
Spark作业性能调优 —— 为什么慢的总是“你”
背景
业务高峰期,准实时(mini batch)数据处理作业的运行时间现有一些延迟,为了保证作业的SLA,必须及时对作业运行状况进行排查。
异常原因排查
作业层面
平台采用的是spark on yarn的部署方案,故直接通过spark作业的application master url进入spark application ui;
通过spark ui 查找运行变慢的stage;
进入对应的stage之后,通过Summary Metrics可以看出task运行时间差异很大,从task的Input Size来看,输入数据本身并不存在倾斜; 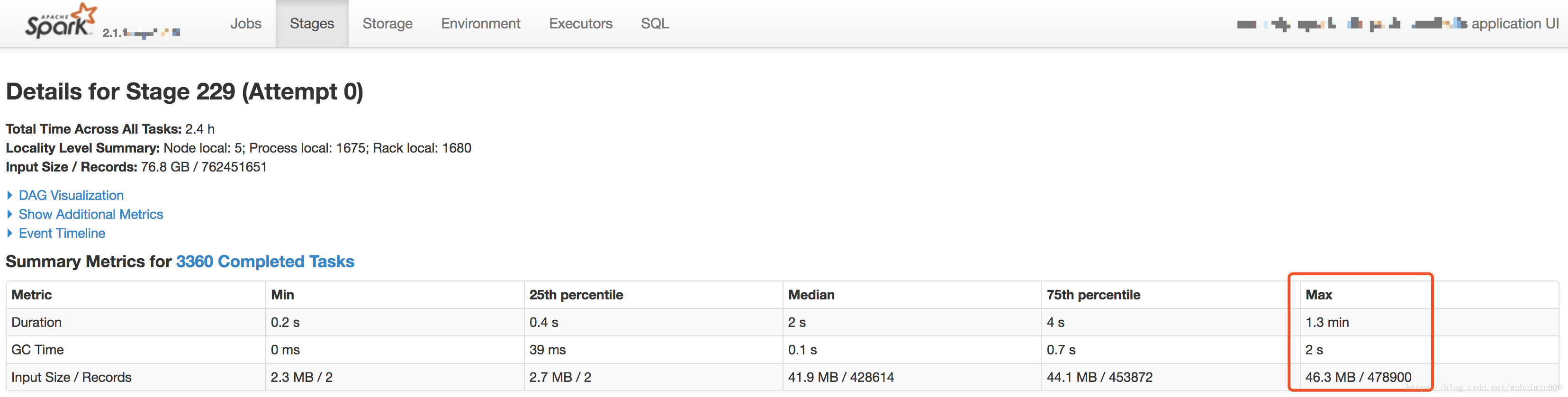
接下来,我们要重点分析“拖后腿”的task, 分析它们究竟遭遇了什么;
