
承接上文,解决普通链表查找的问题。首先分析问题的瓶颈,对于查找,自然是从头开始顺序查找到尾部,那么怎么才能更快查找到目标元素呢?将链表中的元素排序可以加速查找过程,但仍需要顺序查找。因此,链表最好允许跳过某些节点,以避免顺序处理。基于以上思路,提出跳跃链表的概念。跳跃链表是有序链表的一个有趣变种,可以进行非顺序查找,算法复杂度是O(lgn),相比于O(n)下降了一个量级。
首先使用自然语言概述跳跃链表。假设我们已有N个元素组成的有序单向链表,从中取出n1个元素组成新的单向链表,我们称之为二层链表,然后从二层链表中继续取出n2个元素组成三层链表,最后以此循环,可以有m层链表,m随意定义。这就是跳跃链表。就像盖高楼一样,普通链表只有一层,查找某个元素只能从头到尾,但是如果我们组织多层链表,就可以从高层到低层逐层查找,在这个过程中可以跳过很多元素,达到快速查找的目的。
下面是数学定义:
位于2^(k-1)*i的节点指向位于2^(k-1)*(i+1)的节点,约束条件:i>=1,1<=k<=lgn,lgn向下取整
跳跃链表:

这意味着第2个节点指向前面距离2个单位的节点,第4个节点指向前面距离4个单位的节点,以此类推。为此,要在链表中包含不同数目的指针:半数节点只有一个指针,1/4节点有两个指针,1/8节点有3个指针,以此类推。
概述下查找的逻辑:
假设查找元素el,应该从最高层上的指针开始,找到该元素就成功的结束查找。如果到达该链表的末尾,或者遇到大于元素el的某个元素key,就从包含key的那个节点的前一个节点重新开始查找,但是这次查找是从比前面低一层的指针开始的。直到找到el,或者沿着第一层的指针到达链表的末尾,或者找到一个大于el的元素,查找才会停止。
举个例子,比如在上面的跳跃链表中查找5,那么首先尝试的是第四层,这一层第一个节点是8,查找不成功,接着回退8节点的上一个节点。找到root指针,查找root第3层,首先找到4,然后找到8,查找不成功,回退8节点的上一个节点。找到节点4,查找节点4第2层,首先找到6,查找不成功,回退6节点的上一个节点。找到4节点,查找节点4第1层,首先找到5,查找成功。
