
推荐系统入门
本文从Improving Top-N Recommendation with Heterogeneous Loss 这篇论文的角度讲解如何入门推荐系统。适合推荐系统初学者入门。
这篇文章提出了一种 通过多个损失函数 结合来提升topN推荐的效率 的方法。发表在16年的IJCAI上,是来自天普大学的研究成果。

目录
我先介绍一下topN背景,再介绍一下与本文相关工作,最后推导出本文提出的创新方法。再通过实验观察这个方法的效率,最后将自己对本文的思考做一个总结。

Backgroud
Top N推荐就是以推荐列表的形式给用户推送信息。像 学术头条 对论文的推荐,虾米对音乐的推荐,网易云课堂对课程的推荐 都属于Top N推荐。
Relaxed works
Top-N推荐的一类主要方法为协同过滤,
协同过滤一般分为两大类:neighborhood-based 基于临近关系的 和 model-based 基于模型的。
neighborhood-based算法就像我们找同学给我们推荐资料。就是先帮我们找到兴趣相似的人,然后把这些人喜欢的东西推荐给我们。因为 只分析用户对用户的关系或者物品对物品的关系,所以运算非常快。
Model-based算法是指对 用户行为矩阵 进行矩阵分解 再 用模型来学习 已有的用户物品隐变量,用学习到的 低rank的用户矩阵、物品矩阵 相乘 来预测结果,典型算法有SVD, SVD++, ALS算法。因为采用了模型的方法预测了完整的用户物品矩阵,推荐的效果相对neighborhood-based较好。但是由于算法需要训练,运算时间大幅上涨。
SLIM算法结合了二者的优点,像neighborhood-based一样只对物品与物品之间相似度进行预测,又像model-based的方法一样通过训练得到了完整的用户物品矩阵,所以推荐的相对快,预测的结果也好。
现在作者把这些方法归为pointwise方法。什么是pointwise呢?这是源自从排序学习的一个概念。我们搜索的时候,搜索系统只按关键词的相关度进行排序然后给我们返回结果,就是pointwise方法。
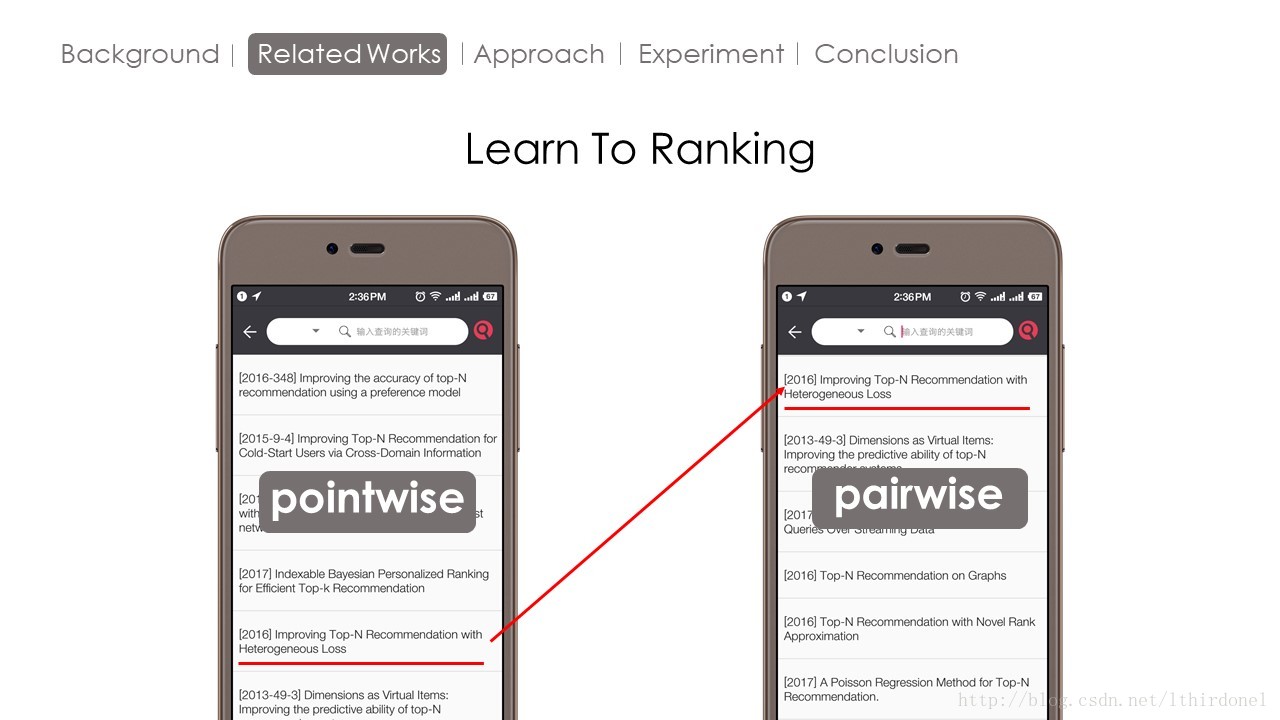
而pairwise不仅考虑相关度,还考虑不同文档之间的关系。
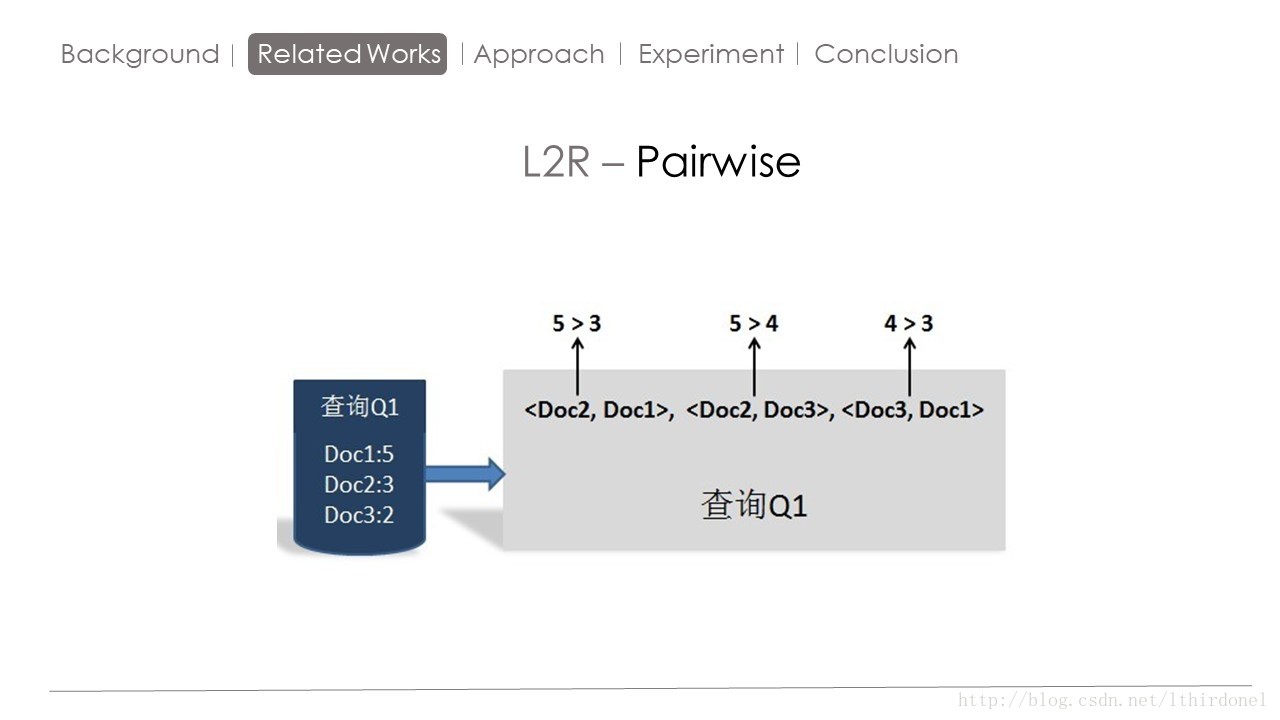
具体方法就是,Pairwise 将数据集根据评分(相关度) 转化为 偏序对 的形式,像图中的数据集Q1转换为偏序对变成了右图,
如果用户喜欢前者,那么这个偏序对的值便是1,喜欢后者便是-1,
