
写在前面
今天要抓取的网站为 https://500px.me/ ,这是一个摄影社区,在一个摄影社区里面本来应该爬取的是图片信息,可是我发现好像也没啥有意思的,忽然觉得爬取一下这个网站的摄影师更好玩一些,所以就有了这篇文章的由来。

基于上面的目的,我找了了一个不错的页面 https://500px.me/community/search/user
不过细细分析之后,发现这个页面并不能抓取到尽可能多的用户,因为下拉一段时间,就不能继续了,十分糟心,难道我止步于此了么,显然不可能的,一番的努力之后(大概废了1分钟吧),我找到了突破口,任意打开一个用户的个人中心页,就是点击上述链接的任意用户头像,出现如下操作。
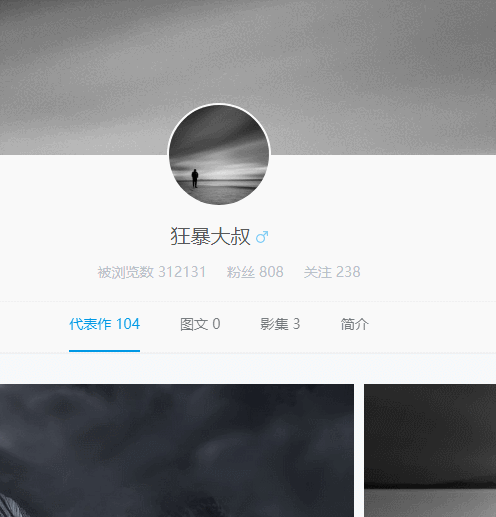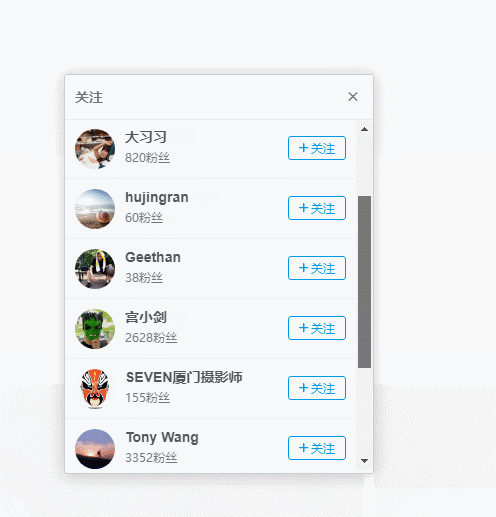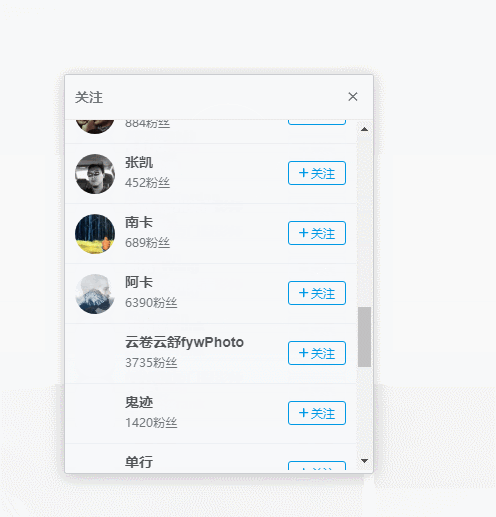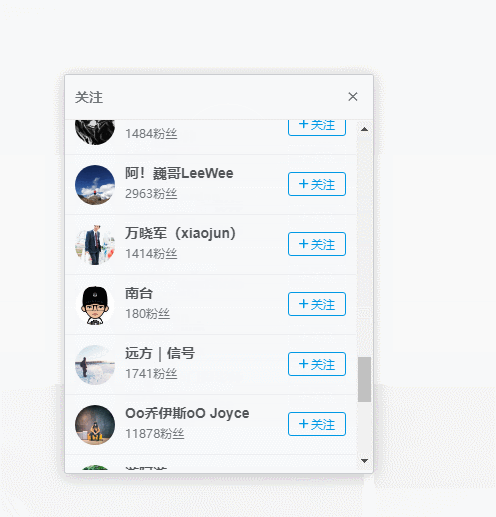
用户个人中心页面,竟然有关注列表唉~~,nice啊,这个好趴啊,F12分析一下。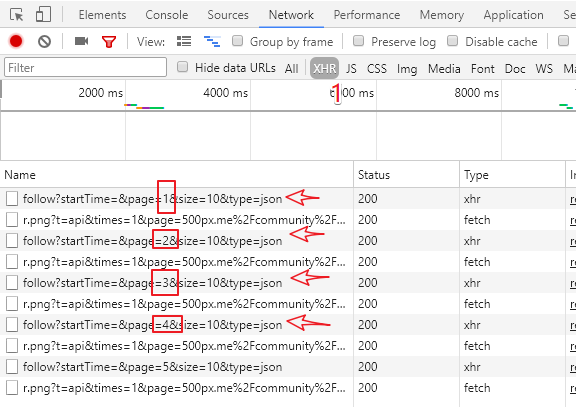
哒哒哒,数据得到了。
URL是 https://500px.me/community/res/relation/4f7fe110d4e0b8a1fae0632b2358c8898/follow?startTime=&page=1&size=10&type=json
参数分别如下,实际测试发现size可以设置为100
https://500px.me/community/res/relation/{用户ID}/follow?startTime=&page={页码}&size={每页数据}&type=json那么我们只需要这么做就可以了
获取关注总数
关注总数除以100,循环得到所有的关注者(这个地方为什么用关注,不用粉丝,是因为被关注的人更加有价值)
明确我们的目标之后,就可以开始写代码了。
撸代码
基本操作,获取网络请求,之后解析页面,取得关注总数。
用户的起始,我选择的id是5769e51a04209a9b9b6a8c1e656ff9566,你可以随机选择一个,只要他有关注名单,就可以。
导入模块,这篇博客,用到了redis和mongo,所以相关的基础知识,我建议你提前准备一下,否则看起来吃力。
import requestsimport threadingfrom redis import StrictRedisimport pymongo#########mongo部分#########################DATABASE_IP = '127.0.0.1'DATABASE_PORT = 27017DATABASE_NAME = 'sun'client = pymongo.MongoClient(DATABASE_IP,DATABASE_PORT)
db = client.sun
db.authenticate("dba", "dba")
collection = db.px500 # 准备插入数据#########mongo部分##################################redis部分#########################redis = StrictRedis(host="localhost",port=6379,db=1,decode_responses=True)#########redis部分##################################全局参数部分#########################START_URL = "https://500px.me/community/v2/user/indexInfo?queriedUserId={}" # 入口链接COMMENT = "https://500px.me/community/res/relation/{}/follow?startTime=&page={}&size=100&type=json"HEADERS = { "Accept":"application/json", "User-Agent":"你自己去找找可用的就行", "X-Requested-With":"XMLHttpRequest"}
need_crawlids = [] # 待爬取的useridlock = threading.Lock() # 线程锁#########全局参数部分#########################def get_followee():
try:
res = requests.get(START_URL.format("5769e51a04209a9b9b6a8c1e656ff9566"),
headers=HEADERS,timeout=3)
data = res.json() if data:
totle = int(data["data"]["userFolloweeCount"]) # 返回关注数
userid = data["data"]["id"] # 返回用户ID
return { "userid":userid, "totle":totle
} # 返回总数据
except Exception as e:
print("数据获取错误")
print(e)if __name__ == '__main__':
start = get_followee() # 获取入口
need_crawlids.append(start)上面代码中有一个非常重要的逻辑,就是为什么要先匹配种子地址的【关注数】和【用户ID】,这两个值是为了拼接下面的URLhttps://500px.me/community/res/relation/{}/follow?startTime=&page={}&size=100&type=json
经过分析,你已经知道,这个地方第一个参数是用户id,第二个参数是页码page,page需要通过关注总数除以100得到。不会算的,好好在纸上写写吧~
我们可以通过一个方法,获取到了种子用户的关注列表,以此继续爬取下去,完善生产者代码。关键代码都进行了注释标注。
思路如下:
死循环不断获取
need_crawlids变量中的用户,然后获取该用户的关注者列表。爬取到的信息,写入
redis方便验证重复,快速存储。
class Product(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
self._headers = HEADERS def get_follows(self,userid,totle):
try:
res = requests.get(COMMENT.format(userid,totle),headers=HEADERS,timeout=3)
data = res.json() if data: for item in data: yield { "userid":item["id"], "totle":item["userFolloweeCount"]
} except Exception as e:
print("错误信息")
print(e)
self.get_follows(userid,totle) # 出错之后,重新调用
