
你好,是我琉忆。
继周一(2019.2-18)发布的“PHP面试常考内容之Memcache和Redis(1)”后,这是第二篇,感谢你的支持和阅读。
本周(2019.2-18至2-22)的文章内容点为以下几点,更新时间为每周一三五,可以关注本栏持续关注,感谢你的支持。
一、什么是Memcache?
二、Memcache有什么特征?
三、Memcache的内存管理机制是什么样的?
四、Memcache和Memcached有什么区别?
五、如何操作Memcache?
六、如何使用Memcache做Session共享?
七、什么是Redis?
八、如何使用Redis?
九、使用Redis需要注意哪些问题?
十、新增:Redis和Memcache有什么不同?
十一、新增:Redis如何实现持久化?
十二、Memcache和Redis常考的面试题
本章节的内容将会被分为三篇文章进行讲解完整块内容,第一篇主要讲解一到六,第二篇主要讲解七到十一(新增了十和十一),第三篇围绕第十二点。
以下正文的部分内容来自《PHP程序员面试笔试宝典》书籍,如果转载请保留出处:
七、什么是Redis?
Redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set,有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集、并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,Redis支持各种不同方式的排序。与Memcached一样,为了保证效率,数据都是缓存在内存中。区别是Redis会周期性地把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
Redis的出现,很大程度上弥补了Memcached这类key/value存储的不足,在部分场合可以对关系数据库起到很好的补充作用。它提供了Java、C/C++、C#、PHP、JavaScript、Perl、Object-C、Python、Ruby、Erlang等客户端,使用起来很方便。
Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。存盘可以有意无意地对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。
八、如何使用Redis?
set方法的使用示例:
<?php
$Redis = new Redis();
$Redis->connect('127.0.0.1', 6378);
$res = $Redis->set(aaa,"bbbb");
var_dump($res); //结果:bool(true)
?>以下仅罗列各使用方法的汇总,具体使用方法可以参考示例和PHP的写法进行使用:
1、字符串类型的使用方法
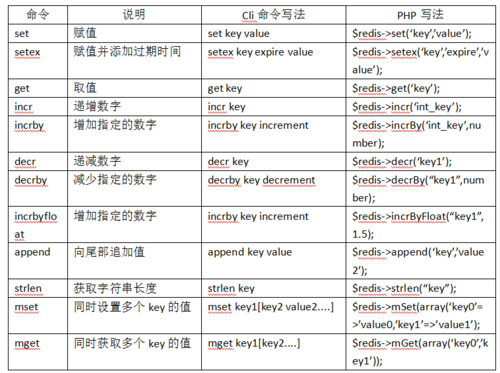
2、Hash类型使用方法
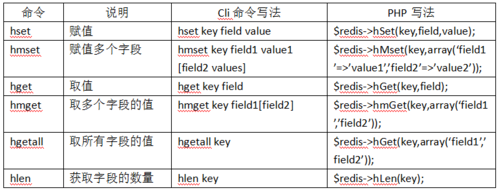
3、List类型使用方法
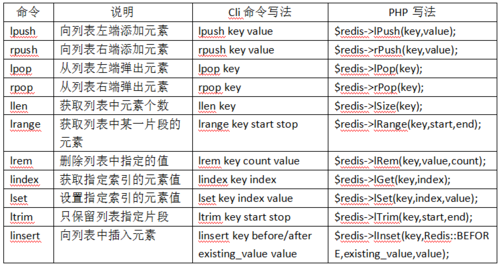
4、Set类型使用方法
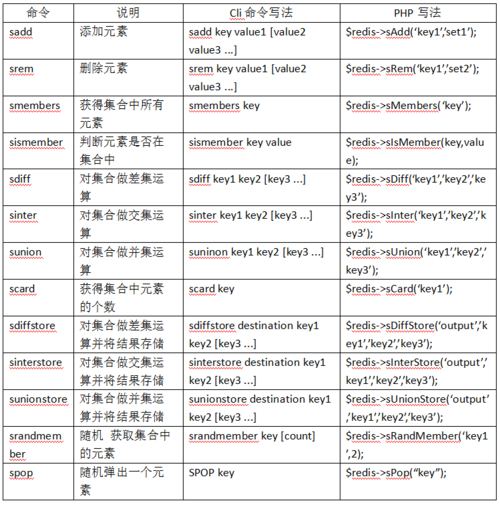
5、Sorted set类型使用方法
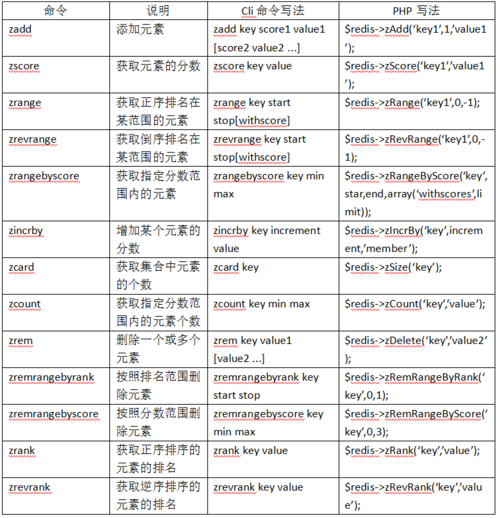
九、使用Redis需要注意哪些问题?
