
在编写Python应用程序时,缓存是非常重要的。使用缓存可以避免重复计算数据或者访问速度较慢的数据库,这样可以极大地提高性能。
从简单的字典到更完整的数据结构,Python提供了内置缓存的可能性,例如 functools.lru_cache。后者可以通过最近最少使用算法)来缓存任何项,从而限制缓存大小。
然而,根据Python进程,这些数据结构被定义为 local 。当应用程序的多个副本在大型平台上运行时,使用内存中的数据结构时是不允许共享缓存内容的。这对于大规模和分布式应用来说,可能是一个问题。
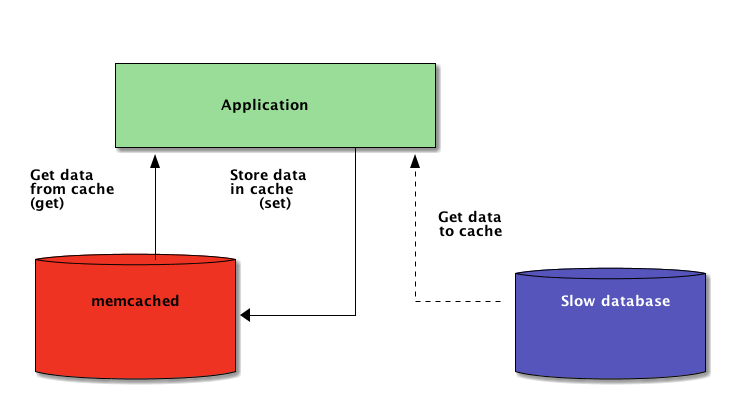
因此,当一个系统分布在网络上时,其也需要一个分布在网络上的内存。 现在,很多网络服务器提供了缓存功能——我们已经介绍了 如何在Django中使用Redis进行缓存。
正如你将在本教程中看到的,memcached 是分布式缓存的另一种极好的选择。 在快速介绍了基本的memcached 用法后, 你将会了解到诸如“缓存和设置”之类的高级模式,并采用回退缓存来避免冷缓存的性能问题。
安装 memcached
Memcached适用于许多平台:
如果你是在Linux系统上运行,你可以通过
apt-get install memcached或者yum install memcached命令进行安装。其将从预先构建的包中安装memcached,但是你也可以从如下所述的源代码中构建memcached。对于 macOS系统,使用 Homebrew 是最简单的选择。安装好Homebrew包管理器后,只需要运行
brew install memcached即可。在Windows系统中,你需要自己编译memcached ,或者找到 预编译的二进制文件。
安装好后,只需要调用memcached命令就可以启动memcached :
$ memcached
在通过Python-land和memcached进行交互前,你需要安装一个memcached client 库。在接下来的部分,你将了解到如何进行上述操作,并会了解一些基本的访问缓存的操作。
使用Python存储和检索缓存值
即使你从未使用过 memcached,它也是相当好理解的。它主要提供了一个巨大的网络可用字典。这个字典有一些不同于传统Python字典的属性,主要有:
键和值必须是字节
键和值在过期后自动删除
因此,与memcached 交互的两个基本操作是 set 和 get。正如您可能已经猜到的,这两个基本操作分别用于分配键值或者获取键值。
我建议在与memcached 进行交互时,可首选Python库pymemcache。你可以简单地使用pip命令来安装该库:
$ pip install pymemcache
下面的代码展示了如何连接到memcached 并将其作为Python应用程序的网络分布式缓存:
>>> from pymemcache.client import base# Don't forget to run `memcached'before running this next line:>>> client = base.Client(('localhost', 11211))# Once the client is instantiated, you can access the cache:>>> client.set('some_key', 'some value')# Retrieve previously set data again:>>> client.get('some_key')'some value'memcached 网络协议非常简单,并且可以快速实现,这使其可以用来存储数据,否则从规范的数据源检索数据或者重新计算数据会非常慢:
虽然很简单,但是这个示例允许跨网络存储键值对,并通过应用程序的多个分布式运行副本访问它们。这很简单,但是很强大。这是优化应用程序的第一步。
缓存数据自动过期
当在 memcached中存储数据时,可以设置一个过期时间——即 memcached 中保留键值的最大秒数。在该缓存时间过后,memcached 会从缓存中自动删除键值。
你应该将缓存时间设置为多少呢? 当然并没有什么神奇的缓存时间,其完全取决于你正在处理的数据和应用程序的类型。因此,缓存时间可能是几秒钟,或者是几小时。
Cache invalidation定义了何时删除缓存,因为其与当前的数据不同步,这也是你的应用程序需要处理的问题,特别是呈现的数据很陈旧,或者需要避免使用state的时候。
这里同样不存在什么神奇的设置;这取决于你正在构建的应用程序的类型。然而,有几个外部因素需要处理——在上面的示例中我们还没涉及到这些因素。
缓存服务器不能无限增长——内存是有限的资源。因此,一旦缓存服务器需要更多的空间去存储其他东西,它就会刷新键值。
一些键值也可能会过期,因为其已达到过期时间(有时也被称为“生存时间”或者TTL)。 在这些情况下会出现数据丢失,此时需要再次查询规范的数据源。
这听起来比实际情况复杂。在使用Python中的memcached时,通常可以使用以下模式:
