
一. 提出背景
目标检测在图像处理领域有着非常大的占比,过去两年,深度学习在Detection的持续发力,为这个领域带来了变革式的发展:一方面,从 RCNN 到 Fast RCNN,再到 Faster RCNN,不断刷新 mAP;另一方面,SSD、YOLO 则是将性能提高到一个非常高的帧率。
对于视频来讲,相邻帧目标之间存在 明显的上下文关系,这种关系在技术上的表现就是 Tracking,研究过跟踪的童鞋都应该知道 经典算法 TLD,通过 Tracking-Learning-Detection 学习目标的帧间变换,并进行 Location。
基于视频的目标检测 要解决的是同样的问题,因为 变形、遮挡、运动Blur 等因素导致目标 在 中间帧无法检测到(Appearence 发生很大变化),可以从下图看到,基于 still-image 的方法在某些帧的检测置信度很低。
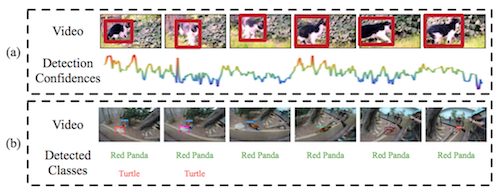
VID(object-detection-from-video) 在2015年已成为一个 Challenge 方向,主要思路是结合帧间的 Context 信息、Tracking信息,接下来我们要讲的算法 TCNN。
论文名称: T-CNN: Tubelets with Convolutional Neural Networks for Object Detection from Videos
二. T-CNN
论文下载:【arvix】
代码下载:【Github】
闲话不说,直接给出框架图:
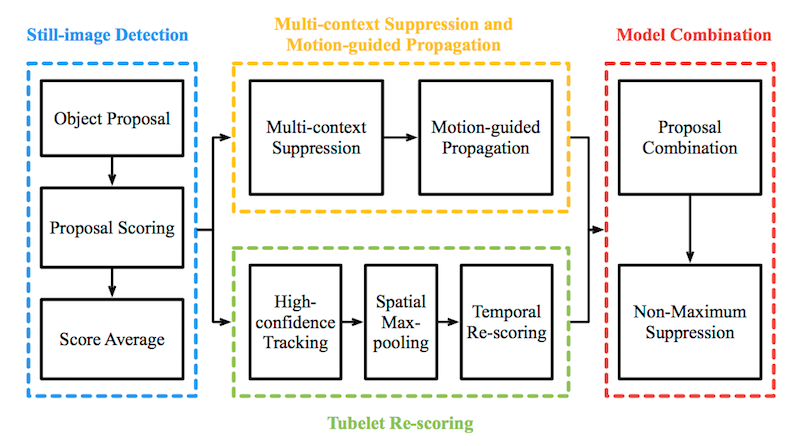
算法分为四个步骤:
1)静态图片检测
基于 Still-image 的检测方法,里面用到了 DeepID-Net(基于RCNN的改进)和 CRAFT(Faster RCNN的改进),没听过的童鞋应该也没有多大必要学,理解为港中文的小伙伴愿意自恋的用自家的东西,而且还两个都用 求个Average,也是醉了。
用的时候直接追求精度的话用 Faster就可以了,需要实时应用还是选择 SSD或YOLO,很多基于经典方法的所谓改进其事可以忽略了。
2)上下文抑制 和 运动传播
上下文抑制(Multi-Context Suppression)用来降低误检(False Positive),即降低置信度(Score)比较低的 Detection。
可以看到,对应图片中的主体部分 Keep 的比较好,其余 Low-Confidence 部分被抑制。
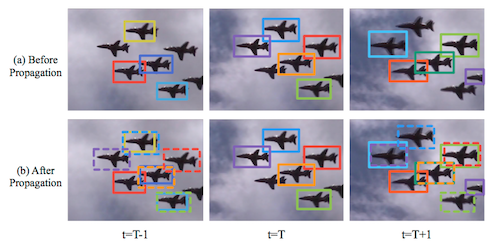
运动传播(Motion-guided propagation)用来降低漏检(False Negtive),通过相邻帧之间的运动信息,将当前帧的 Location和置信度 传递给相邻帧。
作者在 Paper 里面用到了 Location区域对应的光流向量来进行判断,来看效果:
PS:根据作者对光流法的使用,受背景影响很大,一般达不到上图的效果,大家理解这个意思就好了。
3)Tubelet Re-Scoring
基于 Tracking 的结果重新计算得分,分为三个子步骤:
a)High Confidence Tracking
高质量的跟踪是前提,里面有个假设条件,如果跟踪目标的变化导致置信度低于某个阈值时(比如0.1),跟踪停止,这是避免跟踪错误的一种方法。
b)Spatial Max-pooing
空间最大值采样,是根据 Tracking结果,对每个Location在其周围进行 Detection 的目标比对,IOU>0.5 被重新定义为目标位置。
这种方法是将更信任 Detetcion的一种方法,可以有效矫正 目标的Location位置。
c)Tubelet classification and rescoring
根据 Tracking 目标串的 Top-k 进行分类,并映射到 Positive[0.5,1]和 Negative [0,0.5],可以有效增加正负样本的 Margin。
4)模型合并
包括两部分,建议框合并(Proposal Combination)和 非最大值抑制(Non-Maximum Suppression)。
建议框合并的方法有很多,按照置信度,直接都加起来等等,NMS(非最大值抑制)用来消除重复边框,这里不再展开。