与MySQL一样,Redis在使用过程中,也会碰到很多的问题,适当的技巧和优化将大大提高Redis的使用性能,提高服务的质量。现将常见的一些问题总结如下:
1.停止使用keys *操作
keys*操作执行速度将会变慢。因为keys命令的时间复杂度是O(n),其中n是要返回的keys的个数,由此可见这个命令的复杂度就取决于数据量的大小了。当数据量比较大时,在这个操作执行期间,其他任何命令在实例中都无法执行,严重影响了性能。
可以使用scan命令来代替,scan命令通过增量迭代的方式来扫描数据库。
2.定位Redis速度降低的原因
使用INFO commandstats命令来查看所有命令的统计情况,如命令执行了多少次,执行命令所耗费的毫秒数等信息。
3.尽量使用hash的存储方式
Hash的存储方式会大大提高操作效率。
4.设置key值的存活时间
无论什么时候,只要有可能就利用key超时的优势。一个很好的例子就是存储一些诸如临时认证key之类的东西。当你去查找一个授权key时——以OAUTH为例——通常会得到一个超时时间。这样在设置key的时候,设成同样的超时时间,Redis就会自动为你清除!而不再需要使用KEYS *来遍历所有的key了。
5.对于很重要的数据,请使用异常处理机制
如果必须确保关键性的数据可以被放入Redis的实例中,那么请使用异常处理机制。几乎所有的Redis客户端采用的都是“发送即忘”策略,因此经常需要考虑一个 key 是否真正被放到Redis数据库中了。加入异常处理机制是程序健壮性保障的前提。
6.多实例应用
无论什么时候,只要有可能就分散多Redis实例的工作量。Redis集群允许基于key范围分离出部分包含主/从模式的key。多实例是保证集群资源最大利用,集群稳定的重要保障。
十、Redis和Memcache有什么不同?
(1)数据结构:Memcache只支持key value存储方式,Redis支持更多的数据类型,比如Key value、hash、list、set、zset;
(2)多线程:Memcache支持多线程,Redis支持单线程;CPU利用方面Memcache优于Redis;
(3)持久化:Memcache不支持持久化,Redis支持持久化;
(4)内存利用率:Memcache高,Redis低(采用压缩的情况下比Memcache高);
(5)过期策略:Memcache过期后,不删除缓存,会导致下次取数据数据的问题,Redis有专门线程,清除缓存数据;
十一、Redis如何实现持久化?
Redis是一个支持数据持久化的内存数据库,可以对Redis设置,让Redis周期性的把更新的数据同步到磁盘中保证数据持久化。
Redis支持的持久化策略有两种,分别是:RDB和AOF。
1、RDB持久化
RDB持久化的意思是:指定的时间间隔内保存数据快照。Redis默认的持久化方式就是RDB。
RDB的工作原理为当 Redis 需要做持久化时,Redis 会 fork 一个子进程,子进程将数据写到磁盘上一个临时 RDB 文件中。当子进程完成写临时文件后,将原来的 RDB 替换掉,这样的好处就是可以 copy-on-write。
在Redis.conf 文件中RDB持久化的默认设置为:
save 300 10 #300秒内,如果超过10个key被修改,则发起快照保存;
RDB的优点:
因为RDB的持久化方式是可以在时间间隔内进行数据快照,所以RDB非常适合用于灾难恢复。例如设置每小时备份一次,或每天备份一次总的,从而方便数据的追溯和还原到不同版本。
RDB的缺点:
(1)特定时间下才进行一次持久化,所以易丢失数据;例如你设置30分钟备份一次数据,但是如果Redis服务器发生故障,那么就可能丢失好几分钟的数据没能备份。
(2)庞大数据时,保存时会出现性能问题。
2、AOF持久化
AOF:先把命令追加到操作日志的尾部,保存所有历史操作。
AOF的工作原理是,每一个写命令都通过write函数追加到 appendonly.aof 中,当Redis出现故障重启时,将会读取 AOF 文件进行“重放”以恢复到 Redis 关闭前的状态。
Redis.conf 对AOF持久化的设置:
Redis.conf appendonly yes #开启全程持久化 appendfsync always #每次有数据修改发生时都会写入AOF文件。 appendfsync everysec #每秒钟同步一次,该策略为AOF的缺省策略。
AOF的优点:
(1)数据非常完整,故障恢复丢失数据少;
(2)可对历史操作进行处理。
AOF的缺点:
(1)在备份相同的数据集时,AOF的文件体积大于RDB的文件体积;
(2)AOF使用fsync策略的话,AOF的速度可能会慢于RDB。
3、选择哪一种Redis做持久化策略更好?
因为Redis是支持同时开启RDB和AOF持久化策略的,所以数据备份安全性考虑的话两者都可以设置,当Redis重启后会优先使用AOF恢复数据,保证丢失的数据最少。
如果要二选一的话,可以根据自己的业务进行选择:
(1)如果对数据的丢失要求很高,可以选择AOF持久化策略;
(2)AOF对Redis执行的每一条命令都会追加到磁盘中,会降低Redis的性能,如果对Redis的性能有所考虑,可以选择RDB持久化策略;
(3)考虑数据灾难恢复的情况,可以选择RDB持久化策略。
这里还有一个常考的Redis相关的问题:Redis如何实现缓存集群?
预告:PHP面试常考内容之Memcache和Redis(3)将于本周五(2019.2-22)更新。
以上内容摘自《PHP程序员面试笔试宝典》书籍,该书已在天猫、京东、当当等电商平台销售。
更多PHP相关的面试知识、考题可以关注公众号获取:琉忆编程库
对本文有什么问题或建议都可以进行留言,我将不断完善追求极致,感谢你们的支持。
共同学习,写下你的评论
评论加载中...
作者其他优质文章


