
在说明原子操作之前,我们先看下面这段Java代码:
public class AtomicTest {
private static final int COUNT_TIMES = 10000 * 10000;
private static volatile int counter = 0;
public static void main(String[] args) {
Runnable r = () -> {
for (int i = 0; i < COUNT_TIMES; i++) {
counter++;
}
};
Thread t1 = new Thread(r);
Thread t2 = new Thread(r);
t1.start();
t2.start();
try {
t1.join();
t2.join();
System.out.printf("counter = %d
", counter);
} catch (InterruptedException e) {
e.printStackTrace();
}
}}
不懂java也没关系,上面这段代码做的事情很简单,开了2个线程对同一个共享整型变量分别执行一亿次加1操作,我们期望最后打印出来counter的值为200000000(2亿),但事与愿违,运行上面的代码,counter的值是极有可能不等于2亿的,而且每次运行结果都不一样,总是小于2亿。为什么会出现这个情况呢?从Java内存模型的角度来看,简单的counter++的执行过程其实分为如下三步:
第一步,从主内存中加载counter的值到线程工作内存 第二步,执行加1运算 第三步,把第二步的执行结果从工作内存写入到主内存
那么现在假设主内存中counter的值是100,两个线程现在都同时执行counter++,则可能出现如下情况:
线程 1 从主内存中加载counter的值100到线程 1 到工作内存 线程 2 从主内存中加载counter的值100到线程 2 到工作内存 线程 1 执行加1运算得到结果101 线程 2 执行加1运算得到结果101 线程 1 把101写入主内存中的counter变量 线程 2 把101写入主内存中的counter变量
线程1和2都执行了+1运算,本来我们期望得到102,但却错误的得到了101这个值。
从上面这个引起错误的流程可以看出,之所以结果错误,其本质是两个线程同时操作了同一个对象,线程1执行++运算的过程中插入了线程2的++操作,也就是说从另外一个线程的角度看++操作并不是一个原子操作。
现在我们已经知道多线程并发执行counter++其结果并不正确的原因了,但怎么解决这个问题呢?既然错误是因为++不是一个原子操作,那么我们想办法使其成为原子操作就可以了,所以我们可以:1,加锁,2,使用原子变量。
首先来看加锁,伪码如下:
for (int i = 0; i < COUNT_TIMES; i++) {
lock();
counter++;
unlock();
}
就是在执行counter++之前加锁,防止其它线程同时执行这一句,这一句执行完之后解锁让其它线程有机会执行这一句。虽然这个方法可以解决问题,但大家可以自己试一下,你会发现加锁之后性能急剧下降,主要原因是锁冲突会造成线程等待别人解锁而造成线程切换,这种上下文切换开销很大。
下面我们试试使用原子变量,C语言中可以使用gcc提供的原子操作函数,Java中可以使用Atomic相关类,如下面的Java代码:
public class AtomicTest {private static final int COUNT_TIMES = 10000 * 10000;
private static volatile int counter = 0;
private static volatile AtomicInteger atomCounter = new AtomicInteger(0); //Java提供的int型原子变量
public static void main(String[] args) {
Runnable r = () -> {for (int i = 0; i < COUNT_TIMES; i++) {
atomCounter.addAndGet(1); //原子变量的加法
}
};
Thread t1 = new Thread(r);
Thread t2 = new Thread(r);
t1.start();;
t2.start();
try {
t1.join();
t2.join();
System.out.printf("atomCounter = %d
", atomCounter.get());
} catch (InterruptedException e) {
e.printStackTrace();
}
}}
代码中使用的AtomicInteger类,其addAndGet()方法执行加法运算,这个方法执行加法操作时是原子的,所以不需要我们在代码中加锁。如果我们运行这段代码,会发现它比前面提到的加锁方法效率高很多,加锁方法执行1亿次加法所用时间是使用原子变量的好几倍。为什么使用原子变量效率会高出这么多呢?要想找到答案,就得分析原子变量提供的原子操作是怎么实现的。
下面我们就来看看原子变量是如何实现的,首先我们看Java中怎么实现的,然后分析gcc的实现。
Java中的原子类实现在java.util.concurrent.atomic包中,找到AtomicInteger类,为了减小篇幅,这里只保留类的很小一部分来说明问题
public class AtomicInteger extends Number implements java.io.Serializable {
private volatile int value;
/**
* Creates a new AtomicInteger with the given initial value.
*
* @param initialValue the initial value
*/
public AtomicInteger(int initialValue) {
value = initialValue;
}
/**
* Gets the current value.
*
* @return the current value
*/
public final int get() {
return value;
}
/**
* Atomically adds the given value to the current value.
*
* @param delta the value to add
* @return the updated value
*/
public final int addAndGet(int delta) {
return unsafe.getAndAddInt(this, valueOffset, delta) + delta;
}}
可以看到addAndGet方法使用了unsafe包的getAndAddInt方法:
/**
* Atomically adds the given value to the current value of a field
* or array element within the given object <code>o</code>
* at the given <code>offset</code>.