> 论文实现效果

关于这篇论文,读完之后发现水分很大,拼凑的地方比较多,只为了发篇论文,并无亮点,如果我是评委,不会给过的。
饶是如此,VID的第一篇文章,还是把它介绍出来,了解其思想即可不必深究,本人的观点是,在 Real-Time 系统之中基于Detection & Tracking的方法结合就够了,只用到前帧信息(后面帧信息不建议用)。
三. Deep Feature Flow
论文下载:【arvix】
代码下载:【Github】
MSRA 出品,突然感慨这是没有了 孙剑、何凯明的 MSRA,虽然吹的依旧火热,不过与 FAIR、Google Brain差距也是越拉越大。
跑题了,这篇文章思路比较简单,受 Detection 效率的制约,在处理实时的视频应用上,结合光流的思路,实现特征图的帧间传播和复用。
算法要点描述为:
1)在关键帧(Key Frame)进行特征图提取
这一步是比较耗时的,因此是间隔进行的,至于是使用 Faster RCNN 还是 RFCN,网络是 ResNet-101 还是 Inception,都OK。
这里要说明,作者只是间隔固定时间做一次,没有考虑 遮挡、变形、Motion Blur 等因素。
so 和上一篇一样,我们只是简单看一下思路即可。
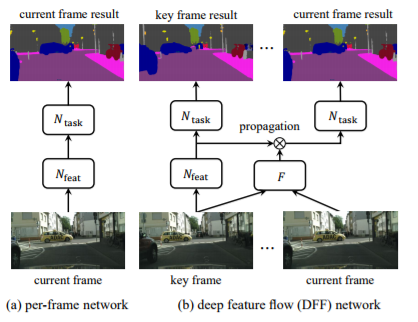
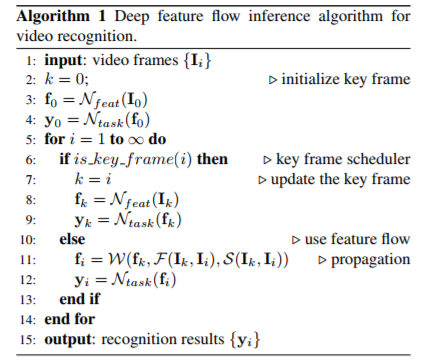
2)帧间传播
通过下面这幅图来看,作者将 任务分成两个: 特征提取 N(feat) 和 分类&分割 N(task)。
耗时的特征提取 N(feat)只在关键帧 Work,非关键帧的 Feature 通过传播(Propagation)得到。
F是通过两个 Raw Frame得到的 Flow信息,作用于前面的 Feature Map,得到当前帧 特征图,并用于计算 N(task)。
3)特征图映射
特征图映射是 本文的最关键部分,因为高层特征和底层特征的差别,流估计的误差会使得特征形变不准确,先来看映射效果:
对应二维流场 M (i->k),对于 p 的映射描述为变化量 δ p,即 p -> p + δ p:
特征的形变通过双线性插值实现:
其中c为特征图 f 的通道,G为双线性插值的内核,可以将 G(2D) 分为两个一维内核:
文中定义了 “尺度场” 的概念,记为两帧之间的比例函数:
基于此,将特征传播函数定义为:
其中 W 通过公式1 进行计算,并乘以缩放系数S。
4)端到端训练
为了让算法达到比较好的效果,端到端(end-to-end)的训练必不可少,好处在于能够比较好的平衡误差,避免因为单独训练每一部分都挺好,结果却无法 Match 的情况,大多数 Deep Net 都会选择 end-to-end 的方法,也比较好理解。

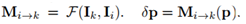
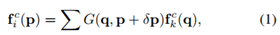
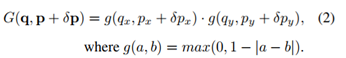
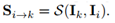
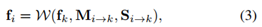
> 算法流程
共同学习,写下你的评论
评论加载中...
作者其他优质文章