def run(self):
while 1: global need_crawlids # 调用全局等待爬取的内容
if lock.acquire(): if len(need_crawlids)==0: # 如果为0,无法进入循环
continue
data = need_crawlids[0] # 取得第一个
del need_crawlids[0] # 使用完删除
lock.release() if data["totle"] == 0: continue
for page in range(1,data["totle"]//100+2): for i in self.get_follows(data["userid"],page): if lock.acquire():
need_crawlids.append(i) # 新获取到的,追加到等待爬取的列表里面
lock.release()
self.save_redis(i) # 存储到redis里面
def save_redis(self,data):
redis.setnx(data["userid"],data["totle"]) #print(data,"插入成功")由于500px无反爬虫,所以运行起来速度也是飞快了,一会就爬取了大量的数据,目测大概40000多人,由于咱是写教程的,我停止了爬取。

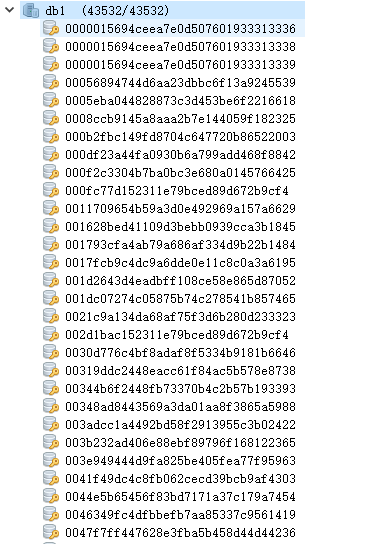
这些数据不能就在redis里面趴着,我们要用它获取用户的所有信息,那么先找到用户信息接口,其实在上面已经使用了一次https://500px.me/community/v2/user/indexInfo?queriedUserId={} 后面的queriedUserId对应的是用户id,只需要从刚才的数据里面获取redis的key就可以了,开始编写消费者代码吧,我开启了5个线程抓取。
class Consumer(threading.Thread): def __init__(self): threading.Thread.__init__(self) def run(self): while 1: key = redis.randomkey() # 随机获取一个key if key: # 删除获取到的key redis.delete(key) self.get_info(key) def get_info(self,key): try: res = requests.get(START_URL.format(key),headers=HEADERS,timeout=3) data = res.json() if data['status'] == "200": collection.insert(data["data"]) # 插入到mongodb中 except Exception as e: print(e) returnif __name__ == '__main__': start = get_followee() # 获取入口 need_crawlids.append(start) p = Product() p.start() for i in range(1,5): c = Consumer() c.start()
代码没有特别需要注意的,可以说非常简单了,关于redis使用也不多。
redis.randomkey() # 随机获取一个keyredis.delete(key) # 删除key
(⊙o⊙)…经过几分钟的等待之后,大量的用户信息就来到了我的本地。

共同学习,写下你的评论
评论加载中...
作者其他优质文章