这样就巧妙地将排序问题转化为 二分类问题 。便可以用SVM等方法实现。 这样 如果每一个文档对都能被正确分类,便会得到一个正确的排序。
下面这些论文都是结合了pairwise的思想来实现的top-N推荐算法。 
本文便是结合了pointwise类的方法和pairwise类的方法实现了一个创新的topn推荐算法。
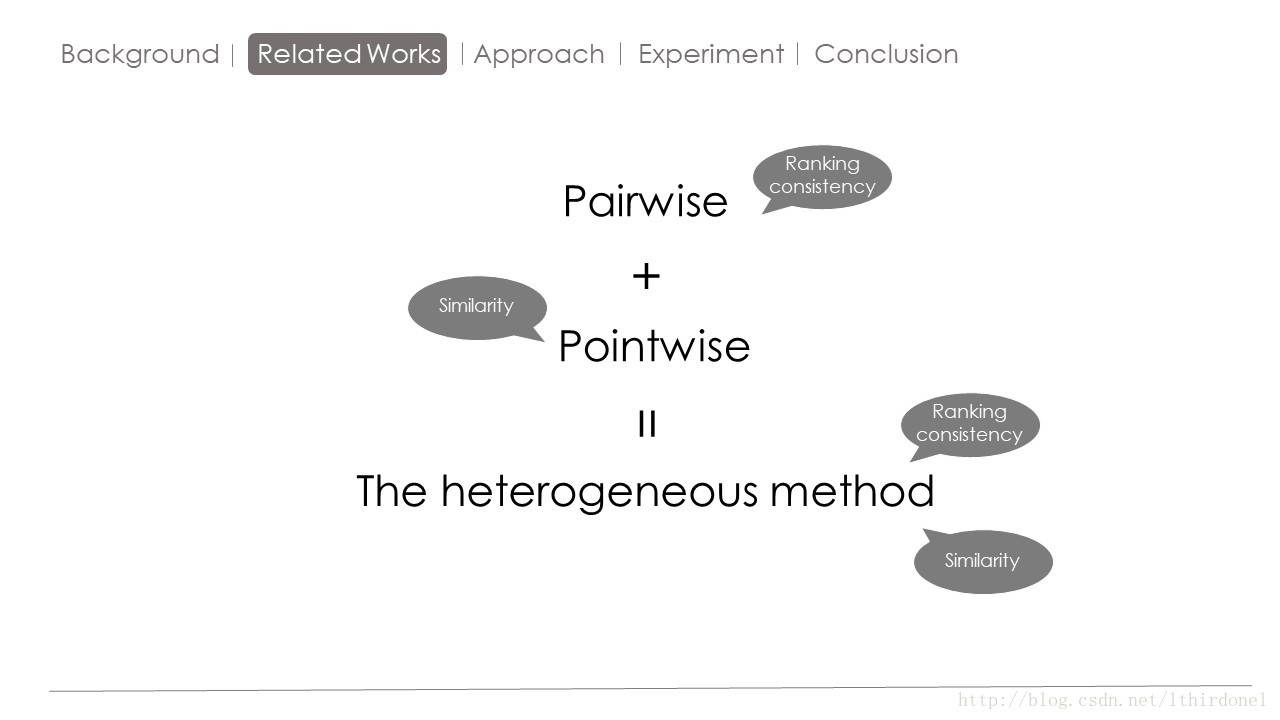
Pairwise是从不同物品之间关系方面进行预测,他的物品之间的排序关系预测较好。
Pointwise 是从物品与用户相似度关系方面进行的预测,他预测的物品与用户相似度较好
作者便想结合这两方面的思想提出一种异构的方法。
Approach
下面开始从具体的算法来观察一下。
首先介绍一下topN推荐算法的通用框架,X就是用户与物品的评分矩阵或者是用户物品因变量的矩阵,X hat是对用户物品矩阵重构矩阵,W是根据重构矩阵参数矩阵。L函数就是损失函数,R函数就是正则函数。通过带入不同的损失函数以及正则函数便出现了不同的TOPN推荐算法。

现在我们将重构矩阵用经典的UT矩阵表示,这也是SVD系列算法的精髓 : 找出两个rank远低于原矩阵的小矩阵,利用最小化 最小二乘法损失函数 就能够这个拟合出这个重构的推荐矩阵。 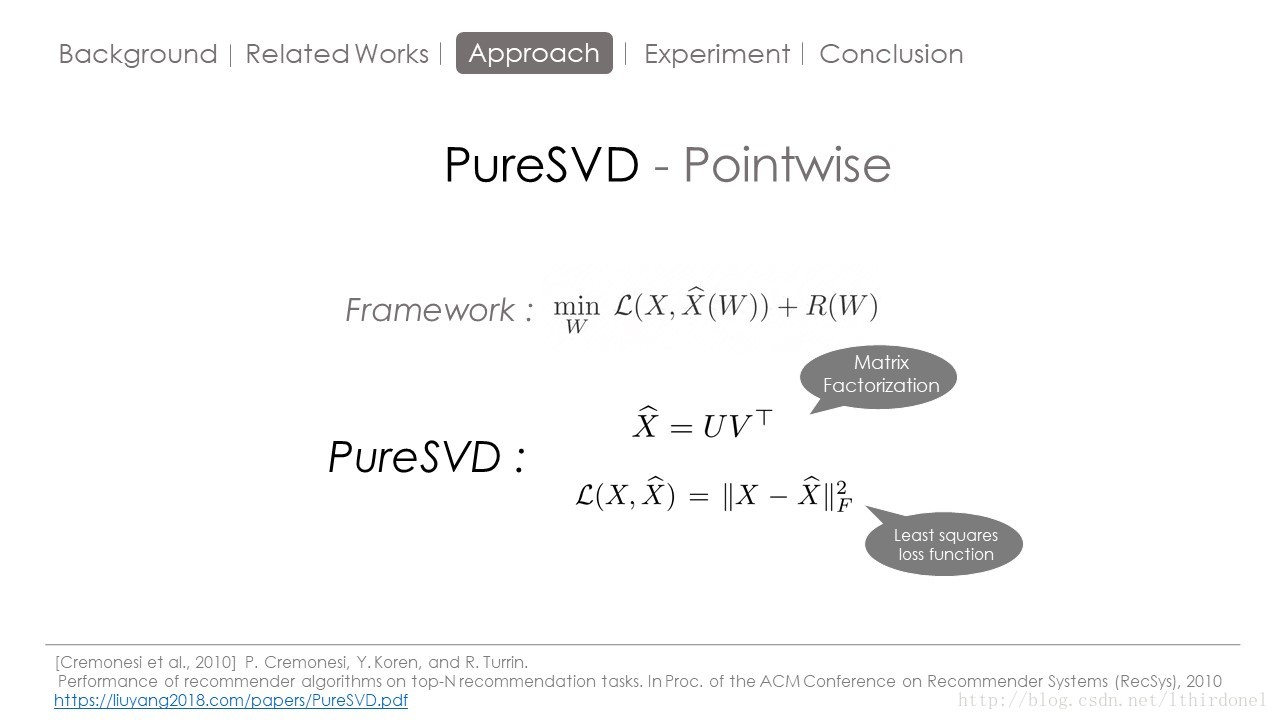
