
Volley目前看来是一个很老的框架了,很早之前我也在项目中使用过,但是当时没有去深入了解其原理。后来OkHttp出来之后,便迁移到了Okhttp。Okhttp以他的高效闻名,而大多数文章也仅仅只是一笔带过,许多人也只是跟风效仿并不知道其中为何高效之处。而同为优秀的热门框架,为何Okhttp更被大家所推荐,更多人使用?这是我重新研究Volley的原因,既然性能有优劣,那一定是需要对比。所以我们起码要了解不同框架的原理和实现思路,这样才能知道为什么这个框架更加好更加适合我们的业务,是否需要使用这个框架,这是对技术选型判断的依据,也是我写这个文章和后面分析okhttp的目的。
下面我会由一个基本的发起请求调用开始,一步步分析Volley运行机制。
简单的调用
下面的例子是一个最基本的Volley发起get、post请求的一个调用。
fun requst(){
val url = ""
val queue = Volley.newRequestQueue(context)
val getRequest = StringRequest(Request.Method.GET, url,this, this)
val postRequest = object : StringRequest(Request.Method.POST, url, this, this){
@Throws(AuthFailureError::class)
override fun getParams(): Map<String, String> { return HashMap<String, String>()
}
} queue.add(getRequest) queue.add(postRequest)
}设计图
大家可以先看一眼这个设计图,有一个大致的概念,知道有这么些东西,下面的流程分析中都会涉及到,看完可以再回顾一下这张图加深印象。
同时如果想深入了解Volley细节的,推荐看一下这个文章Volley源码解析,图片也是来自这篇文章的。
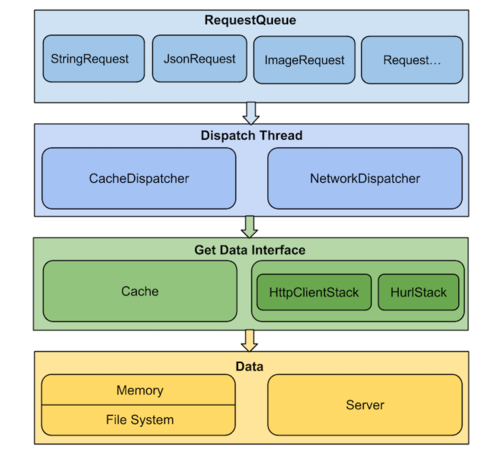
image.png
请求内部流程
首先分析其构造queue的逻辑,newRequestQueue方法最终会调用到
public static RequestQueue newRequestQueue(Context context, HttpStack stack, int maxDiskCacheBytes) {
File cacheDir = new File(context.getCacheDir(), DEFAULT_CACHE_DIR);
String userAgent = "volley/0"; try {
String packageName = context.getPackageName();
PackageInfo info = context.getPackageManager().getPackageInfo(packageName, 0);
userAgent = packageName + "/" + info.versionCode;
} catch (NameNotFoundException e) {
}
//这里会构建一个HurlStack对象,这个对象是最终建立连接发起请求的地方
if (stack == null) { if (Build.VERSION.SDK_INT >= 9) { stack = new HurlStack();
} else { // Prior to Gingerbread, HttpUrlConnection was unreliable.
// See: http://android-developers.blogspot.com/2011/09/androids-http-clients.html
stack = new HttpClientStack(AndroidHttpClient.newInstance(userAgent));
}
} //BasicNetwork对象可以理解为发送请求的辅助类,会做一些网络超时重试读取写入response一些操作
Network network = new BasicNetwork(stack);
RequestQueue queue; //如果没有指定最大的本地缓存文件大小会调用默认的构造方法,默认是5*1024*1024
if (maxDiskCacheBytes <= -1)
{ // No maximum size specified
queue = new RequestQueue(new DiskBasedCache(cacheDir), network);
} else
{ // Disk cache size specified
queue = new RequestQueue(new DiskBasedCache(cacheDir, maxDiskCacheBytes), network);
} //开启队列循环
queue.start(); return queue;
}对于这个过程关键的一个地方我写了一些注释,先看一下RequestQueue的构造过程。
首先从上面我们可以看到他构建了一个DiskBasedCache对象,这个对象的功能是缓存response。缓存的容器是一个初始大小为16的LinkedHashMap,如果不设置缓存,默认的大小是510241024。每次添加缓存的时候会先判断容器剩余大小是否满足,不足的话会遍历LinkedHashMap删除,直达满足最大容量*0.9,这个里面的写入请求头的操作还大量设计到了位运算。有兴趣的可以单独看一下com.android.volley.toolbox.DiskBasedCache这个类的实现。
分析完DiskBasedCache对象之后,我们看一下RequestQueue对象构建的过程:
public RequestQueue(Cache cache, Network network, int threadPoolSize,
ResponseDelivery delivery) {
mCache = cache;
mNetwork = network;
mDispatchers = new NetworkDispatcher[threadPoolSize];
mDelivery = delivery;
}我贴上来的是最终的构造方法,实际上如果不指定线程池的大小,会默认创建一个默认大小为4的ExecutorDelivery线程数组。
首先看一下ResponseDelivery对象:
public RequestQueue(Cache cache, Network network, int threadPoolSize) { this(cache, network, threadPoolSize, new ExecutorDelivery(new Handler(Looper.getMainLooper())));
}这个类的作用是对请求的结果进行分发,我们也看到了,这里传入的是一个主线程的handler对象,他的作用实际上也就是把对网络请求和IO操作的结果切换到了UI线程。有兴趣的可查看com.android.volley.ExecutorDelivery。
接下来就是开启队列的循环:
public void start() {
stop(); // Make sure any currently running dispatchers are stopped.
