
一、Mango实现数据表分片
表分片通常也被称为分表,散表。
当某张表的数据量很大时,sql执行效率都会变低,这时通常会把大表拆分成多个小表,以提高sql执行效率。 我们将这种大表拆分成多个小表的策略称之为表分片。
要实现表分片,需要定义一个表分片类,这个类要实现 TableShardingStrategy 接口中的 getTargetTable 方法。
getTargetTable方法是表分片策略的核心,共两个输入参数,输出则为最终需要访问的表名字,所以我们通过实现getTargetTable方法计算最终需要访问的表名字。
第1个参数table为@DB注解中table参数所定义的全局表名。
第2个参数是自定义传入的参数,这里我们使用uid计算如何分表,所以第2个参数是uid。
需要注意的是,第2个参数是一个泛型参数,这里由于uid是整形数字,所以类型定义为Integer。
实例代码:
(1)OrderTableShardingStrategy.java
package com.lhf.mango.tableShard;
import org.jfaster.mango.sharding.TableShardingStrategy;
/**
* @ClassName: OrderTableShardingStrategy
* @Desc: 实现表分片,需要实现TableShardingStrategy接口
* getTargetTable方法是表分片策略的核心,共两个输入参数,输出则为最终需要访问的表名字,所以我们通过实现getTargetTable方法计算最终需要访问的表名字。
*
* 第1个参数table为@DB注解中table参数所定义的全局表名,这里是t_order。
*
* 第2个参数是自定义传入的参数,这里由于我们要使用uid计算如何分表,所以第2个参数是uid
* @Author: liuhefei
* @Date: 2018/12/21 11:29
*/
public class OrderTableShardingStrategy implements TableShardingStrategy<Integer> {
/**
* uid小于等于1000时,使用t_order_0表
* uid大于1000时,时使用t_order_1表
* @param table
* @param uid
* @return
*/
public String getTargetTable(String table, Integer uid) {
int num = uid <= 100 ? 0 : 1;
return table + "_" + num;
}
}(2)OrderTableShardingMain.java
package com.lhf.mango.tableShard;
import com.google.common.collect.Lists;
import com.lhf.mango.dao.TableShardingOrderDao;
import com.lhf.mango.entity.Order;
import com.lhf.mango.util.RandomUtils;
import org.jfaster.mango.datasource.DriverManagerDataSource;
import org.jfaster.mango.operator.Mango;
import javax.sql.DataSource;
import java.util.List;
/**
* @ClassName: OrderTableShardingMain
* @Desc: 实现表分片
* @Author: liuhefei
* @Date: 2018/12/21 11:36
*/
public class OrderTableShardingMain {
public static void main(String[] args){
//定义数据源
String driverClassName = "com.mysql.jdbc.Driver";
String url = "jdbc:mysql://localhost:3306/mango_example?useSSL=false";
String username = "root";
String passowrd = "root";
DataSource ds = new DriverManagerDataSource(driverClassName,url, username, passowrd);
Mango mango = Mango.newInstance(ds); //使用数据源初始化mango
TableShardingOrderDao tableShardingOrderDao = mango.create(TableShardingOrderDao.class);
Order order = new Order();
List<Integer> uids = Lists.newArrayList(1, 2, 10020, 10086);
for (Integer uid : uids) {
String id = RandomUtils.randomStringId(10); // 随机生成10位字符串ID
order.setId(id);
order.setUid(uid);
order.setPrice(100);
order.setStatus(1);
tableShardingOrderDao.addOrder(order);
System.out.println(tableShardingOrderDao.getOrdersByUid(uid));
}
}
}二、Mango实现数据库分片
数据库分片通常也被称为分库,散库等。
当我们在某个库中,把某张大表拆分成多个小表后还不能满足性能要求,这时我们需要把一部分拆分的表挪到另外一个库中,以提高sql执行效率。
要实现数据库分片,需要定义一个数据库分片类,这个类要实现DatabaseShardingStrategy 接口中的 getDataSourceFactoryName 方法。
getDataSourceFactoryName方法是数据库分片策略的核心,返回最终请求的数据源工厂名称。
而getDataSourceFactoryName方法的输入参数是一个自定义传入的参数,这里由于我们要使用uid计算如何分库,所以参数为uid。
需要注意的是,输入参数是一个泛型参数,这里由于uid是整形数字,所以类型定义为Integer。