前面提到SLIM方法综合了两大类协同过滤算法优点,他的原因就这里。
SLIM将矩阵XW,W是物品间相似度的矩阵,也就是我们需要训练学习得到的权重矩阵
值得注意的是那两个约束条件,一个是 W 非负,这样我们只学习 item 之间的正相关关系。那么为什么 W 的对角线都要为 0 呢?
因为如果没有这个对角线限制,与 X相乘之后,为了减小误差函数,会倾向于只推荐它自己,所以我们要保证一个已知的行为得分不会用于预测他自己的计算。
然后利用最小二乘法损失函数以及防止过拟合的L1L2范式来组成目标函数,最小化这个目标函数就得到了W。
综上,SLIM利用用户物品行为之间的相似度来缩短训练时间(neighborhood-based),又利用学习训练过程提升了结果的精度(model-based),结合了两种主流协同过滤算法的优势。
PS:W矩阵存储问题很难解决。 
这里开始介绍一种Pairwise思想的方法。 将数据集处理成偏序对的方式,然后带入铰链损失函数,训练得到UV矩阵。
这里YijkX 是当用户喜欢j物品大于K物品时,为1,否则为-1 这样就保证了x(也就i物品与k物品相似度的差)始终为正,那么x(也就i物品与k物品相似度的差)只要大于1损失就为0.

