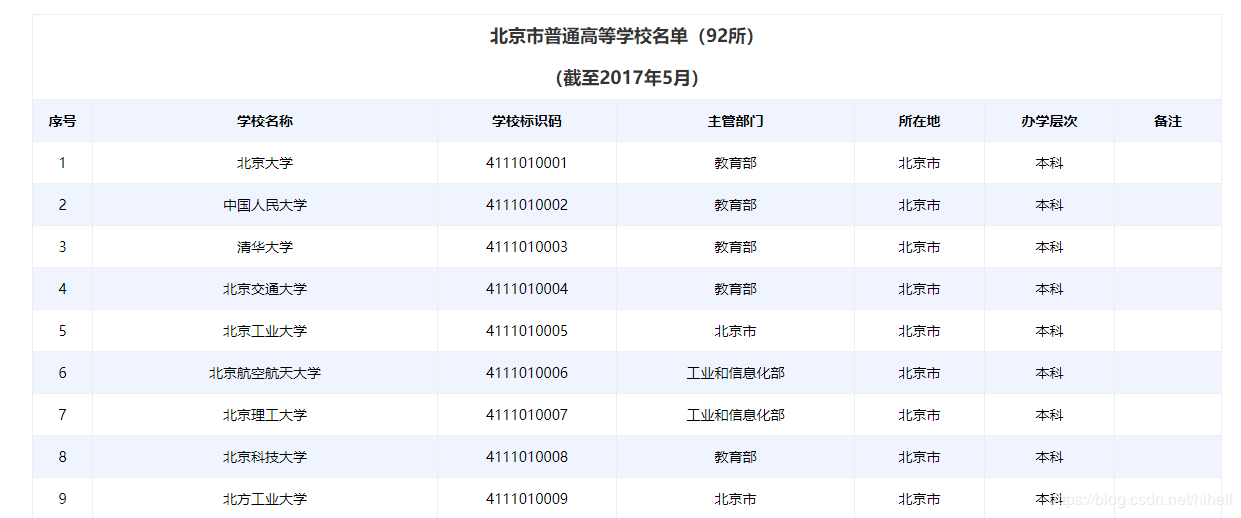
北京等学校
河南等学校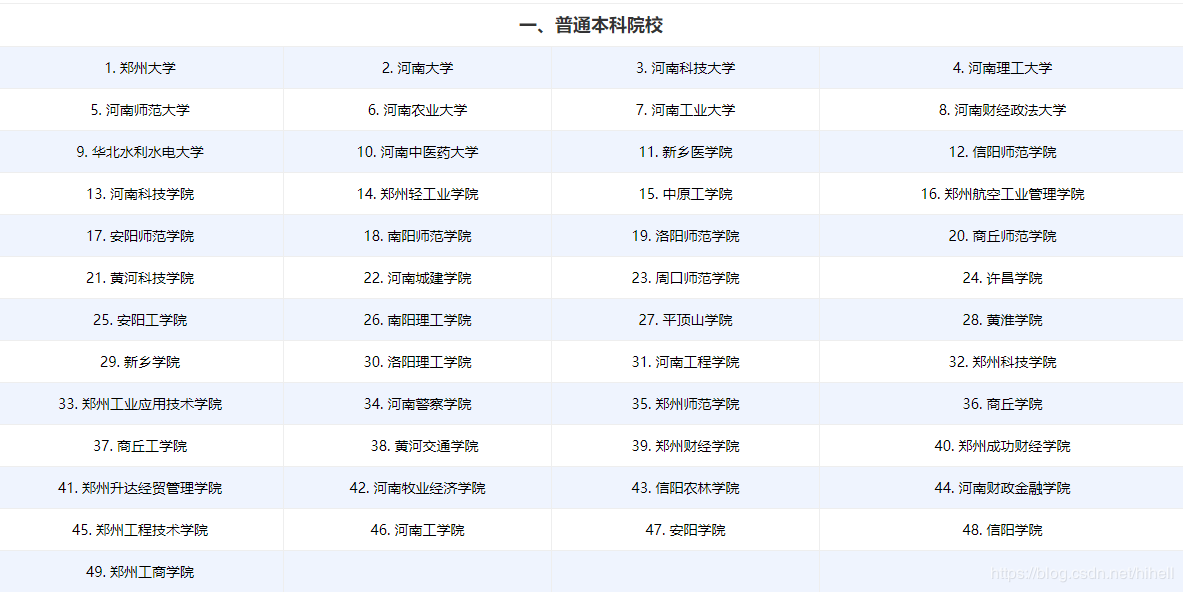
对于两种不同的排版,我们采用2个方法处理,细节的地方看代码就可以啦!