*
* @param o object/array to update the field/element in
* @param offset field/element offset
* @param delta the value to add
* @return the previous value
* @since 1.8
*/
public final int getAndAddInt(Object o, long offset, int delta) {
int v;
do {
v = getIntVolatile(o, offset);
} while (!compareAndSwapInt(o, offset, v, v + delta));
return v;
}/**
* Atomically update Java variable to <tt>x</tt> if it is currently
* holding <tt>expected</tt>.
* @return <tt>true</tt> if successful
*/
public final native boolean compareAndSwapInt(Object o, long offset,
int expected,
int x);
这里用的do{ }while 循环调用compareAndSwapInt方法实现的,这个方法是一个本地方法,通过JNI调用的C++代码,我们需要到虚拟机的目录中去找这个方法的C++实现:
UNSAFE_ENTRY(jboolean, Unsafe_CompareAndSwapInt(JNIEnv *env, jobject unsafe, jobject obj, jlong offset, jint e, jint x))
UnsafeWrapper("Unsafe_CompareAndSwapInt");
oop p = JNIHandles::resolve(obj);
jint* addr = (jint *) index_oop_from_field_offset_long(p, offset);
return (jint)(Atomic::cmpxchg(x, addr, e)) == e;UNSAFE_ENDinline jint Atomic::cmpxchg (jint exchange_value, volatile jint* dest, jint compare_value) {
int mp = os::is_MP();
__asm__ volatile (LOCK_IF_MP(%4) "cmpxchgl %1,(%3)"
: "=a" (exchange_value)
: "r" (exchange_value), "a" (compare_value), "r" (dest), "r" (mp)
: "cc", "memory");
return exchange_value;}
最终可以看到实现的核心是lock cmpxchg,lock前缀用于锁总线,保证原子性和实现内存屏障功能。下面用维码来把前面讨论的东西串在一起说明一下如何保证i++这种操作的原子性
int i = 0;for (;;) {
v = i;
//lock cmpxchg指令的的逻辑 ---START---
lock总线 if (i == v) {
i = i + 1;
break;
}
unlock总线 //lock cmpxchg指令的的逻辑 ---END---}
我们可以清楚的看到原子变量的原子操作也是用到了锁,只不过这个是硬件指令级别的锁,比我们软件实现的锁高效很多,更重要的是从上面的伪码可以看出,如果出现了冲突,只是不停的循环重试,而不会切换线程。
我们又来看一下gcc怎么实现原子操作,高版本的gcc提供了一系列原子操作函数,比如__sync_fetch_and_add,这个函数实现原子的从内存中读取一个值,然后执行加法操作,最后把结果写入内存。看个例子:
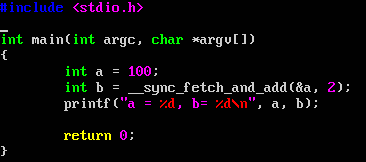
这段代码最后会打印出 a = 102, b = 100. 来看一下gcc怎么实现的这个函数,用gdb直接反汇编:
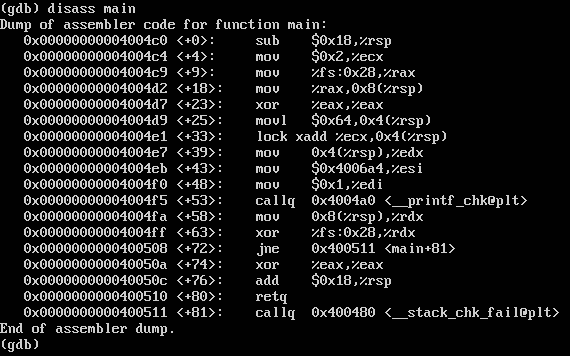
看<+33>行的lock xadd %ecx, 0x4(%rsp),这条xadd指令直接把ecx寄存器中的值(常量2)加到一个内存中的值(变量a)之上,看起来好像只有1次内存访问,但事实上这条指令至少进行了2次内存访问:首先从内存中读取a的值,然后求和并把求和结果存入变量a之中,即:
1,从内存读取变量a的值到寄存器
2,与2相加
3,把相加后的结果存入变量a对应的内存
这明明是三步操作为什么能够保证原子操作呢,答案就在于xadd这个指令,cpu执行这个指令之前首先会把这条指令之前的读写内存操作完成,然后锁住内存总线直到执行完上面的三步操作之后才释放总线,在这段时间之内,其它cpu是无法访问内存的,这条指令还有内存屏障的功能,也就是说xadd既保证原子操作,又保证执行这条指令的前和后完成内存屏障功能,所以只要多个cpu都按照规定使用xadd并发的操作变量a,就可以保证多个线程并发的执行这种加法操作而不需要我们手动的添加锁来完成同步。当然如果你在一个线程中使用__sync_fetch_and_add执行对变量a的加法操作,然后在另外一个线程中却使用a += 2这样的操作的话肯定会有问题的。
总结:Java中使用的是循环调用CAS操作实现的原子变量的原子操作,而gcc使用的是xadd指令,可以看出gcc的实现方式更加简洁,应该也是更加高效的。
共同学习,写下你的评论
评论加载中...
作者其他优质文章