但是AltSVM是一个非凸函数想要求解便很困难,我们将SLIM中X发(一个线性的重构函数)带入ALTSVM,这个X发 可以利用 已有的关系重构缺失的关系,这样就得到了下面这个凸的目标函数。
这种单纯的pairwise方法只是会提高预测矩阵和原始矩阵的一致性,并不一定比pointwise的精确度高。

因为用了X hat=XW,我们自然也可以用他的损失函数来弥补预测矩阵的缺失。 
下面是求解过程


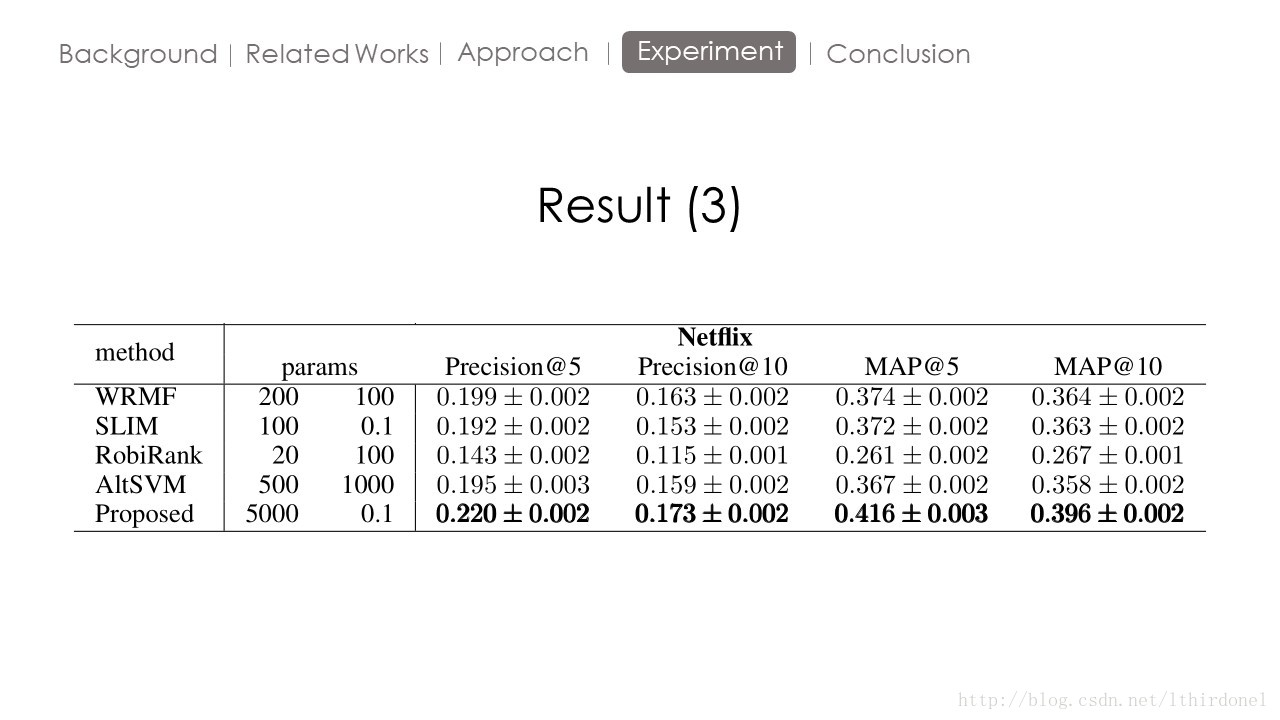