// Create the cache dispatcher and start it.
//CacheDispatcher对象继承Thread
mCacheDispatcher = new CacheDispatcher(mCacheQueue, mNetworkQueue, mCache, mDelivery);
mCacheDispatcher.start(); // Create network dispatchers (and corresponding threads) up to the pool size.
for (int i = 0; i < mDispatchers.length; i++) {
NetworkDispatcher networkDispatcher = new NetworkDispatcher(mNetworkQueue, mNetwork,
mCache, mDelivery);
mDispatchers[i] = networkDispatcher;
networkDispatcher.start();
}
}这里我们可以看到两个对象,CacheDispatcher、NetworkDispatcher。这里一个是负责处理复用本地缓存请求,一个是获取网络数据的,与两个队列mCacheQueue、mNetworkQueue相对应。这里的逻辑就是开启一个请求缓存的线程,开启指定数量的获取网络请求的线程,至于队列中的数据是从何而来,这个我们待会儿分析,先看看NetworkDispatcher这个线程是如何运行的:
public void run() {
Process.setThreadPriority(Process.THREAD_PRIORITY_BACKGROUND);
Request<?> request; //开启循环,不断的从队列中获取需要处理的请求
while (true) { long startTimeMs = SystemClock.elapsedRealtime(); // release previous request object to avoid leaking request object when mQueue is drained.
request = null; try { // Take a request from the queue.
request = mQueue.take();
} catch (InterruptedException e) { //这里如果我们在外部调用了quit 会停止循环
// We may have been interrupted because it was time to quit.
if (mQuit) { return;
} continue;
} try {
request.addMarker("network-queue-take");
//如果请求已经手动取消 则移出当前正在请求的队列
// If the request was cancelled already, do not perform the
// network request.
if (request.isCanceled()) {
request.finish("network-discard-cancelled"); continue;
}
addTrafficStatsTag(request); // Perform the network request.
NetworkResponse networkResponse = mNetwork.performRequest(request);
request.addMarker("network-http-complete"); //如果服务器返回304并且已经响应过这个请求 移出当前正在请求的队列 并加入请求缓存队列
// If the server returned 304 AND we delivered a response already,
// we're done -- don't deliver a second identical response.
if (networkResponse.notModified && request.hasHadResponseDelivered()) {
request.finish("not-modified"); continue;
} // Parse the response here on the worker thread.
Response<?> response = request.parseNetworkResponse(networkResponse);
request.addMarker("network-parse-complete"); //如果request需要缓存(默认true)且response正常返回则把reponse写入缓存
// Write to cache if applicable.
// TODO: Only update cache metadata instead of entire record for 304s.
if (request.shouldCache() && response.cacheEntry != null) {
mCache.put(request.getCacheKey(), response.cacheEntry);
request.addMarker("network-cache-written");
} //对request进行标记,缓存是可用的
// Post the response back.
request.markDelivered();
mDelivery.postResponse(request, response);
} catch (VolleyError volleyError) {
volleyError.setNetworkTimeMs(SystemClock.elapsedRealtime() - startTimeMs);
parseAndDeliverNetworkError(request, volleyError);
} catch (Exception e) {
VolleyLog.e(e, "Unhandled exception %s", e.toString());
VolleyError volleyError = new VolleyError(e);
volleyError.setNetworkTimeMs(SystemClock.elapsedRealtime() - startTimeMs);
mDelivery.postError(request, volleyError);
}
}
}上面比较重要的地方我都写了注释,逻辑其实比较简单。比较重要的就是finish方法:
<T> void finish(Request<T> request) { // Remove from the set of requests currently being processed.