我们使用 @Sharding 注解中的databaseShardingStrategy参数,将数据库分片策略与DAO接口进行绑定。
引入了 @ShardingStrategy 接口,实现@ShardingStrategy接口等与同时实现@DatabaseShardingStrategy接口与@TableShardingStrategy接口。。
一维度分片策略:使用一个字段属性作为分片策略的计算参数;
多维度分片策略:同时使用多个分片策略计算参数,不同的方法指定不同的分片策略;
实例代码:
(1)OrderDatabaseShardingStrategy.java
package com.lhf.mango.databaseShard;
import org.jfaster.mango.sharding.DatabaseShardingStrategy;
/**
* @ClassName: OrderDatabaseShardingStrategy
* @Desc: 数据库分片策略
* 数据库要要实现分片,需要实现DatabaseShardingStrategy 接口中的 getDataSourceFactoryName 方法。
* getDataSourceFactoryName方法是数据库分片策略的核心,返回最终请求的数据源工厂名称。
* 而getDataSourceFactoryName方法的输入参数是一个自定义传入的参数,这里由于我们要使用uid计算如何分库,所以参数为uid
*
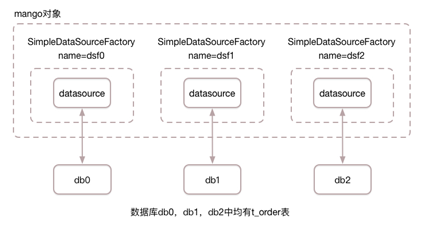
* 在 初始化数据库源工厂 中我们定义了dsf0,dsf1,dsf2共3个数据源工厂,分别对应db0,db1,db2这3个数据库。
* 所以当我们想访问db0中的t_order表时,我们只需要让getDataSourceFactoryName方法返回dsf0;
* 当我们想访问db1中的t_order表时,我们只需要让getDataSourceFactoryName方法返回dsf1,并以此类推。
* @Author: liuhefei
* @Date: 2018/12/21 14:14
*/
public class OrderDatabaseShardingStrategy implements DatabaseShardingStrategy<Integer> {
public String getDataSourceFactoryName(Integer uid) {
return "dsf" + uid % 3;
}
}(2)OrderDatabaseShardingMain.java
package com.lhf.mango.databaseShard;
import com.google.common.collect.Lists;
import com.lhf.mango.dao.DatabaseShardingOrderDao;
import com.lhf.mango.entity.Order;
import com.lhf.mango.util.RandomUtils;
import org.jfaster.mango.datasource.DataSourceFactory;
import org.jfaster.mango.datasource.DriverManagerDataSource;
import org.jfaster.mango.datasource.SimpleDataSourceFactory;
import org.jfaster.mango.operator.Mango;
import javax.sql.DataSource;
import java.util.ArrayList;
import java.util.List;
/**
* @ClassName: OrderDatabaseShardingMain
* @Desc: 数据库分片通常也被称为分库,散库等。
* 当我们在某个库中,把某张大表拆分成多个小表后还不能满足性能要求,这时我们需要把一部分拆分的表挪到另外一个库中,以提高sql执行效率。
* 3个独立数据库db0,db1,db2中,各有1张t_order表,在读写t_order表时,我们按照用户ID(后续简称uid)纬度进行数据库分片:
*
* uid模3为0的请求落在数据库db0
* uid模3为1的请求落在数据库db1
* uid模3为2的请求落在数据库db2
*
* @Author: liuhefei
* @Date: 2018/12/21 14:14
*/
public class OrderDatabaseShardingMain {
public static void main(String[] args){
String driverClassName = "com.mysql.jdbc.Driver";
String username = "root";
String password = "root";
int dbCount = 3;
//初始化数据源工厂
/**
* 名字为dsf0的数据源工厂连接数据库mongo_example0
* 名字为dsf1的数据源工厂连接数据库mongo_example1
* 名字为dsf2的数据源工厂连接数据库mongo_example2
*/
List<DataSourceFactory> dsfs = new ArrayList<DataSourceFactory>();
for(int i=0;i<dbCount;i++){
String name = "dsf" + i;
String url = "jdbc:mysql://localhost:3306/mango_example" + i + "?useSSL=false";
System.out.println("name = " + name + " url = " + url);
DataSource ds = new DriverManagerDataSource(driverClassName, url, username, password);
DataSourceFactory dsf = new SimpleDataSourceFactory(name, ds);
dsfs.add(dsf);
}
Mango mango = Mango.newInstance(dsfs);
DatabaseShardingOrderDao orderDao = mango.create(DatabaseShardingOrderDao.class);