通过对Stage 229中的task按Duration排序,找到运行慢的tasks;通过排序结果我们可以很容易看出,慢的task运行的executor全部集中在224这台服务器上; 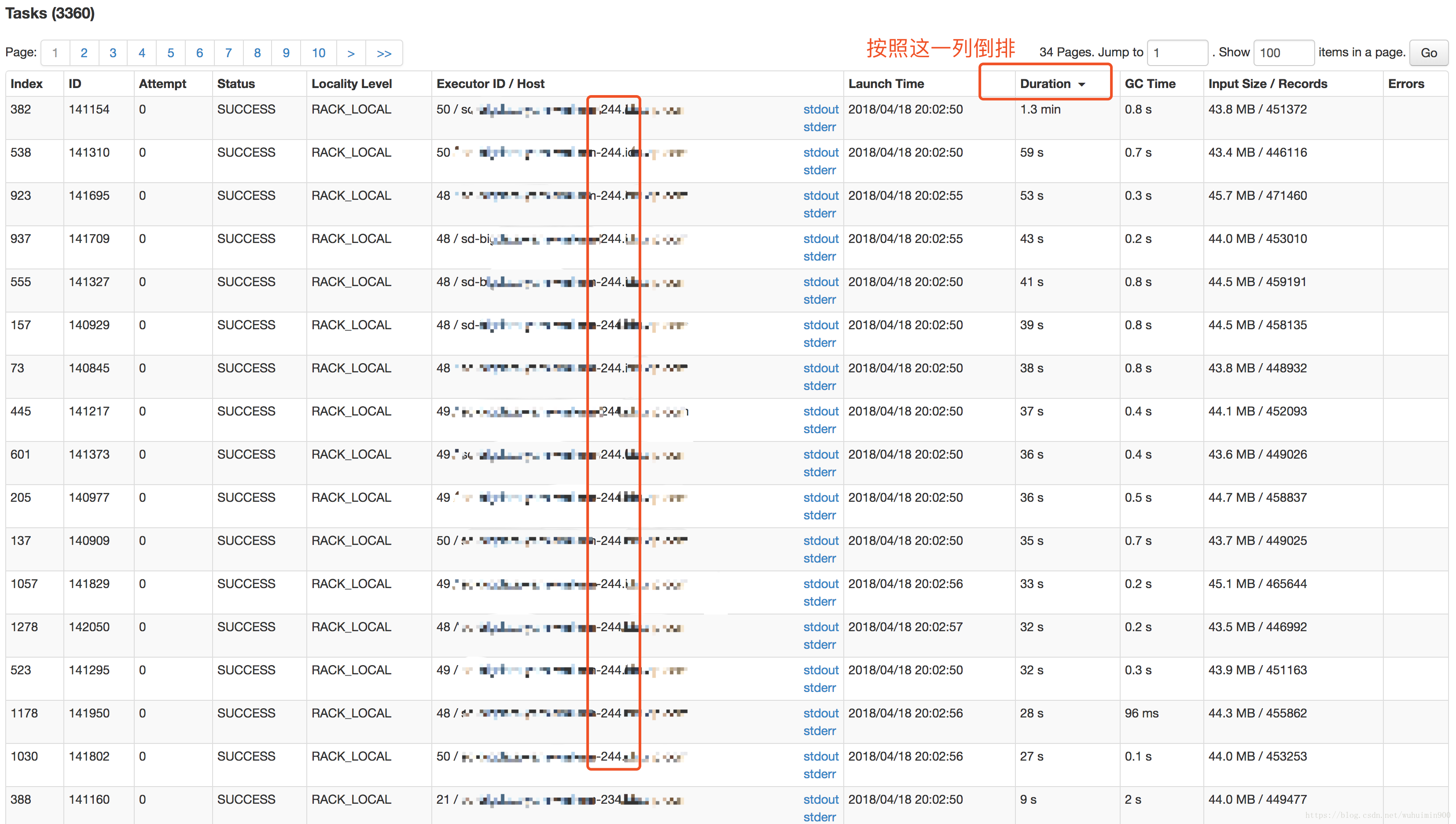
至此,我们初步结论是问题出现在224这台服务器上。
服务器层面
确认过是服务器的问题后,接下来就借助open-falcon查看机器的健康状况;
首先排查基本指标:
load
load.1min
load.5min
load 15min
cpu.idle
cpu.iowait
disk.io.util
network
net.if.out.errors
net.if.in.errors
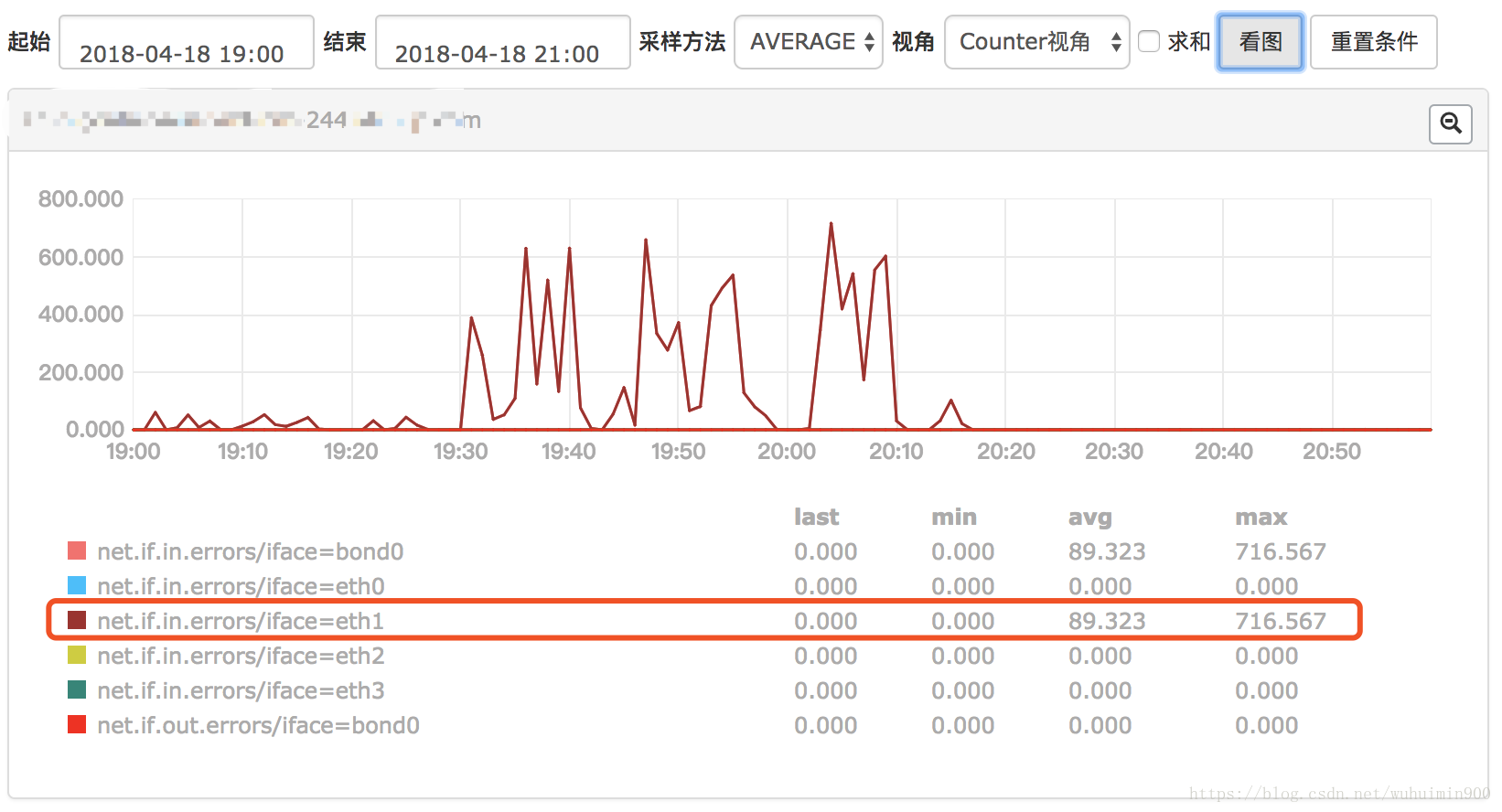
到这里基本上已经定位出了,是由于机器的eth1网卡异常导致这台机器上的task运行变慢;
由于机器的配置是4块网卡做bond, 所以分配到该台服务器上的作业并不会报错,只是事先速度变慢。
解决方法
临时下线掉这台异常服务器上的NodeManager
${HADOOP_HOME}/bin/yarn-daemon.sh stop nodemanager1下线后,作业运行时间恢复正常。
结论
在Hadoop等分布环境中底层服务器的健康状况对Spark、MR等分布式作业的运行效率有着举足轻重的影响,因此完善的底层服务器的监控,对于保障数据平台的SLA有着深远的意义。
致谢
感谢平台运维同事协助定位问题。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