synchronized (mCurrentRequests) {
mCurrentRequests.remove(request);
} synchronized (mFinishedListeners) { for (RequestFinishedListener<T> listener : mFinishedListeners) {
listener.onRequestFinished(request);
}
} //这里是最关键的逻辑,如果需要缓存对该请求的响应,会拼接请求类型和url作为key
//从mWaitingRequests集合中移除对应request的队列,并全部添加到缓存队列中
if (request.shouldCache()) { synchronized (mWaitingRequests) {
String cacheKey = request.getCacheKey();
Queue<Request<?>> waitingRequests = mWaitingRequests.remove(cacheKey); if (waitingRequests != null) { if (VolleyLog.DEBUG) {
VolleyLog.v("Releasing %d waiting requests for cacheKey=%s.",
waitingRequests.size(), cacheKey);
} // Process all queued up requests. They won't be considered as in flight, but
// that's not a problem as the cache has been primed by 'request'.
mCacheQueue.addAll(waitingRequests);
}
}
}
}上面关键逻辑我写了备注,直接看是不好理解的,这个跟前面我们调用时的add方法是相关的,而上面提到的queue的数据就是来自这里:
public <T> Request<T> add(Request<T> request) { // Tag the request as belonging to this queue and add it to the set of current requests.
request.setRequestQueue(this); synchronized (mCurrentRequests) {
mCurrentRequests.add(request);
} // Process requests in the order they are added.
request.setSequence(getSequenceNumber());
request.addMarker("add-to-queue"); //如果不需要缓存,就直接添加到网络队列中并返回
// If the request is uncacheable, skip the cache queue and go straight to the network.
if (!request.shouldCache()) {
mNetworkQueue.add(request); return request;
} //这部分是重要的逻辑
//如果mWaitingRequests集合中有request这个key,则把这次的request继续添加到这个队列中
//如果这个集合中没有与request匹配的队列,则直接把request添加到缓存队列中
// Insert request into stage if there's already a request with the same cache key in flight.
synchronized (mWaitingRequests) {
String cacheKey = request.getCacheKey(); if (mWaitingRequests.containsKey(cacheKey)) { // There is already a request in flight. Queue up.
Queue<Request<?>> stagedRequests = mWaitingRequests.get(cacheKey); if (stagedRequests == null) {
stagedRequests = new LinkedList<Request<?>>();
}
stagedRequests.add(request);
mWaitingRequests.put(cacheKey, stagedRequests); if (VolleyLog.DEBUG) {
VolleyLog.v("Request for cacheKey=%s is in flight, putting on hold.", cacheKey);
}
} else { // Insert 'null' queue for this cacheKey, indicating there is now a request in
// flight.
mWaitingRequests.put(cacheKey, null);
mCacheQueue.add(request);
} return request;
}
}add方法和刚刚的finish方法应该结合一起看,方便理解。大致的流程是:当我们调用add添加请求时,会根据是否需要缓存去做不同的处理。不需要缓存的这里不赘述很好理解,需要缓存的情况下Volley实际上是会把请求缓存在mWaitingRequests这么一个集合当中,mWaitingRequests是一个HashMap对象。
这样可以保证当频繁的重复请求时会把所有的重复请求都放在一个队列中,而在finish方法中我们可以看到,当请求复用缓存的时候,会把所有相同的请求都一起添加到缓存队列中。
其实当我看到add方法中,会缓存相同请求到同一个队列中时我就有点疑惑这样做的目的到底是什么?