List<Integer> uids = Lists.newArrayList(1,2,3,4,5,6,7,8,9);
for(Integer uid : uids){
String id = RandomUtils.randomStringId(10); //随机生成10位字符串ID
Order order = new Order();
order.setId(id);
order.setUid(uid);
order.setPrice(1000);
order.setStatus(1);
orderDao.addOrder(order); //插入订单
System.out.println(orderDao.getOrdersByUid(uid)); //查看订单
}
}
}如果想要同时实现分表和分库功能,需要实现ShardingStrategy接口。
ShardingStrategy接口同时继承DatabaseShardingStrategy, TableShardingStrategy接口,然后分别实现getDataSourceFactoryName方法和getTargetTable方法即可。
关于更多分表分库的实例,在这里不再展示,后面会放到github上。
三、Mango函数式声明
我们需要将java中的列表,集合,自定义类映射到关系型数据库的某个字段中,直接插入取出显然是不行的,这时我们就需要使用函数式调用功能,将这些数据库不能识别的类型转化为数据库能够识别的类型插入,后续取出时再通过函数式调用转化为java中的复杂类型。
(1)列表与字符串互转
@Getter(IntegerListToStringFunction.class) 将整型列表转化为字符串
@Setter(StringToIntegerListFunction.class) 将字符串转化为整型列表
(2)枚举与数字互转
@Getter(EnumToIntegerFunction.class) 将枚举对象转化为数字
@Setter(IntegerToEnumFunction.class) 将数字转化为枚举对象
(3)复杂类与字符串互转
@Getter(ObjectToGsonFunction.class) 将任意对象转化为json字符串
@Setter(GsonToObjectFunction.class) 将json字符串转化为任意对象
实例代码:
package com.lhf.mango.entity;
import org.jfaster.mango.annotation.Getter;
import org.jfaster.mango.annotation.Setter;
import org.jfaster.mango.invoker.function.IntegerListToStringFunction;
import org.jfaster.mango.invoker.function.StringToIntegerListFunction;
import java.util.List;
/**
* @ClassName: Teacher
* @Desc: 老师表,老师与学生的关系是一对多
* @Author: liuhefei
* @Date: 2019/1/30 14:50
*/
public class Teacher {
private Integer id;
private String name;
private List<Integer> studentIds;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Getter(IntegerListToStringFunction.class) //将整型列表转化为字符串
public List<Integer> getStudentIds() {
return studentIds;
}
@Setter(StringToIntegerListFunction.class) //将字符串转化整型列表
public void setStudentIds(List<Integer> studentIds) {
this.studentIds = studentIds;
}
}四、Mango拦截器
拦截器是mango框架中一个非常重要的功能,它为mango框架提供了扩展插件的可能。
当我们为mango框架添加拦截器后,最终执行的SQL会依次通过这些拦截器后再被执行。 所以我们可以通过拦截器对最终执行的SQL进行各种操作,如修改SQL,记录SQL等。
通过自定义拦截器,我们可以为mango框架扩展出许许多多的插件,最为常用的 分页查询 插件就可以通过拦截器来实现。
mango框架将拦截器分为了两类:查询拦截器与更新拦截器。
查询拦截器:所有查询请求最终需要执行的SQL都需要依次通过查询拦截器处理。
要实现一个自己的查询拦截器,需要定义一个类(MyQueryInterceptor),并继承 QueryInterceptor 类;
在初始化mango对象时,需要调用addInterceptor方法将我们的拦截器MyQueryInterceptor添加到了mango对象中。
public class MyQueryInterceptor extends QueryInterceptor {
public void interceptQuery(
BoundSql boundSql,
List<Parameter> parameters,
DataSource dataSource) {
System.out.println("sql: " + boundSql.getSql());
System.out.println("args: " + boundSql.getArgs());
}
}
QueryInterceptor中的interceptQuery方法有3个输入参数:
1、BoundSql封装了最终将要被执行的SQL
2、List<Parameter>封装了被执行方法的参数列表信息
3、DataSource则是SQL执行时所使用的数据源
更新拦截器:所有更新请求最终需要执行的SQL都需要依次通过更新拦截器处理。
要实现一个自己的更新拦截器,需要定义一个类(MyUpdateInterceptor),并继承继承 UpdateInterceptor 类。
在初始化mango对象时,我们调用addInterceptor方法将我们的拦截器(MyUpdateInterceptor)添加到了mango对象中。
public class MyUpdateInterceptor extends UpdateInterceptor {