尤其是下面对字符串的处理,你要仔细的查阅~
# 专门为河南和山东编写的提取方法
def parse_he_shan(self,response):
name = response.meta["name"]
data = response.css(".table-x tr") for item in data:
school_name = item.css("td:not(.tmax)::text").extract() if len(school_name)>0: for s in school_name: if len(s.strip())>0: if len(s.split("."))==1:
last_name = s.split(".")[0] else:
last_name = s.split(".")[1] # 最终获取到的名字
yield { "city_name": name, "school_name": last_name, "code": "", "department": "", "location": "", "subject": "", "private": ""
} # 通用学校提取
def parse_school(self,response):
name = response.meta["name"]
schools = response.css(".table-x tr")[2:] for item in schools:
school_name = item.css("td:nth-child(2)::text").extract_first()
code = item.css("td:nth-child(3)::text").extract_first()
department = item.css("td:nth-child(4)::text").extract_first()
location = item.css("td:nth-child(5)::text").extract_first()
subject = item.css("td:nth-child(6)::text").extract_first()
private = item.css("td:nth-child(7)::text").extract_first() yield { "city_name":name, "school_name":school_name, "code":code, "department":department, "location":location, "subject":subject, "private":private
}运行代码,跑起来,一会数据到手。O(∩_∩)O哈哈~
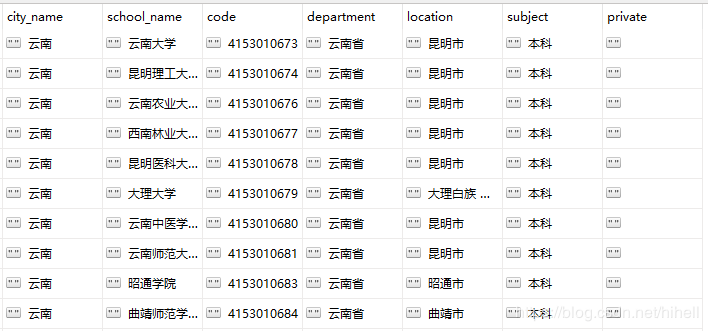
查看专科学校和本科学校数量差别
因为河南和山东数据的缺失,需要踢出这两个省份
import pymongoimport numpy as npimport pandas as pdfrom pandas import Series,DataFrameimport matplotlib.pyplot as plt
client = pymongo.MongoClient("localhost",27017)
schools = client["school"]
collection = schools["schools"]
df = DataFrame(list(collection.find()))
df = df[df["code"]!=""]# 汇总本科和专业df.groupby(["subject"]).size()结果显示,数量基本平衡
subject 专科 1240本科 1121dtype: int64
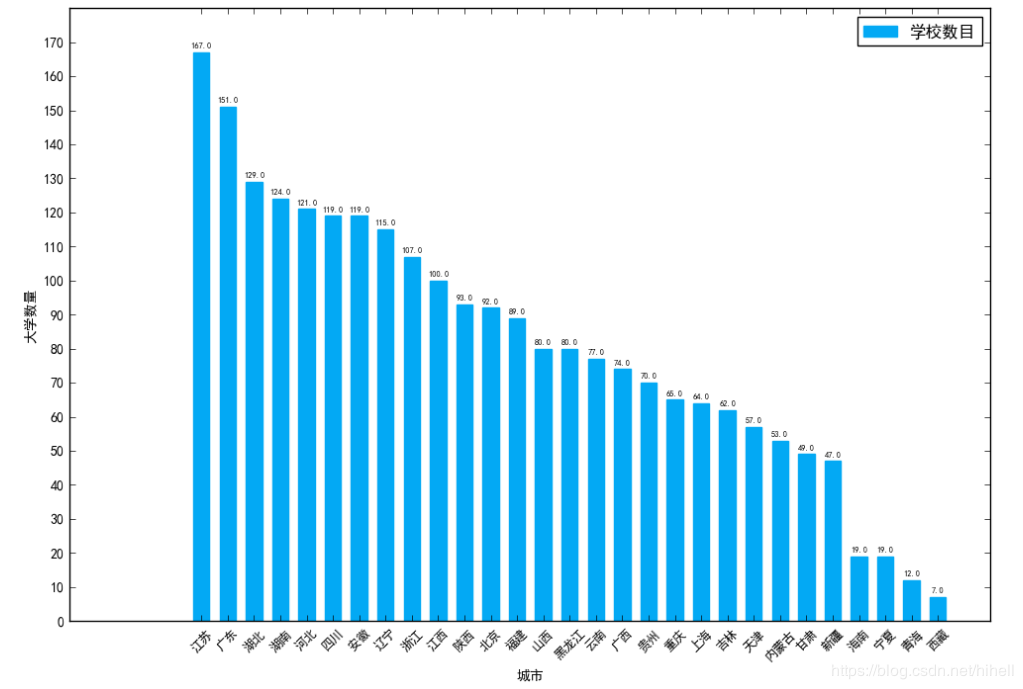
查看各省排名
rank = df.groupby(by="city_name").size()
rank = rank.sort_values(ascending=False)# 设置中文字体和负号正常显示plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = Falseplt.figure(figsize=(12,8),dpi=80)
plt.subplot(1,1,1)
x = np.arange(len(rank.index))
y = rank.values
rect = plt.bar(left=x,height=y,width=0.618,label="学校数目",align="center",color="#03a9f4",edgecolor="#03a9f4",)
plt.xticks(x,rank.index,rotation=45,fontsize=9)
plt.yticks(np.arange(0,180,10))
plt.xlabel("城市")
plt.ylabel("大学数量")
plt.legend(loc = "upper right")## 编辑文本for r in rect:
height = r.get_height() # 获取高度
plt.text(r.get_x()+r.get_width()/2,height+1,str(height),size=6,ha="center",va="bottom")
plt.show()好好研究这部分代码,咱已经开始慢慢的在爬虫中添加数据分析的内容了,我会尽量把一些常见的参数写的清晰一些
作者:梦想橡皮擦
点击查看更多内容
为 TA 点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中




感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