这个其实跟我上面一笔带过的DiskBasedCache有关联,这个上面讲过是负责缓存response的,而他缓存的容器是LinkedHashMap:
private final Map<String, CacheHeader> mEntries = new LinkedHashMap<String, CacheHeader>(16, .75f, true);
关键的原因就在于这里初始化构造的accessOrder参数,而这个参数会影响你查询的策略,false是基于插入顺序,true是基于访问顺序,具体实现方式可以自行查看LinkedHashMap的get方法。这样的话会对查询重复的元素效率提升巨大。
关于CacheDispatcher,其实他的实现跟上面的NetworkDispatcher是类似的,也是会循环的从queue中取数据,然后去缓存中查找,会根据缓存是否失效是否存在等判断查找缓存,如果没有命中缓存则会把请求添加到网络队列中。
上面还有一点需要提到的就是缓存request的队列PriorityBlockingQueue,这是一个实现了阻塞的优先级队列,其内部实际上是一个堆,而request实现了compare接口保证我们的请求是按照添加进去的顺序来决定优先级的。这个PriorityBlockingQueue具体细节我会在之后的文章里面讲解,有兴趣的也可以自行查看源码。
看完了Volley如何进行一次完整的请求以及缓存、线程、队列的流程,下面就是最重要的一点网络连接的实现,上面有提到过,真正建立连接是在HurlStack对象中的createConnection()方法进行的:
protected HttpURLConnection createConnection(URL url) throws IOException { return (HttpURLConnection) url.openConnection();
}这个实际上就是Android自带的库java.net.Url完成的请求,这个里面最重要的就是getURLStreamHandler()方法生成的handler:
static URLStreamHandler getURLStreamHandler(String protocol) {
URLStreamHandler handler = handlers.get(protocol); if (handler == null) { boolean checkedWithFactory = false; //step1 从缓存中查找对应handler
// Use the factory (if any)
if (factory != null) {
handler = factory.createURLStreamHandler(protocol);
checkedWithFactory = true;
} //step2 在指定包名下查找是否有自定义的协议
// Try java protocol handler
if (handler == null) { final String packagePrefixList = System.getProperty(protocolPathProp,"");
StringTokenizer packagePrefixIter = new StringTokenizer(packagePrefixList, "|"); while (handler == null &&
packagePrefixIter.hasMoreTokens()) {
String packagePrefix = packagePrefixIter.nextToken().trim(); try {
String clsName = packagePrefix + "." + protocol + ".Handler";
Class<?> cls = null; try {
ClassLoader cl = ClassLoader.getSystemClassLoader();
cls = Class.forName(clsName, true, cl);
} catch (ClassNotFoundException e) {
ClassLoader contextLoader = Thread.currentThread().getContextClassLoader(); if (contextLoader != null) {
cls = Class.forName(clsName, true, contextLoader);
}
} if (cls != null) {
handler =
(URLStreamHandler)cls.newInstance();
}
} catch (ReflectiveOperationException ignored) {
}
}
} //step3 通过不同的协议通过反射创建对应的handler,http请求由okhttp执行
// Fallback to built-in stream handler.
// Makes okhttp the default http/https handler
if (handler == null) { try { // BEGIN Android-changed
// Use of okhttp for http and https
// Removed unnecessary use of reflection for sun classes
if (protocol.equals("file")) {
handler = new sun.net.www.protocol.file.Handler();
} else if (protocol.equals("ftp")) {
handler = new sun.net.www.protocol.ftp.Handler();
} else if (protocol.equals("jar")) {
handler = new sun.net.www.protocol.jar.Handler();
} else if (protocol.equals("http")) {
handler = (URLStreamHandler)Class.
forName("com.android.okhttp.HttpHandler").newInstance();
} else if (protocol.equals("https")) {
handler = (URLStreamHandler)Class.
forName("com.android.okhttp.HttpsHandler").newInstance();
} // END Android-changed
} catch (Exception e) { throw new AssertionError(e);
}
} synchronized (streamHandlerLock) {
URLStreamHandler handler2 = null; // Check again with hashtable just in case another
// thread created a handler since we last checked
handler2 = handlers.get(protocol); if (handler2 != null) { return handler2;
} // Check with factory if another thread set a
// factory since our last check
if (!checkedWithFactory && factory != null) {
handler2 = factory.createURLStreamHandler(protocol);
}
if (handler2 != null) { // The handler from the factory must be given more
// importance. Discard the default handler that
// this thread created.
handler = handler2;
} // Insert this handler into the hashtable
if (handler != null) {
handlers.put(protocol, handler);
}
}
} return handler;
}这个地方稍微讲解一下Java提供为网络请求提供的库,在建立连接的时候我们会创建一个URL资源和一个URLConnection对象,而针对不同的协议会有不同的URLStreamHandler和对应的URLConnection来分别负责对协议的解析,以及与服务器的交互(数据转换等)。
上面我注释的step1和step3都比较好理解,而step2是留给用户拓展,开发自定义的通讯协议使用的,这里了解一下就行。我们需要关心的是step3,http的请求实际上是通过okhttp实现的,大家查阅资料或者看源码都能知道android4.4后原生的网络请求已经替换为okhttp了。
总结
至此,我们对Volley的分析已经结束。现在稍微总结一下,Volley实现了一套完整的符合Http语义的缓存机制,并且对性能方面有一些优化(缓存的命中、缓存的写入、重复请求的队列)。在设计中,Volley定义了大量的接口,正是由于这些设计,可以使得Volley拥有高度的扩展性,用户可以针对自己的需求自由的订制其中的实现。针对接口编程,不针对具体细节实现编程,多用组合,少用继承。许多优秀的框架也拥有同样的特性,这也是我们在平时开发过程中能够学习运用的。
作者:pengsong
链接:https://www.jianshu.com/p/00d9921309cf
共同学习,写下你的评论
评论加载中...
作者其他优质文章