public void interceptUpdate(
BoundSql boundSql,
List<Parameter> parameters,
SQLType sqlType,
DataSource dataSource) {
System.out.println("sql: " + boundSql.getSql());
System.out.println("args: " + boundSql.getArgs());
}
}
UpdateInterceptor中的interceptUpdate方法有4个输入参数:
1、BoundSql封装了最终将要被执行的SQL
2、List<Parameter>封装了被执行方法的参数列表信息
3、SQLType封装了被执行SQL的类型
4、DataSource则是SQL执行时所使用的数据源
五、Mango集成cache
mango自身不依赖任何缓存工具,mango对外提供SimpleCacheHandler抽象类,你只需继承SimpleCacheHandler抽象类,并实现其中的缓存操作代码(memcached,redis,直接内存等均可),就能享受mango带来的缓存操作便利。
CacheHandler抽象类一共有4个需要实现的抽象方法,它们分别对应着封装缓存的操作:
(1)Object get(String key, Type type) ,根据单个key值从缓存中查找数据,type为返回对象的类型
(2)Map<String, Object> getBulk(Set<String> keys, Type type) ,根据多个key值从缓存中查找数据,返回key-value对应的map,type为map中value对象的类型
(3)void set(String key, Object value, int exptimeSeconds),向缓存中设置数据,其中exptimeSeconds为缓存失效时间,单位为秒。
(4)void delete(String key) ,根据单个key值从缓存中删除数据。
初始化mango对象
DataSource ds = new DriverManagerDataSource(driverClassName, url, username, password);
Mango mango = Mango.newInstance(ds);
mango.setCacheHandler(new MockRedisHandler());
正常初始化mango对象后,只需要通过setCacheHandler方法传入一个实现了CacheHandler接口的对象即可,这里我们使用的是自定义的Redis实现的MockRedisHandler。
实例代码:
package com.lhf.mango.dao;
import com.lhf.mango.entity.User;
import org.jfaster.mango.annotation.*;
import org.jfaster.mango.operator.cache.Hour;
import java.util.List;
/**
* @ClassName: UserCacheDao
* @Desc: Mango缓存使用
* @Cache表示需要使用缓存,参数prefix表示key前缀,比如说传入uid=1,那么缓存中的key就等于user_1,参数expire表示缓存过期时间,Hour.class表示小时,配合后面的参数num=2表示缓存过期的时间为2小时。
* @CacheBy用于修饰key后缀参数,在delete,update,getUser方法中@CacheBy都是修饰的uid,所以当传入uid=1时,缓存中的key就等于user_1。
* @CacheIgnored表示该方法不操作缓存。需要注意的是,如果使用了@Cache注解,@CacheBy和@CacheIgnored二者必须有一个存在。
*
* @Author: liuhefei
* @Date: 2018/12/21 18:15
*/
@DB
@Cache(prefix = "user", expire = Hour.class, num = 2)
public interface UserCacheDao {
@CacheIgnored //不使用缓存
@SQL("insert into user(name, age, gender, money, update_time) values(:name, :age, :gender, :money, :updateTime)")
public int insert(User user);
@SQL("insert into user(name, age, gender, money, update_time) values(:1.name, :1.age, :1.gender, :1.money, :1.updateTime)")
public int insertUser(@CacheBy("name") User user); //使用User对象的name属性作为key后缀
@SQL("delete from user where id =:1")
public int delete(@CacheBy int id );
@SQL("update user set name = :2 where id =:1")
public int update(@CacheBy int id, String name);
@SQL("select * from user where id=:1")
public User getUser(@CacheBy int id);
@SQL("select * from user where id in (:1)")
public List<User> getUserList(@CacheBy List<Integer> ids);
@SQL("select id, name from user where id=:1 and name=:2")
public User getByUidAndName(@CacheBy int id, @CacheBy String name); //同时使用id和name两个字段来做缓存
}今天分享就到这里,2019年1月30日于深圳。后续还会继续更新关于Mango的相关知识,相关代码后面会放到github上,地址:https://github.com/JavaCodeMood
准备回家过年,提前预祝各位走过路过的大佬春节快乐,阖家欢乐!
共同学习,写下你的评论
评论加载中...
作者其他优质文章