动态图如下:

跳跃链表的查找复杂度只有O(lgn),这是很不错的效率了,但是链表的设计使得插入和删除效率很低。为了插入一个新的元素,必须重新构建新节点之后的所有节点,这当然是不能容忍的。为了保持跳跃链表在查找方面的优点,同时避免在插入和删除节点时重新构造链表,我们可以放弃对不同层上节点的位置要求,仅保留不同层上节点的数目要求即可。通过计算可以知道不同层级之间节点数目比例如下:
假设层级为n,那么从n层到1层的节点数目比例为:2^0 : 2^1 : ... : 2^(n-1)
比如上面跳跃链表是4层,那么比例就是1:2:4:8。这里有一点需要注意,因为我们放弃了位置要求,那么链表层级是可以随意指定的,一般是4层,即使节点数目有10000个,只要层级之间节点数目比例保持不变,就不会影响查找效率。
使用上述方法,添加和删除的算法复杂度也保持在O(lgn),这是因为添加和删除也依赖查找,跳跃链表是顺序表,添加或删除时首先依赖查找确定节点位置,才能执行后续操作。
添加的操作就不多说了,逻辑上和普通链表差不多,无非是普通链表只是插入一层,而跳跃链表插入首先确定新插入节点的层级m(可以使用随机数确定,保持层级节点比例即可),然后将节点插入到每一层链表即可。
总结:
与更高级的数据结构相比,例如自适应树或者AVL树,跳跃链表的效率相当不错,因此,用跳跃链表来代替这些数据结构是可行的的。
自组织链表
链表的数据结构探讨已经差不多了,事实上,我们上述探讨的是链表的静态结构,研究的是基于已经组织好的链表的算法。我们还可以使用某种方法动态地组织链表,从而提高查找效率。通过动态方式组织的链表,可以称之为自组织链表。
这里给出4种动态组织链表的方式:
前移法。在找到需要的元素之后,把它放到链表的开头。
换位法。在找到需要的元素之后,只要它不在链表的开头,就与其前驱交换位置。
计数法。根据元素被访问的次数,对链表进行排序。
排序法。根据节点元素的属性,对链表进行排序。