Experiment
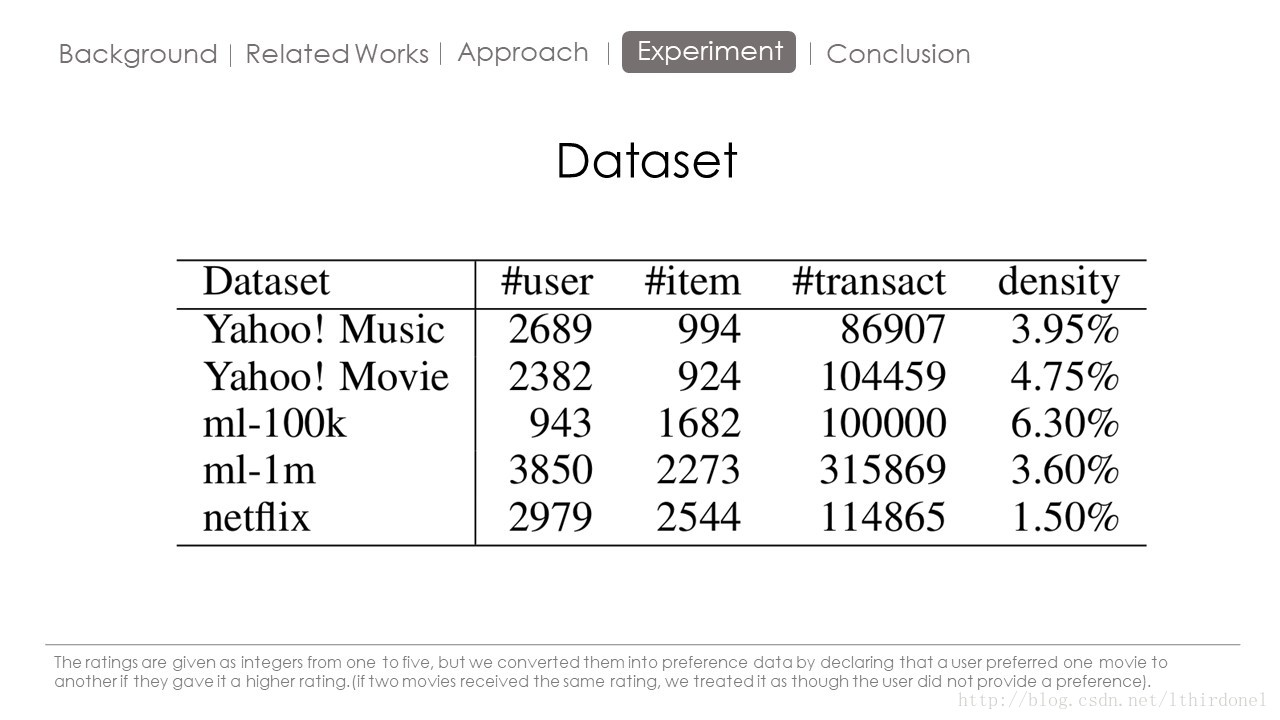
P@N
对单次搜索的结果中前5篇,如果有4篇为相关文档,则P@5 = 4/5 = 0.8 。
MAP:
假设有两个主题,主题1有4个相关网页,主题2有5个相关网页。
某系统对于主题1检索出4个相关网页,其rank分别为1, 2, 4, 7;对于主题2检索出3个相关网页,其rank分别为1,3,5。
对于主题1,平均准确率为(1/1+2/2+3/4+4/7)/4=0.83。