
集合(Set)及其函数
集合是一个无序的、无重复元素的序列。
1 list = {1, 3, 6, 5, 7, 9, 11, 3, 7} # 定义集合方式一
2 list1 = set([1, 3, 6, 5, 7, 9, 11, 3, 7]) # 定义集合方式二
3 list2 = set() # 定义一个空集合
4
5 print(list1, list) # 打印后可看到,集合中的元素已自动去重
6 print(3 in list) # 判断一个元素是否在集合中,返回bool值
7 print(20 not in list1) # 判断一个元素是否不在集合中,返回bool值
8 list1.add(99) # 新增元素
9 list1.update([10, 20, 30, 2]) # 新增多项
10 list1.remove(3) # 删除一个元素,若元素不存在则报错
11 print(list1.discard(8)) # 删除一个元素,若元素不存在则不做任何操作
12 print(len(list1)) # 计算集合中元素的个数
13 print(list1.pop()) # 从集合中随机弹出一个元素
14 list.clear() # 清空集合集合的运算
1 list1 = set([1, 3, 6, 5, 7, 9, 11, 3, 7]) 2 list2 = set([2, 4, 6, 8, 3, 5]) 3 print(list1, list2) 4 5 # 交集 6 print(list1.intersection(list2)) 7 print(list1 & list2) 8 # 并集 9 print(list1.union(list2)) 10 print(list1 | list2) 11 # 差集 12 print(list1.difference(list2)) 13 print(list1 - list2) 14 # 对称差集 15 print(list1.symmetric_difference(list2)) 16 print(list1 ^ list2) 17 18 # 是否为子集 是否为父集 19 list3 = set([9, 11]) 20 print(list3.issubset(list1)) 21 print(list1.issuperset(list3)) 22 23 # 若两个集合的交集为空 返回true 24 list4 = set([20, 30]) 25 print(list1.isdisjoint(list4)) 26 print(list1.isdisjoint(list2))
文件(File)操作
在开发中经常会有读写文件的需求,相关的代码实现如下:
文件的打开模式
1 open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
| mode | description |
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(不推荐)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
文件的读操纵、写操作、追加操作、按行读取文件
1 # read 直接读文件全文
2 f = open('test', 'r', encoding='utf-8') # 文件句柄
3 data = f.read()
4 print(data)
5
6 # write 向文件中写
7 f = open('test1', 'w', encoding='utf-8')
8 f.write('我爱北京天安门,\n天安门上太阳升')
9
10 # append 在文件最后追加内容
11 f = open('test1', 'a', encoding='utf-8')
12 f.write('呀呼嘿')
13
14 # loop 按行读取文件
15 # high bigger 将文件作为迭代器 读一行打印一行 内存中只缓存一行
16 f = open('test', 'r', encoding='utf-8')
17 count = 0
18 for l in f:
19 if count == 9:
20 print('----------')
21 count += 1
22 continue
23 print(l.strip())
24 count += 1
25
26 # low loop 将文件内容全部读取至内存,效率低
27
28 f = open('Sonnet', 'r', encoding='utf-8')
29 for index, line in enumerate(f.readlines()):
30 if index == 9:
31 print('------------')
32 continue
33 print(line.strip())文件的函数
1 f = open('test', 'r', encoding='utf-8') # 文件句柄 读模式打开文件
2 print(f.tell()) # 获取当前光标位置
3 print(f.readline())
4 print(f.readline())
5 print(f.tell())
6 print(f.readline())
7 f.seek(10) # 跳转光标到第10个字符
8 print(f.readline())
9 print(f.encoding) # 获取文件编码
10 print(f.fileno()) # i don't know what it is
11 print(f.isatty()) # 判断文件是否是tty终端
12 print(f.readable()) # 判断文件是否是可读
13 print(f.writable()) # 判断文件是否是可写
14 print(f.seekable()) # 判断文件是否是可跳转光标 (tty不可跳转
15 f.flush() # 当用写模式打开文件时 并不是写一句系统就会调用一次io 若需要及时刷新硬盘中的文件内容 可以调用该函数
16 f.close() # 关闭文件
17 print(f.closed) # 判断文件是否关闭文件的修改***
1 # 文件的修改 直接修改文件本身比较困难 可以将修改写入另一个文件中 如有需求可以再写回文件本身
2 f = open('test', 'r', encoding='utf-8')
3 f_new = open('test.bak', 'w', encoding='utf-8')
4
5 for line in f:
6 if '我曾千万次梦见' in line:
7 line = line.replace('我曾千万次梦见', '我不想千万次梦见')
8 f_new.writelines(line)
9
10 f.close()
11 f_new.close()一个进度条实例 用于理解flush函数的机制 该实例可以实现进度条效果
1 import sys
2 import time
3
4 f = open('Sonnet1', 'w', encoding='utf-8') # 文件句柄 写模式打开文件 会新建一个文件 若同名文件存在 则直接覆盖
5 for i in range(10):
6 sys.stdout.write('#')
7 sys.stdout.flush()
8 time.sleep(0.2)字符编码转换
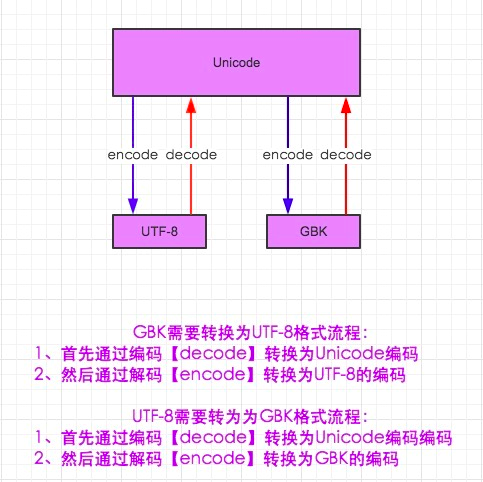
字符编码转换最重要的一点就是,切记unicode是编码之间的中转站,若unicode不是目标编码或者原始编码,那么任何两个编码相互转换都需要经过unicode(见下图)。
需要注意的是,python的默认编码是ASCII,python3的默认编码是unicode。
在python3中encode,在转码的同时还会把string变成bytes类型,decode在解码的同时还会把bytes变回string。
函数
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
函数能提高应用的模块性,和代码的重复利用率。python提供了许多内建函数(如print());也可以自己创建函数,即用户自定义函数。
定义一个有自己想要功能的函数,需要遵循以下规则:
函数代码块以 def 关键词开头,后接函数标识符名称和圆括号 ()。
任何传入参数和自变量必须放在圆括号中间,圆括号之间可以用于定义参数。
函数的第一行语句可以选择性地使用文档字符串——用于存放函数说明。
函数内容以冒号起始,并且缩进。
return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
!函数的参数、变量作用域、递归、高阶函数待补充
原文链接:https://www.cnblogs.com/summerj/p/10157085.html
原文作者:薛定花
点击查看更多内容
为 TA 点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中




感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