我们通过一组表格来说明这4中方法:
假设现在有一个空链表以及一段数据流-ACBCDADACACCEE,我们通过上面4中方式,将数据流动态的组织到链表中。
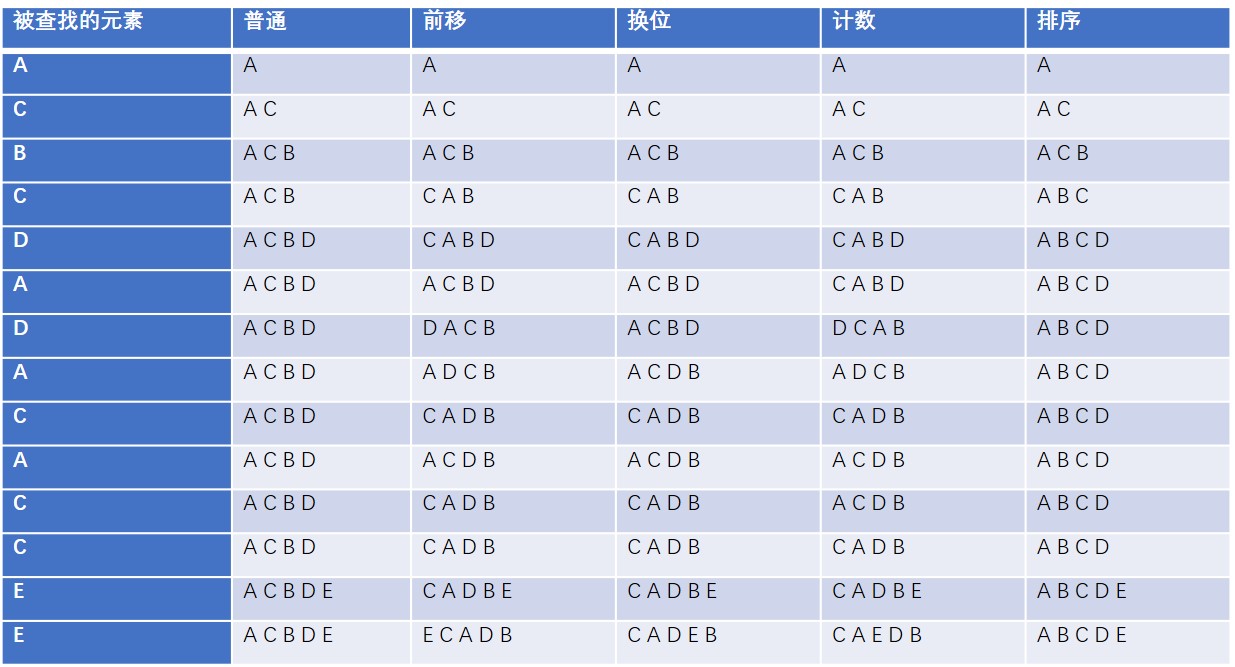
为了测试这些方法的效率,可以将实际比较次数与可能的最大比较次数相对比。可能的最大比较次数是将链表在处理每个元素时的长度相加得到的。比如在上面表格中,数据体包含14个字母,在处理每个字母前,将链表的长度记录下来,其结果是0+1+2+3+3+4+4+4+4+4+4+4+4+5=46,这个总长度用来与所做的比较次数相对比。对于所有的方法来说,这个总长度是相同的,而且是最大的,那么就可以用来做对比了。
我们通过将不同文本中的单词组织成链表来测试上述方法的查找效率:
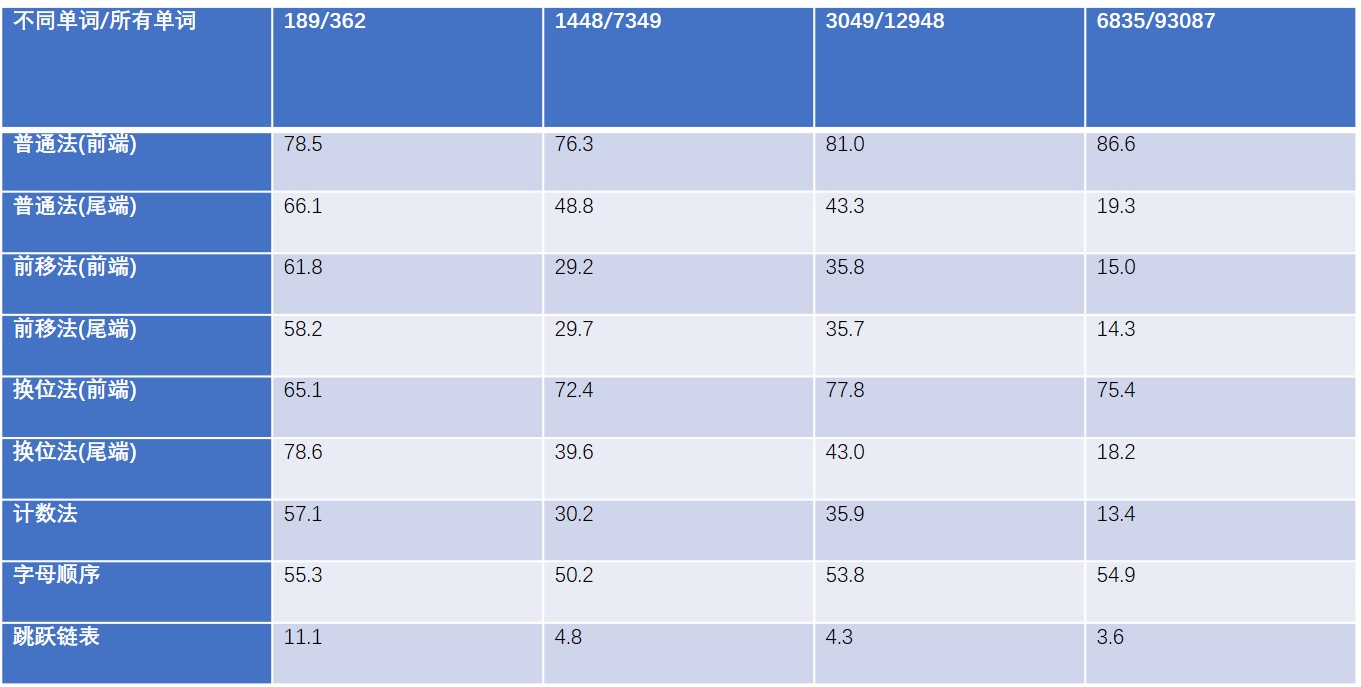
我们将普通法、前移法、换位法通过两种不同的插入方式进行比较。通过以上数据总结出以下特征:
随着数据量的提升,所有方法的效率都有所提高
在尾部插入数据总是比在前端插入数据高效
跳跃链表>计数法>前移法>换位法
可以看到跳跃链表的查询效率相比于其他方法有着巨大的优势,紧随其后的是计数法,然后是前移法以及换位法都比字母顺序以及普通法表现优异。
并不是说查询效率越高的就越好,跳跃链表的组织方式相比于其他方法要复杂很多。事实上,计数法在软件开发中使用的很多,我们平常见到的‘热数据’本质上属于计数法。这些方法组织链表的方式简单、高效,往往会得到大量应用。
这里有一点需要注意,在上述表格中只包含了数据的比较,没有包含执行这些方法所需要的其他操作,如果包含这些信息,这些方法之间的差异可能就不会那么显著了。
这里简单总结一下,对于中等数量的数据,使用链表就足够了。随着数据量的增长和访问频率的提高需要使用更复杂的方法和数据结构。
到此为止,链表的探讨就结束了,更多的收获就需要在实践中摸索了。
共同学习,写下你的评论
评论加载中...
作者其他优质文章