from pymemcache.client import base
def do_some_query(): # Replace with actual querying code to a database,
# a remote REST API, etc.
return 42# Don't forget to run `memcached'before running this code
client = base.Client(('localhost', 11211))result = client.get('some_key')if result is None: # The cache is empty, need to get the value
# from the canonical source:
result = do_some_query() # Cache the result for next time:
client.set('some_key', result)# Whether we needed to update the cache or not,# at this point you can work with the data# stored in the `result` variable:print(result)注意: 由于正常的刷新操作,因此必须处理丢失的键值。冷缓存的场景也必须处理,即memcached刚刚启动的时候。在这种情况下,缓存将完全为空,需要在每次请求时重新填充缓存。
这意味着你应该视任何缓存的数据为暂时的,而且永远不要期望缓存中包含你之前写入的值。
预热冷缓存
一些冷缓存的场景是无法预防的,例如 memcached 崩溃的时候。但有些是可以预防的,例如迁移到一个新的memcached服务器。
当预测到冷缓存场景可能会出现时,最好能够避免。当缓存需要被重新填充时,意味着被规范存储的缓存数据,会突然之间被缺少缓存数据的缓存用户大量攻击 (也被称为惊群效应)。
pymemcache 提供了一个名为FallbackClient的类,其可以帮助实现如下所示的场景:
from pymemcache.client import basefrom pymemcache import fallbackdef do_some_query():
# Replace with actual querying code to a database,
# a remote REST API, etc.
return 42# Set `ignore_exc=True` so it is possible to shut down# the old cache before removing its usage from # the program, if ever necessary.old_cache = base.Client(('localhost', 11211), ignore_exc=True)
new_cache = base.Client(('localhost', 11212))
client = fallback.FallbackClient((new_cache, old_cache))
result = client.get('some_key')if result is None: # The cache is empty, need to get the value
# from the canonical source:
result = do_some_query() # Cache the result for next time:
client.set('some_key', result)
print(result)FallbackClient根据顺序查询传递给构造函数的旧缓存。在这种情况下,新的缓存服务器将首先被查询。在缓存丢失的情况下,将查询旧的缓存服务器——避免回退到主要数据源的可能。
如果设置了任何键,则将其设置为新缓存。一段时间后,旧缓存就可以停止使用了,FallbackClient可以直接被替换为new_cache客户端。
检查和设置
当与远程缓存交互时,通常会出现并发问题:可能会有多个客户端同时访问同一个键。memcached 提供了check和set 操作,可简称为CAS,可有助于解决这个问题。
最简单的例子是一个应用程序想要计算其拥有的用户量。每当有一个访问者进行连接时,计数器就加1。采用memcached的一个简单实现如下:
def on_visit(client): result = client.get('visitors') if result is None: result = 1
else: result += 1
client.set('visitors', result)但是,如果该应用程序的两个实例试图同时更新计数器时,会发生什么情况?
首次调用client.get('visitors') 将为上述两个实例返回相同数量的访问者,假设是42。然后二者均加1,计算结果为43,并将访问人数设置为43。这个数据是错误的,结果应该为44,即42+1+1。
对于解决并发问题,memcached 的CAS操作非常方便。下面的代码片段为正确的解决方案:
def on_visit(client): while True: result, cas = client.gets('visitors') if result is None: result = 1
else: result += 1
if client.cas('visitors', result, cas): breakgets返回值,就像get方法一样,也返回CAS value。
该值中的内容不相关,但可供下一个方法was调用。这个方法等价于set操作,但值如果在gets操作后发生了改变,则意味着该方法失败了。一旦成功,将会打破循环。否则,将重头开始重新启动操作。
在应用程序的两个实例试图同时更新计数器的场景中,第二个实例获取了调用client.as返回的False值,并重新进行循环。这次其将43作为检索值,并将值增加至44,同时将成功调用cas,从而解决我们的问题。
递增计数器是解释CAS如何工作的一个非常有趣的示例,因为它非常简单。然而,memcached 也提供了incr和decr 方法,用于在单个请求中,对整数进行递增或者递减,而不是多次调用gets/can。在实际的应用程序中,gets和cas 用于更复杂的数据类型或者操作。
大多数远程缓存服务器和数据存储均提供了这样一种机制来防止并发问题。了解这些情况并正确使用其特性是非常重要的。
缓存之外
本文演示的简单方法向你展示了采用memcached 来提高Python应用程序的性能是多么容易。
仅仅通过采用两个基本的“set”和“get”操作,你通常可以加速数据检索,或者避免一次一次地重新计算结果。使用memcached,你可以共享跨越大量分布式节点的缓存。
在本教程中了解到的其他更高级的模式,如Check And Set (CAS) 操作,允许跨越多个Python线程或者进程同步更新存储在缓存中的数据,同时可以避免数据被损坏。
如果你有兴趣学习更多关于编写更快、伸缩性更灵活的Python应用程序的高级技术,请查看Python扩展。其涵盖了许多高级主题,例如网络分发、排队系统、分布式散列和代码分析。
译文出处:https://www.zcfy.cc/article/python-memcached-efficient-caching-in-distributed-applications
共同学习,写下你的评论
评论加载中...
作者其他优质文章