对于主题2,平均准确率为(1/1+2/3+3/5+0+0)/5=0.45。则MAP= (0.83+0.45)/2=0.64。

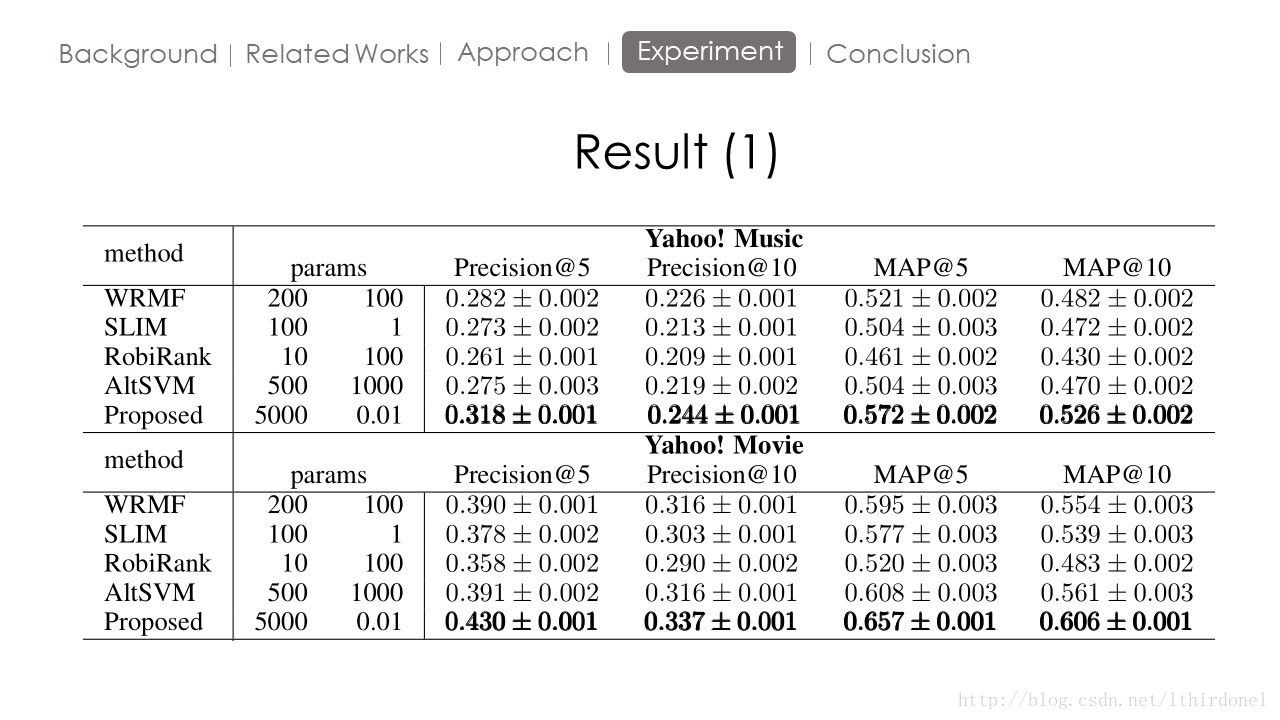
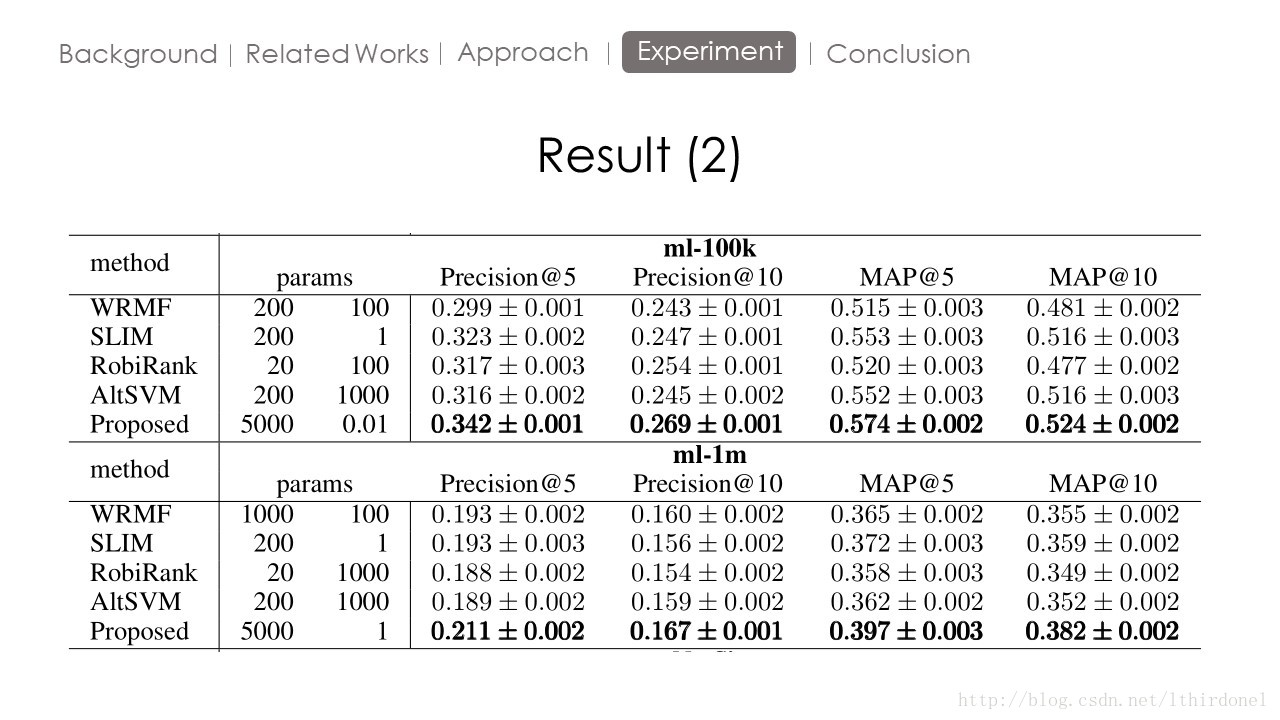
Conclusion

这篇论文的方法由于W矩阵的限制,无法用于大规模数据处理。但是对于入门推荐系统作用很大,谢谢观看。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



